 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Analog Dynamic Range Compressors using Deep Learning and State-space Models
Mar 24, 2024We describe a novel approach for developing realistic digital models of dynamic range compressors for digital audio production by analyzing their analog prototypes. While realistic digital dynamic compressors are potentially useful for many applications, the design process is challenging because the compressors operate nonlinearly over long time scales. Our approach is based on the structured state space sequence model (S4), as implementing the state-space model (SSM) has proven to be efficient at learning long-range dependencies and is promising for modeling dynamic range compressors. We present in this paper a deep learning model with S4 layers to model the Teletronix LA-2A analog dynamic range compressor. The model is causal, executes efficiently in real time, and achieves roughly the same quality as previous deep-learning models but with fewer parameters.
Online Active Learning For Sound Event Detection
Sep 25, 2023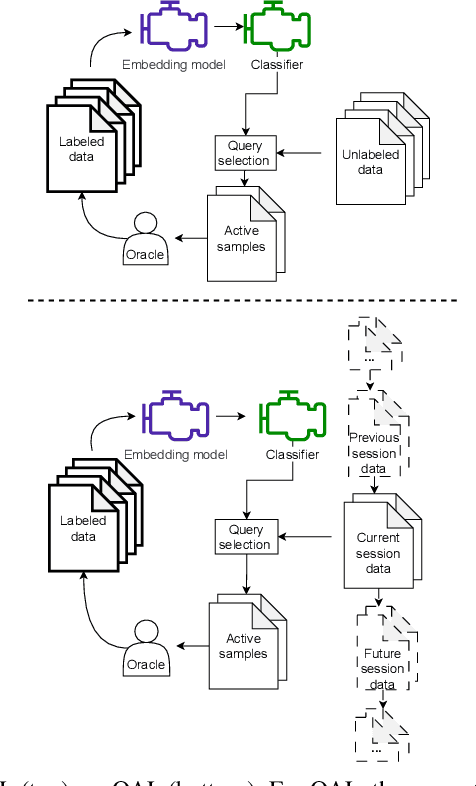
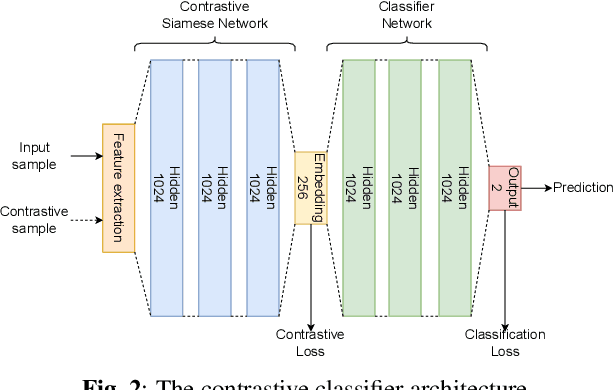
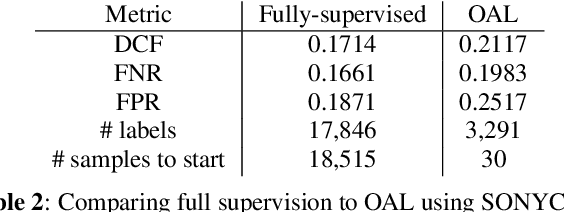
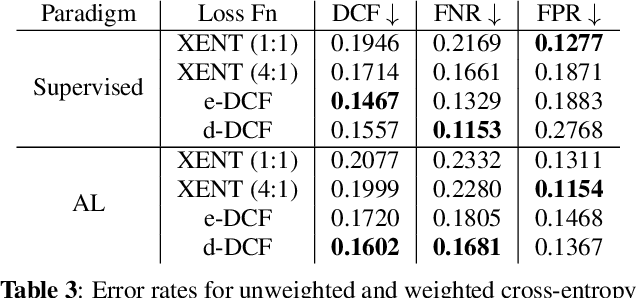
Data collection and annotation is a laborious, time-consuming prerequisite for supervised machine learning tasks. Online Active Learning (OAL) is a paradigm that addresses this issue by simultaneously minimizing the amount of annotation required to train a classifier and adapting to changes in the data over the duration of the data collection process. Prior work has indicated that fluctuating class distributions and data drift are still common problems for OAL. This work presents new loss functions that address these challenges when OAL is applied to Sound Event Detection (SED). Experimental results from the SONYC dataset and two Voice-Type Discrimination (VTD) corpora indicate that OAL can reduce the time and effort required to train SED classifiers by a factor of 5 for SONYC, and that the new methods presented here successfully resolve issues present in existing OAL methods.
Learnable Front Ends Based on Temporal Modulation for Music Tagging
Nov 28, 2022



While end-to-end systems are becoming popular in auditory signal processing including automatic music tagging, models using raw audio as input needs a large amount of data and computational resources without domain knowledge. Inspired by the fact that temporal modulation is regarded as an essential component in auditory perception, we introduce the Temporal Modulation Neural Network (TMNN) that combines Mel-like data-driven front ends and temporal modulation filters with a simple ResNet back end. The structure includes a set of temporal modulation filters to capture long-term patterns in all frequency channels. Experimental results show that the proposed front ends surpass state-of-the-art (SOTA) methods on the MagnaTagATune dataset in automatic music tagging, and they are also helpful for keyword spotting on speech commands. Moreover, the model performance for each tag suggests that genre or instrument tags with complex rhythm and mood tags can especially be improved with temporal modulation.
A Modulation-Domain Loss for Neural-Network-based Real-time Speech Enhancement
Feb 15, 2021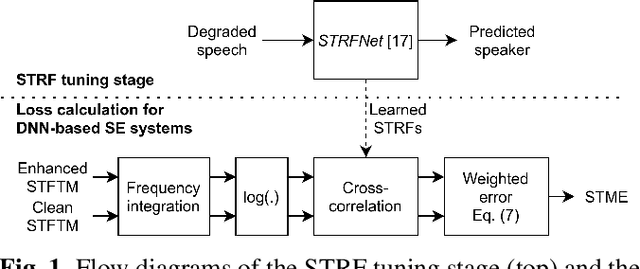
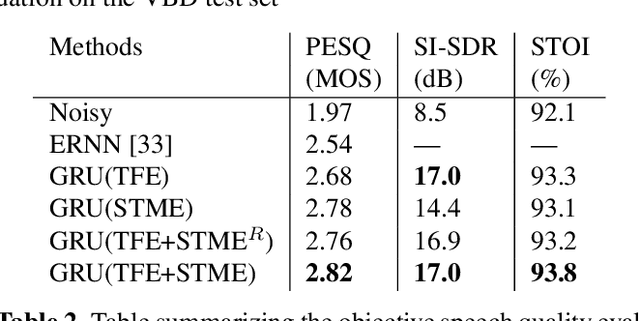
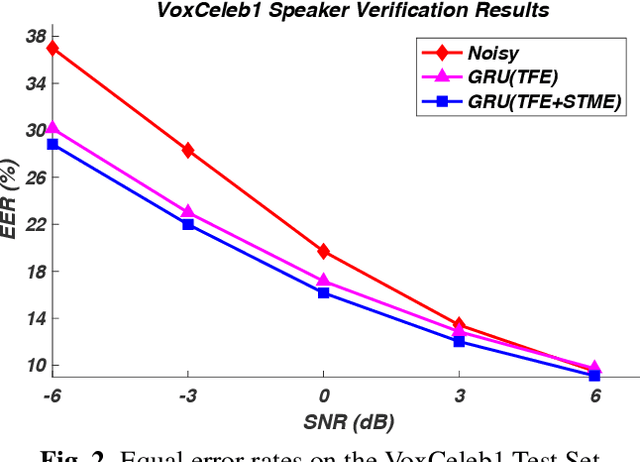
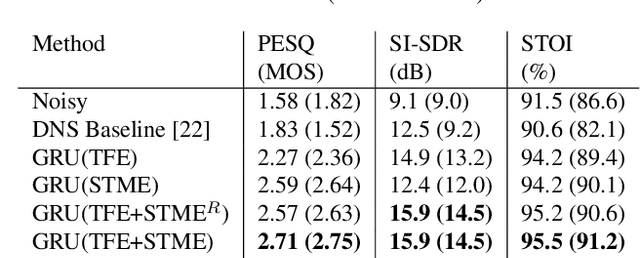
We describe a modulation-domain loss function for deep-learning-based speech enhancement systems. Learnable spectro-temporal receptive fields (STRFs) were adapted to optimize for a speaker identification task. The learned STRFs were then used to calculate a weighted mean-squared error (MSE) in the modulation domain for training a speech enhancement system. Experiments showed that adding the modulation-domain MSE to the MSE in the spectro-temporal domain substantially improved the objective prediction of speech quality and intelligibility for real-time speech enhancement systems without incurring additional computation during inference.