 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustered Data Sharing for Non-IID Federated Learning over Wireless Networks
Paper and Code
Mar 01, 2023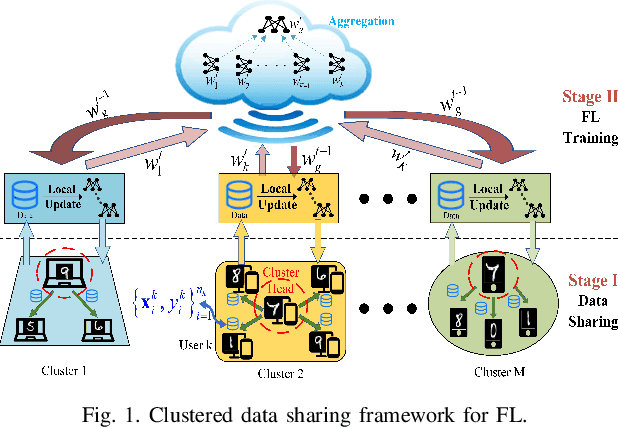
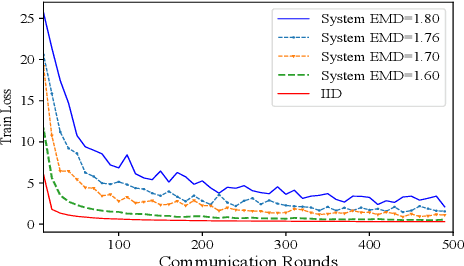
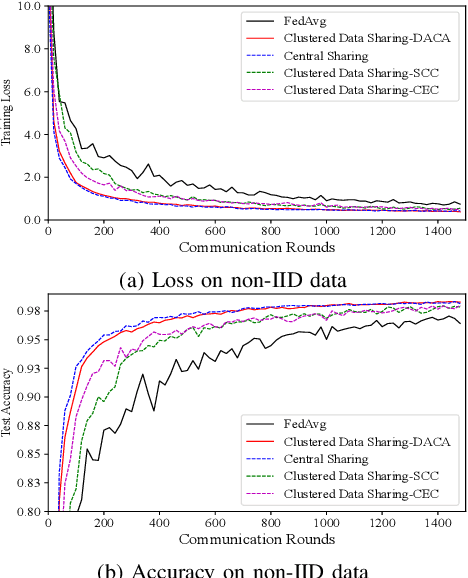
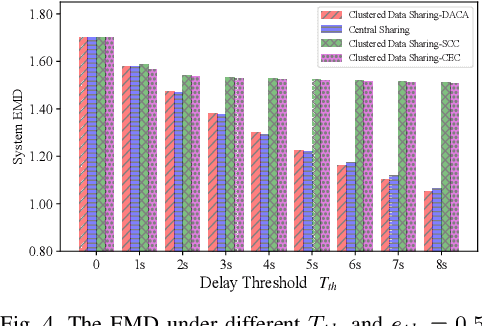
Federated Learning (FL) is a novel distributed machine learning approach to leverage data from Internet of Things (IoT) devices while maintaining data privacy. However, the current FL algorithms face the challenges of non-independent and identically distributed (non-IID) data, which causes high communication costs and model accuracy declines. To address the statistical imbalances in FL, we propose a clustered data sharing framework which spares the partial data from cluster heads to credible associates through device-to-device (D2D) communication. Moreover, aiming at diluting the data skew on nodes, we formulate the joint clustering and data sharing problem based on the privacy-preserving constrained graph. To tackle the serious coupling of decisions on the graph, we devise a distribution-based adaptive clustering algorithm (DACA) basing on three deductive cluster-forming conditions, which ensures the maximum yield of data sharing. The experiments show that the proposed framework facilitates FL on non-IID datasets with better convergence and model accuracy under a limited communication environment.