Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modulation-Domain Loss for Neural-Network-based Real-time Speech Enhancement
Paper and Code
Feb 15, 2021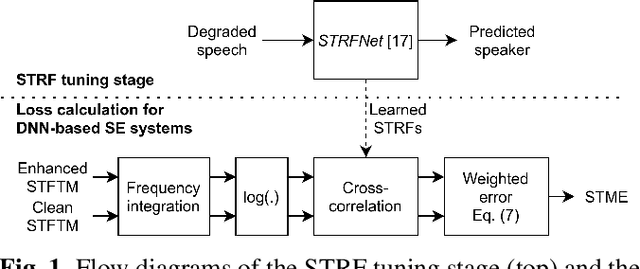
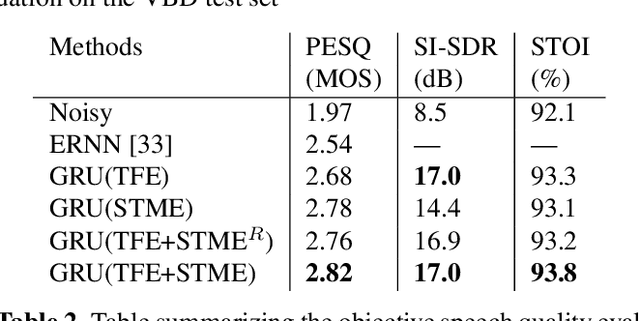
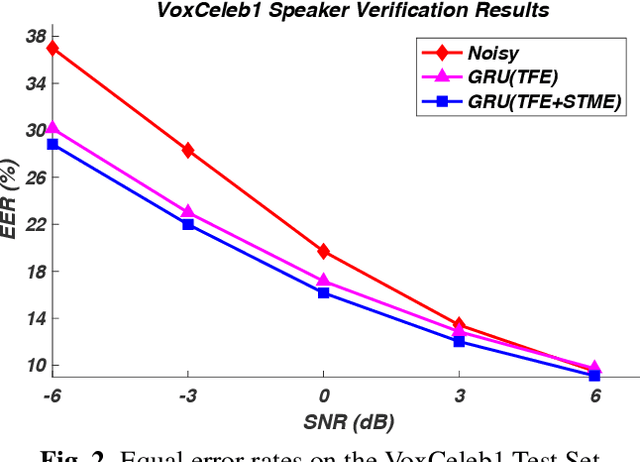
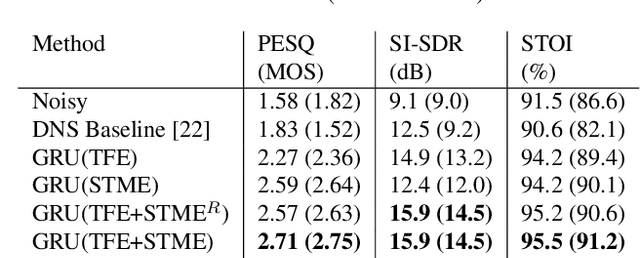
We describe a modulation-domain loss function for deep-learning-based speech enhancement systems. Learnable spectro-temporal receptive fields (STRFs) were adapted to optimize for a speaker identification task. The learned STRFs were then used to calculate a weighted mean-squared error (MSE) in the modulation domain for training a speech enhancement system. Experiments showed that adding the modulation-domain MSE to the MSE in the spectro-temporal domain substantially improved the objective prediction of speech quality and intelligibility for real-time speech enhancement systems without incurring additional computation during inference.
* Accepted IEEE ICASSP 2021
View paper on