 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech vs. Transcript: Does It Matter for Human Annotators in Speech Summarization?
Aug 12, 2024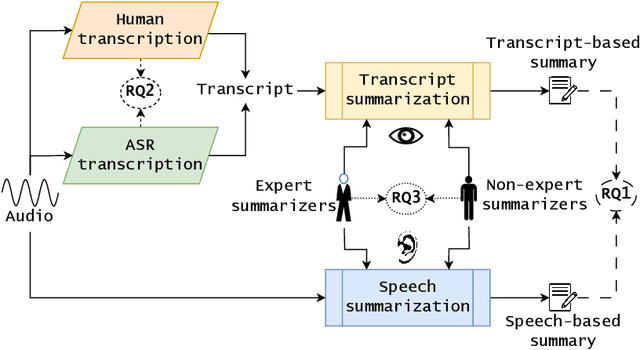
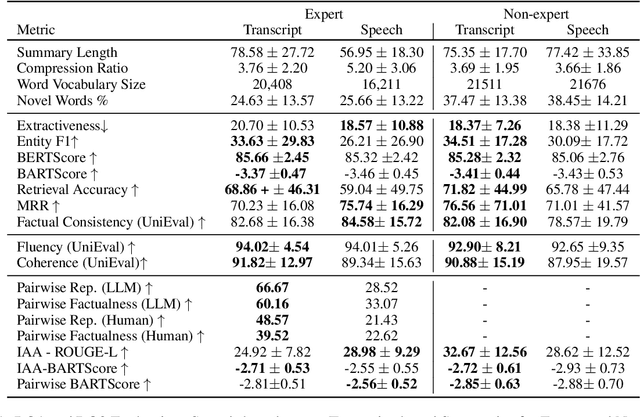

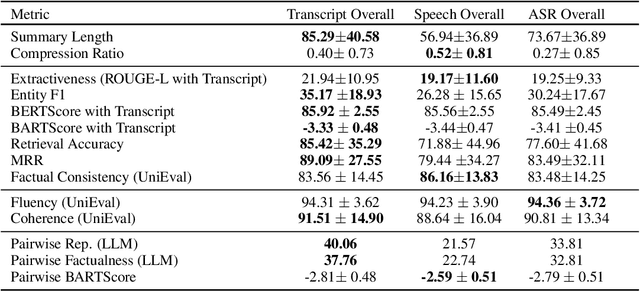
Reference summaries for abstractive speech summarization require human annotation, which can be performed by listening to an audio recording or by reading textual transcripts of the recording. In this paper, we examine whether summaries based on annotators listening to the recordings differ from those based on annotators reading transcripts. Using existing intrinsic evaluation based on human evaluation, automatic metrics, LLM-based evaluation, and a retrieval-based reference-free method. We find that summaries are indeed different based on the source modality, and that speech-based summaries are more factually consistent and information-selective than transcript-based summaries. Meanwhile, transcript-based summaries are impacted by recognition errors in the source, and expert-written summaries are more informative and reliable. We make all the collected data and analysis code public(https://github.com/cmu-mlsp/interview_humanssum) to facilitate the reproduction of our work and advance research in this area.
Online Active Learning For Sound Event Detection
Sep 25, 2023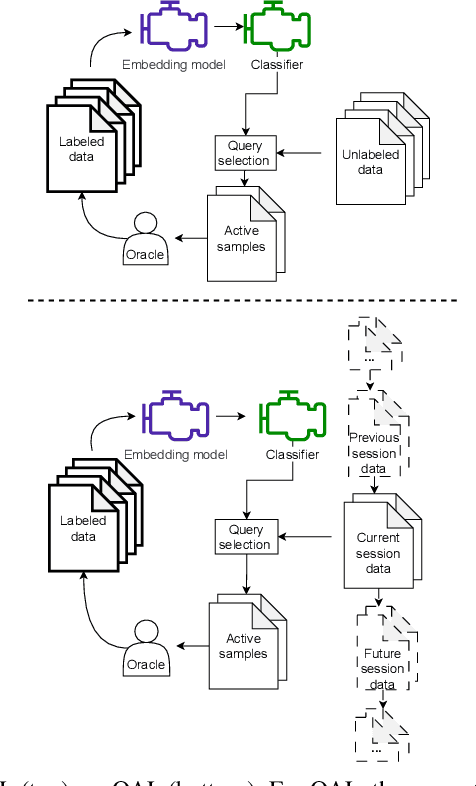
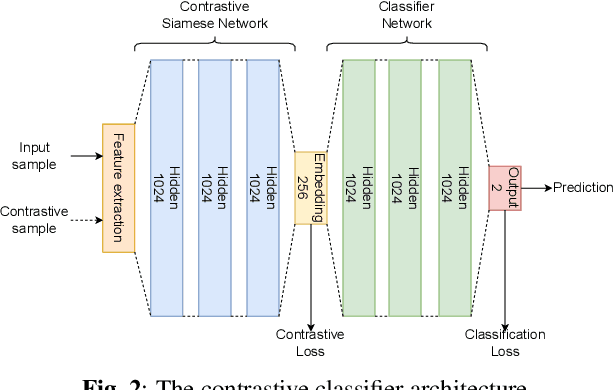
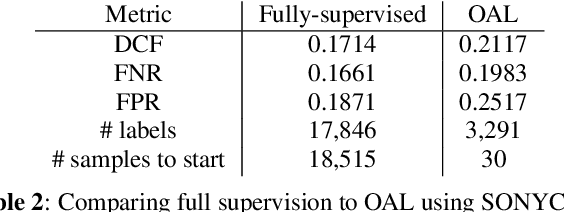
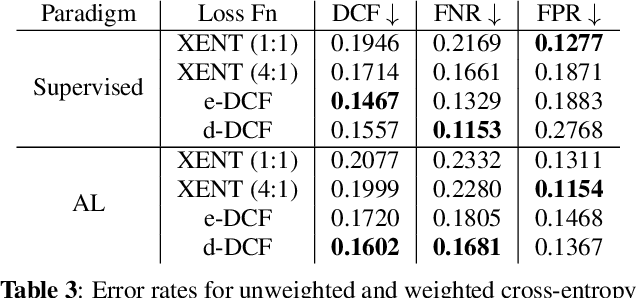
Data collection and annotation is a laborious, time-consuming prerequisite for supervised machine learning tasks. Online Active Learning (OAL) is a paradigm that addresses this issue by simultaneously minimizing the amount of annotation required to train a classifier and adapting to changes in the data over the duration of the data collection process. Prior work has indicated that fluctuating class distributions and data drift are still common problems for OAL. This work presents new loss functions that address these challenges when OAL is applied to Sound Event Detection (SED). Experimental results from the SONYC dataset and two Voice-Type Discrimination (VTD) corpora indicate that OAL can reduce the time and effort required to train SED classifiers by a factor of 5 for SONYC, and that the new methods presented here successfully resolve issues present in existing OAL methods.
Self-supervision and Learnable STRFs for Age, Emotion, and Country Prediction
Jun 25, 2022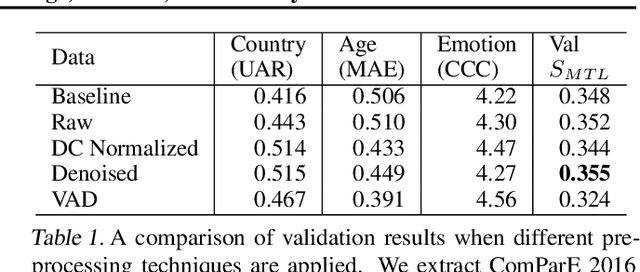
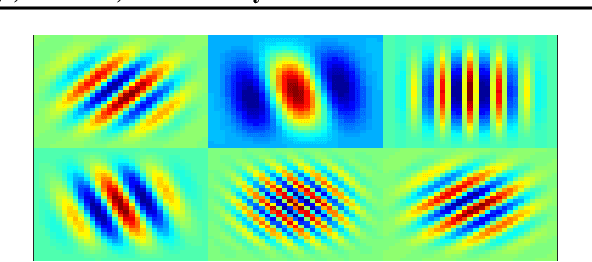
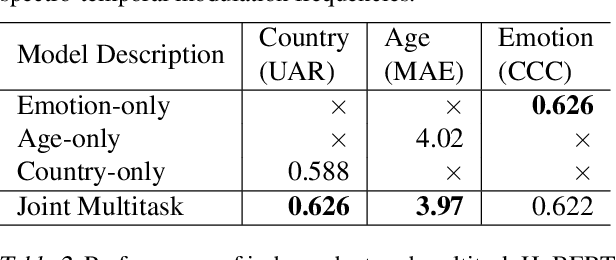
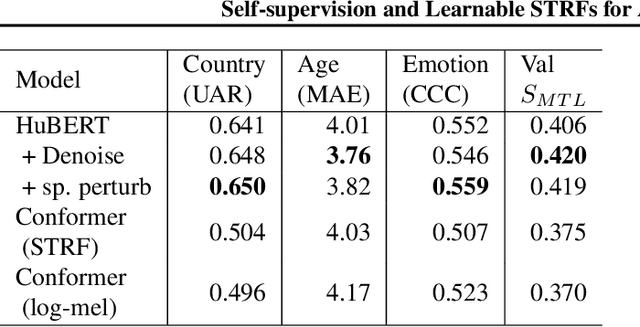
This work presents a multitask approach to the simultaneous estimation of age, country of origin, and emotion given vocal burst audio for the 2022 ICML Expressive Vocalizations Challenge ExVo-MultiTask track. The method of choice utilized a combination of spectro-temporal modulation and self-supervised features, followed by an encoder-decoder network organized in a multitask paradigm. We evaluate the complementarity between the tasks posed by examining independent task-specific and joint models, and explore the relative strengths of different feature sets. We also introduce a simple score fusion mechanism to leverage the complementarity of different feature sets for this task. We find that robust data preprocessing in conjunction with score fusion over spectro-temporal receptive field and HuBERT models achieved our best ExVo-MultiTask test score of 0.412.