 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrapheme-to-Phoneme Transformer Model for Transfer Learning Dialects
Paper and Code
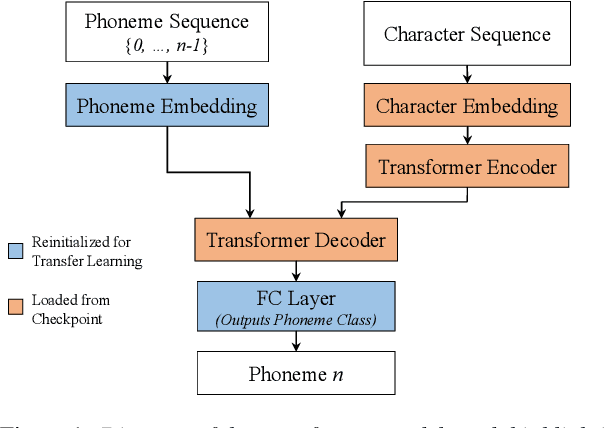

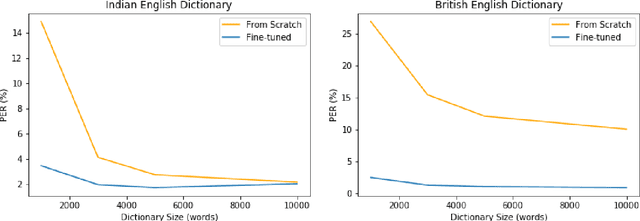
Grapheme-to-Phoneme (G2P) models convert words to their phonetic pronunciations. Classic G2P methods include rule-based systems and pronunciation dictionaries, while modern G2P systems incorporate learning, such as, LSTM and Transformer-based attention models. Usually, dictionary-based methods require significant manual effort to build, and have limited adaptivity on unseen words. And transformer-based models require significant training data, and do not generalize well, especially for dialects with limited data. We propose a novel use of transformer-based attention model that can adapt to unseen dialects of English language, while using a small dictionary. We show that our method has potential applications for accent transfer for text-to-speech, and for building robust G2P models for dialects with limited pronunciation dictionary size. We experiment with two English dialects: Indian and British. A model trained from scratch using 1000 words from British English dictionary, with 14211 words held out, leads to phoneme error rate (PER) of 26.877%, on a test set generated using the full dictionary. The same model pretrained on CMUDict American English dictionary, and fine-tuned on the same dataset leads to PER of 2.469% on the test set.