 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Person Search Using Deep Reinforcement Learning
Paper and Code
Sep 02, 2018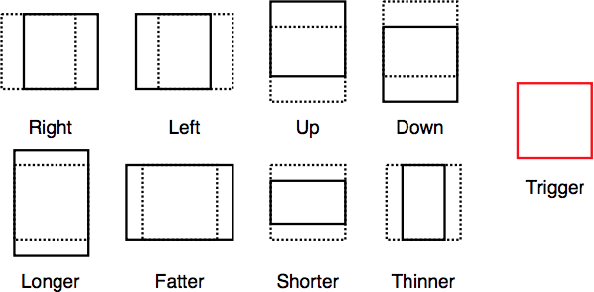
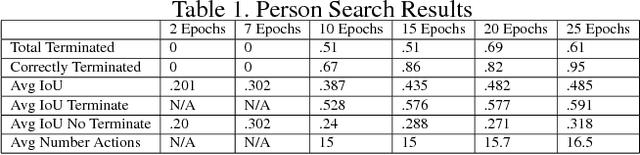
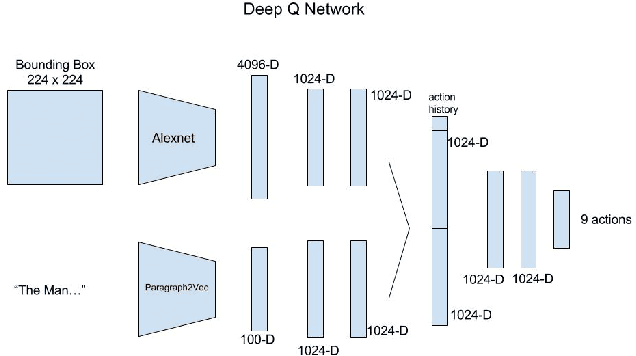

Recent success in deep reinforcement learning is having an agent learn how to play Go and beat the world champion without any prior knowledge of the game. In that task, the agent has to make a decision on what action to take based on the positions of the pieces. Person Search is recently explored using natural language based text description of images for video surveillance applications (S.Li et.al). We see (Fu.et al) provides an end to end approach for object-based retrieval using deep reinforcement learning without constraints placed on which objects are being detected. However, we believe for real-world applications such as person search defining specific constraints which identify a person as opposed to starting with a general object detection will have benefits in terms of performance and computational resources required. In our task, Deep reinforcement learning would localize the person in an image by reshaping the sizes of the bounding boxes. Deep Reinforcement learning with appropriate constraints would look only for the relevant person in the image as opposed to an unconstrained approach where each individual objects in the image are ranked. For person search, the agent is trying to form a tight bounding box around the person in the image who matches the description. The bounding box is initialized to the full image and at each time step, the agent makes a decision on how to change the current bounding box so that it has a tighter bound around the person based on the description of the person and the pixel values of the current bounding box. After the agent takes an action, it will be given a reward based on the Intersection over Union (IoU) of the current bounding box and the ground truth box. Once the agent believes that the bounding box is covering the person, it will indicate that the person is found.