 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Backdoor: Towards Stealthy Real-world Poisoning Attack on Vision-Language-Action Model in State Space
Jan 07, 2026Vision-Language-Action (VLA) models are widely deployed in safety-critical embodied AI applications such as robotics. However, their complex multimodal interactions also expose new security vulnerabilities. In this paper, we investigate a backdoor threat in VLA models, where malicious inputs cause targeted misbehavior while preserving performance on clean data. Existing backdoor methods predominantly rely on inserting visible triggers into visual modality, which suffer from poor robustness and low insusceptibility in real-world settings due to environmental variability. To overcome these limitations, we introduce the State Backdoor, a novel and practical backdoor attack that leverages the robot arm's initial state as the trigger. To optimize trigger for insusceptibility and effectiveness, we design a Preference-guided Genetic Algorithm (PGA) that efficiently searches the state space for minimal yet potent triggers. Extensive experiments on five representative VLA models and five real-world tasks show that our method achieves over 90% attack success rate without affecting benign task performance, revealing an underexplored vulnerability in embodied AI systems.
BadDepth: Backdoor Attacks Against Monocular Depth Estimation in the Physical World
May 22, 2025In recent years, deep learning-based Monocular Depth Estimation (MDE) models have been widely applied in fields such as autonomous driving and robotics. However, their vulnerability to backdoor attacks remains unexplored. To fill the gap in this area, we conduct a comprehensive investigation of backdoor attacks against MDE models. Typically, existing backdoor attack methods can not be applied to MDE models. This is because the label used in MDE is in the form of a depth map. To address this, we propose BadDepth, the first backdoor attack targeting MDE models. BadDepth overcomes this limitation by selectively manipulating the target object's depth using an image segmentation model and restoring the surrounding areas via depth completion, thereby generating poisoned datasets for object-level backdoor attacks. To improve robustness in physical world scenarios, we further introduce digital-to-physical augmentation to adapt to the domain gap between the physical world and the digital domain. Extensive experiments on multiple models validate the effectiveness of BadDepth in both the digital domain and the physical world, without being affected by environmental factors.
Graph Entropy Minimization for Semi-supervised Node Classification
May 31, 2023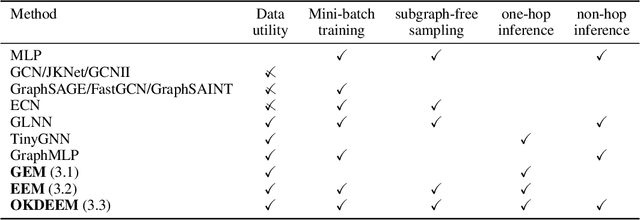
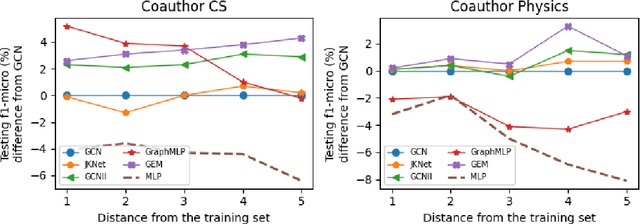
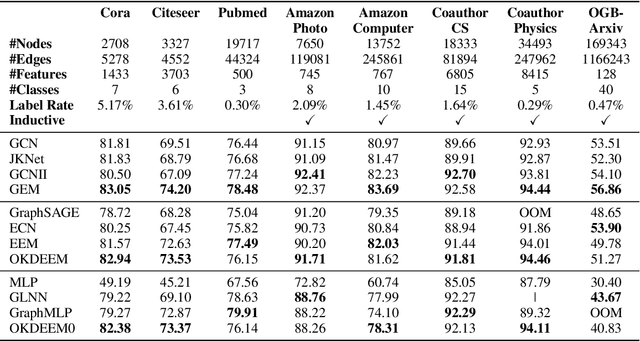
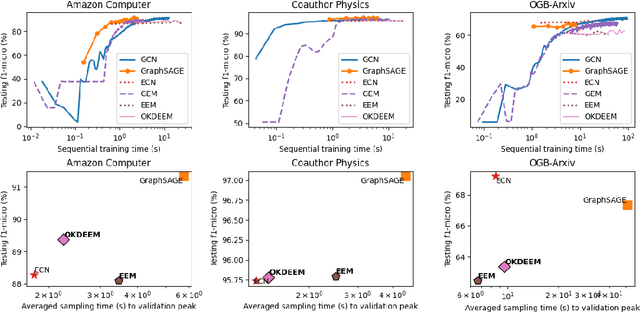
Node classifiers are required to comprehensively reduce prediction errors, training resources, and inference latency in the industry. However, most graph neural networks (GNN) concentrate only on one or two of them. The compromised aspects thus are the shortest boards on the bucket, hindering their practical deployments for industrial-level tasks. This work proposes a novel semi-supervised learning method termed Graph Entropy Minimization (GEM) to resolve the three issues simultaneously. GEM benefits its one-hop aggregation from massive uncategorized nodes, making its prediction accuracy comparable to GNNs with two or more hops message passing. It can be decomposed to support stochastic training with mini-batches of independent edge samples, achieving extremely fast sampling and space-saving training. While its one-hop aggregation is faster in inference than deep GNNs, GEM can be further accelerated to an extreme by deriving a non-hop classifier via online knowledge distillation. Thus, GEM can be a handy choice for latency-restricted and error-sensitive services running on resource-constraint hardware. Code is available at https://github.com/cf020031308/GEM.
Unifying Label-inputted Graph Neural Networks with Deep Equilibrium Models
Nov 19, 2022



For node classification, Graph Neural Networks (GNN) assign predefined labels to graph nodes according to node features propagated along the graph structure. Apart from the traditional end-to-end manner inherited from deep learning, many subsequent works input assigned labels into GNNs to improve their classification performance. Such label-inputted GNNs (LGNN) combine the advantages of learnable feature propagation and long-range label propagation, producing state-of-the-art performance on various benchmarks. However, the theoretical foundations of LGNNs are not well-established, and the combination is with seam because the long-range propagation is memory-consuming for optimization. To this end, this work interprets LGNNs with the theory of Implicit GNN (IGNN), which outputs a fixed state point of iterating its network infinite times and optimizes the infinite-range propagation with constant memory consumption. Besides, previous contributions to LGNNs inspire us to overcome the heavy computation in training IGNN by iterating the network only once but starting from historical states, which are randomly masked in forward-pass to implicitly guarantee the existence and uniqueness of the fixed point. Our improvements to IGNNs are network agnostic: for the first time, they are extended with complex networks and applied to large-scale graphs. Experiments on two synthetic and six real-world datasets verify the advantages of our method in terms of long-range dependencies capturing, label transitions modelling, accuracy, scalability, efficiency, and well-posedness.
Distilling Self-Knowledge From Contrastive Links to Classify Graph Nodes Without Passing Messages
Jun 16, 2021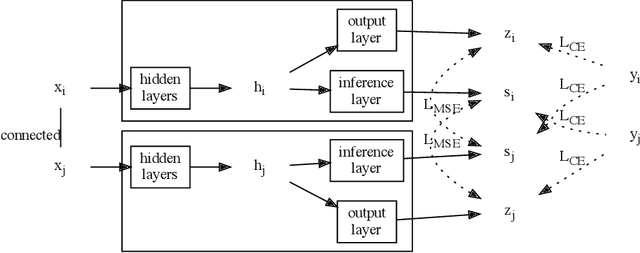
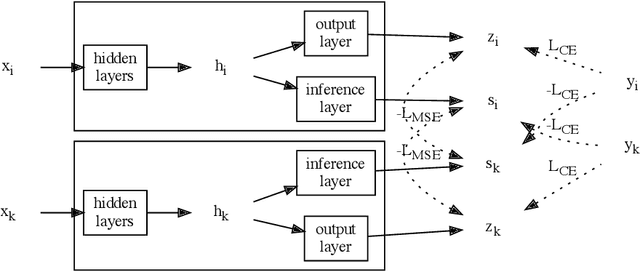

Nowadays, Graph Neural Networks (GNNs) following the Message Passing paradigm become the dominant way to learn on graphic data. Models in this paradigm have to spend extra space to look up adjacent nodes with adjacency matrices and extra time to aggregate multiple messages from adjacent nodes. To address this issue, we develop a method called LinkDist that distils self-knowledge from connected node pairs into a Multi-Layer Perceptron (MLP) without the need to aggregate messages. Experiment with 8 real-world datasets shows the MLP derived from LinkDist can predict the label of a node without knowing its adjacencies but achieve comparable accuracy against GNNs in the contexts of semi- and full-supervised node classification. Moreover, LinkDist benefits from its Non-Message Passing paradigm that we can also distil self-knowledge from arbitrarily sampled node pairs in a contrastive way to further boost the performance of LinkDist.
Memory-Associated Differential Learning
Feb 10, 2021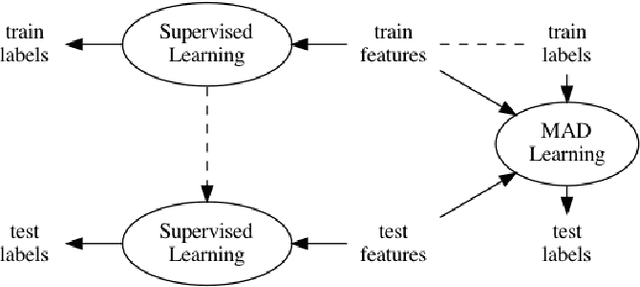

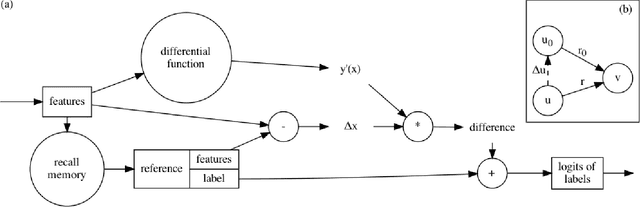
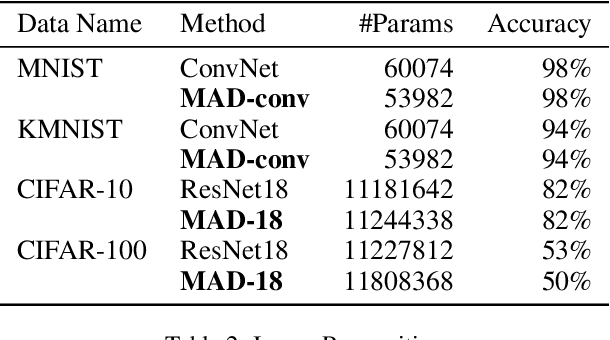
Conventional Supervised Learning approaches focus on the mapping from input features to output labels. After training, the learnt models alone are adapted onto testing features to predict testing labels in isolation, with training data wasted and their associations ignored. To take full advantage of the vast number of training data and their associations, we propose a novel learning paradigm called Memory-Associated Differential (MAD) Learning. We first introduce an additional component called Memory to memorize all the training data. Then we learn the differences of labels as well as the associations of features in the combination of a differential equation and some sampling methods. Finally, in the evaluating phase, we predict unknown labels by inferencing from the memorized facts plus the learnt differences and associations in a geometrically meaningful manner. We gently build this theory in unary situations and apply it on Image Recognition, then extend it into Link Prediction as a binary situation, in which our method outperforms strong state-of-the-art baselines on three citation networks and ogbl-ddi dataset.