 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervision and Learnable STRFs for Age, Emotion, and Country Prediction
Paper and Code
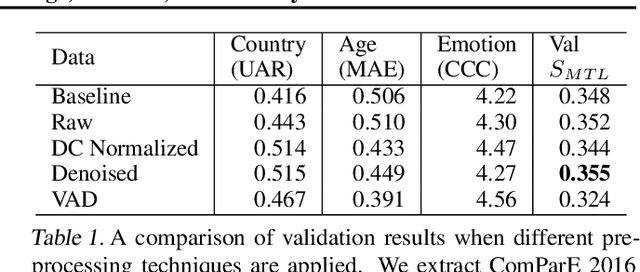
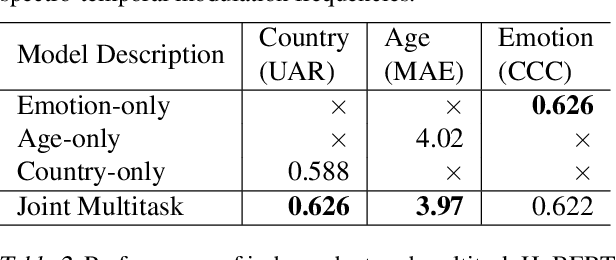
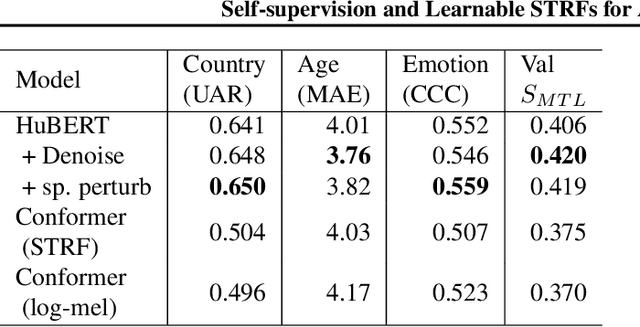
This work presents a multitask approach to the simultaneous estimation of age, country of origin, and emotion given vocal burst audio for the 2022 ICML Expressive Vocalizations Challenge ExVo-MultiTask track. The method of choice utilized a combination of spectro-temporal modulation and self-supervised features, followed by an encoder-decoder network organized in a multitask paradigm. We evaluate the complementarity between the tasks posed by examining independent task-specific and joint models, and explore the relative strengths of different feature sets. We also introduce a simple score fusion mechanism to leverage the complementarity of different feature sets for this task. We find that robust data preprocessing in conjunction with score fusion over spectro-temporal receptive field and HuBERT models achieved our best ExVo-MultiTask test score of 0.412.