 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond correlation: The impact of human uncertainty in measuring the effectiveness of automatic evaluation and LLM-as-a-judge
Oct 03, 2024



The effectiveness of automatic evaluation of generative models is typically measured by comparing it to human evaluation using correlation metrics. However, metrics like Krippendorff's $\alpha$ and Randolph's $\kappa$, originally designed to measure the reliability of human labeling, make assumptions about human behavior and the labeling process. In this paper, we show how *relying on a single aggregate correlation score* can obscure fundamental differences between human behavior and automatic evaluation methods, including LLM-as-a-Judge. Specifically, we demonstrate that when the proportion of samples with variation or uncertainty in human labels (gathered during human evaluation) is relatively high, machine labels (generated by automatic evaluation methods) may superficially appear to have similar or better correlation with the human majority label compared to human-to-human (HH) correlation. This can create the misleading impression that automatic evaluation is accurate enough to approximate the human majority label. However, as the proportion of samples with consistent human labels increases, the correlation between machine labels and human majority labels declines, falling below HH correlation. Based on these findings, we first propose stratifying results by human label uncertainty to provide a more robust analysis of automatic evaluation performance. Second, recognizing that uncertainty and variation are inherent in perception-based human evaluations, such as those involving attitudes or preferences, we introduce a new metric - *binned Jensen-Shannon Divergence for perception* for such scenarios to better measure the effectiveness of automatic evaluations. Third, we present visualization techniques -- *perception charts*, to compare the strengths and limitations of automatic evaluation and to contextualize correlation measures appropriately
Generalized Spoofing Detection Inspired from Audio Generation Artifacts
Apr 08, 2021

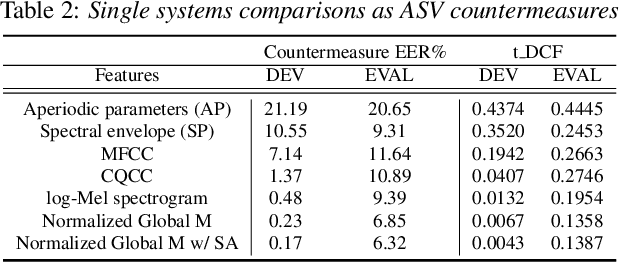

State-of-the-art methods for audio generation suffer from fingerprint artifacts and repeated inconsistencies across temporal and spectral domains. Such artifacts could be well captured by the frequency domain analysis over the spectrogram. Thus, we propose a novel use of long-range spectro-temporal modulation feature -- 2D DCT over log-Mel spectrogram for the audio deepfake detection. We show that this feature works better than log-Mel spectrogram, CQCC, MFCC, etc., as a suitable candidate to capture such artifacts. We employ spectrum augmentation and feature normalization to decrease overfitting and bridge the gap between training and test dataset along with this novel feature introduction. We developed a CNN-based baseline that achieved a 0.0849 t-DCF and outperformed the best single system reported in the ASVspoof 2019 challenge. Finally, by combining our baseline with our proposed 2D DCT spectro-temporal feature, we decrease the t-DCF score down by 14% to 0.0737, making it one of the best systems for spoofing detection. Furthermore, we evaluate our model using two external datasets, showing the proposed feature's generalization ability. We also provide analysis and ablation studies for our proposed feature and results.
Grapheme-to-Phoneme Transformer Model for Transfer Learning Dialects
Apr 08, 2021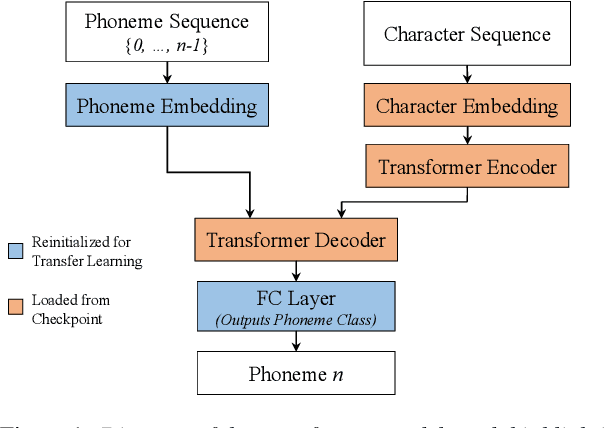

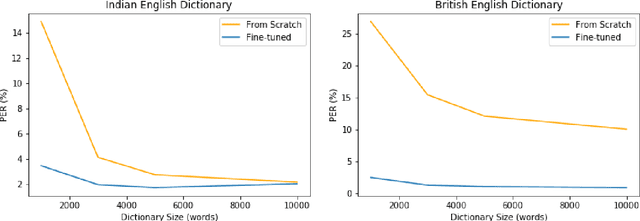
Grapheme-to-Phoneme (G2P) models convert words to their phonetic pronunciations. Classic G2P methods include rule-based systems and pronunciation dictionaries, while modern G2P systems incorporate learning, such as, LSTM and Transformer-based attention models. Usually, dictionary-based methods require significant manual effort to build, and have limited adaptivity on unseen words. And transformer-based models require significant training data, and do not generalize well, especially for dialects with limited data. We propose a novel use of transformer-based attention model that can adapt to unseen dialects of English language, while using a small dictionary. We show that our method has potential applications for accent transfer for text-to-speech, and for building robust G2P models for dialects with limited pronunciation dictionary size. We experiment with two English dialects: Indian and British. A model trained from scratch using 1000 words from British English dictionary, with 14211 words held out, leads to phoneme error rate (PER) of 26.877%, on a test set generated using the full dictionary. The same model pretrained on CMUDict American English dictionary, and fine-tuned on the same dataset leads to PER of 2.469% on the test set.
Flavored Tacotron: Conditional Learning for Prosodic-linguistic Features
Apr 08, 2021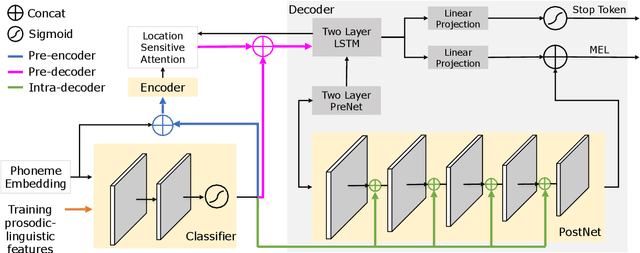
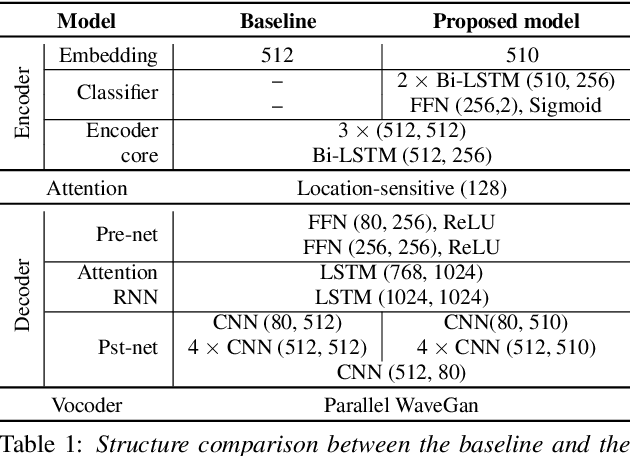
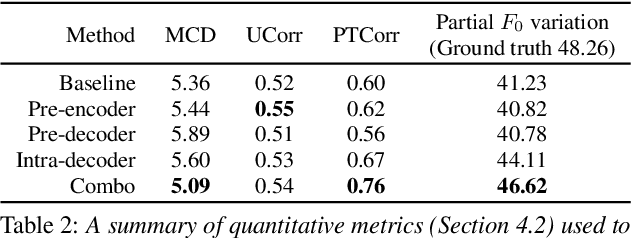
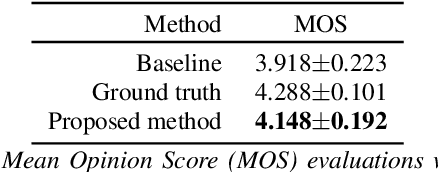
Neural sequence-to-sequence text-to-speech synthesis (TTS), such as Tacotron-2, transforms text into high-quality speech. However, generating speech with natural prosody still remains a challenge. Yasuda et. al. show that unlike natural speech, Tacotron-2's encoder doesn't fully represent prosodic features (e.g. syllable stress in English) from characters, and result in flat fundamental frequency variations. In this work, we propose a novel carefully designed strategy for conditioning Tacotron-2 on two fundamental prosodic features in English -- stress syllable and pitch accent, that help achieve more natural prosody. To this end, we use of a classifier to learn these features in an end-to-end fashion, and apply feature conditioning at three parts of Tacotron-2's Text-To-Mel Spectrogram: pre-encoder, post-encoder, and intra-decoder. Further, we show that jointly conditioned features at pre-encoder and intra-decoder stages result in prosodically natural synthesized speech (vs. Tacotron-2), and allows the model to produce speech with more accurate pitch accent and stress patterns. Quantitative evaluations show that our formulation achieves higher fundamental frequency contour correlation, and lower Mel Cepstral Distortion measure between synthesized and natural speech. And subjective evaluation shows that the proposed method's Mean Opinion Score of 4.14 fairs higher than baseline Tacotron-2, 3.91, when compared against natural speech (LJSpeech corpus), 4.28.