 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs Disagree: Diagnosing Relevance Filtering Bias and Retrieval Divergence in SDG Search
Jul 02, 2025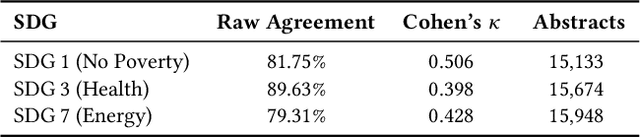
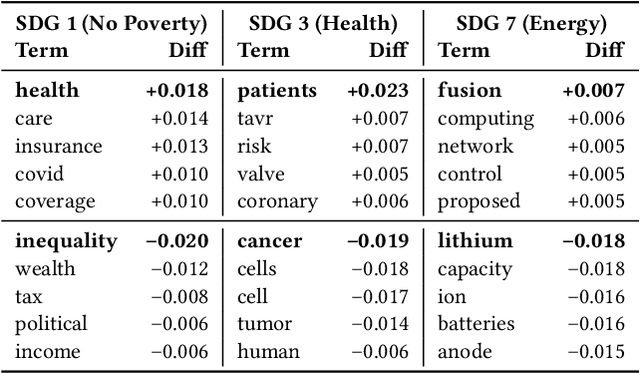
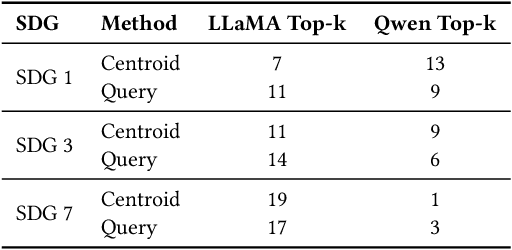
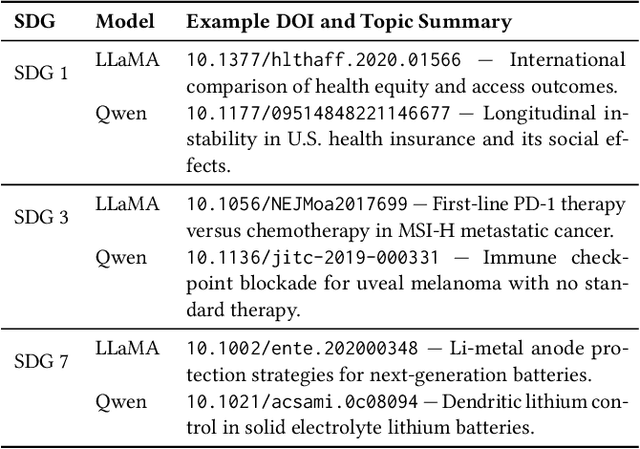
Large language models (LLMs) are increasingly used to assign document relevance labels in information retrieval pipelines, especially in domains lacking human-labeled data. However, different models often disagree on borderline cases, raising concerns about how such disagreement affects downstream retrieval. This study examines labeling disagreement between two open-weight LLMs, LLaMA and Qwen, on a corpus of scholarly abstracts related to Sustainable Development Goals (SDGs) 1, 3, and 7. We isolate disagreement subsets and examine their lexical properties, rank-order behavior, and classification predictability. Our results show that model disagreement is systematic, not random: disagreement cases exhibit consistent lexical patterns, produce divergent top-ranked outputs under shared scoring functions, and are distinguishable with AUCs above 0.74 using simple classifiers. These findings suggest that LLM-based filtering introduces structured variability in document retrieval, even under controlled prompting and shared ranking logic. We propose using classification disagreement as an object of analysis in retrieval evaluation, particularly in policy-relevant or thematic search tasks.
Making History Readable
Nov 26, 2024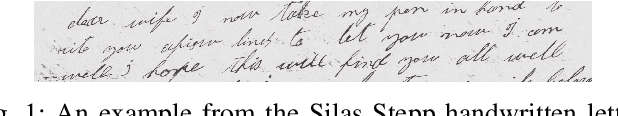

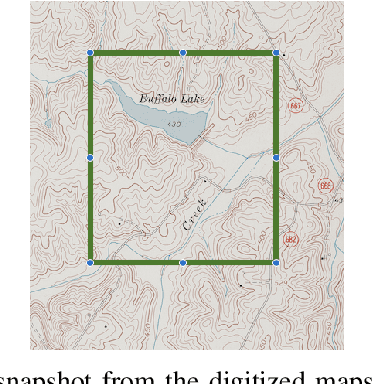

The Virginia Tech University Libraries (VTUL) Digital Library Platform (DLP) hosts digital collections that offer our users access to a wide variety of documents of historical and cultural importance. These collections are not only of academic importance but also provide our users with a glance at local historical events. Our DLP contains collections comprising digital objects featuring complex layouts, faded imagery, and hard-to-read handwritten text, which makes providing online access to these materials challenging. To address these issues, we integrate AI into our DLP workflow and convert the text in the digital objects into a machine-readable format. To enhance the user experience with our historical collections, we use custom AI agents for handwriting recognition, text extraction, and large language models (LLMs) for summarization. This poster highlights three collections focusing on handwritten letters, newspapers, and digitized topographic maps. We discuss the challenges with each collection and detail our approaches to address them. Our proposed methods aim to enhance the user experience by making the contents in these collections easier to search and navigate.
Automating Chapter-Level Classification for Electronic Theses and Dissertations
Nov 26, 2024Traditional archival practices for describing electronic theses and dissertations (ETDs) rely on broad, high-level metadata schemes that fail to capture the depth, complexity, and interdisciplinary nature of these long scholarly works. The lack of detailed, chapter-level content descriptions impedes researchers' ability to locate specific sections or themes, thereby reducing discoverability and overall accessibility. By providing chapter-level metadata information, we improve the effectiveness of ETDs as research resources. This makes it easier for scholars to navigate them efficiently and extract valuable insights. The absence of such metadata further obstructs interdisciplinary research by obscuring connections across fields, hindering new academic discoveries and collaboration. In this paper, we propose a machine learning and AI-driven solution to automatically categorize ETD chapters. This solution is intended to improve discoverability and promote understanding of chapters. Our approach enriches traditional archival practices by providing context-rich descriptions that facilitate targeted navigation and improved access. We aim to support interdisciplinary research and make ETDs more accessible. By providing chapter-level classification labels and using them to index in our developed prototype system, we make content in ETD chapters more discoverable and usable for a diverse range of scholarly needs. Implementing this AI-enhanced approach allows archives to serve researchers better, enabling efficient access to relevant information and supporting deeper engagement with ETDs. This will increase the impact of ETDs as research tools, foster interdisciplinary exploration, and reinforce the role of archives in scholarly communication within the data-intensive academic landscape.
Agentic AI for Improving Precision in Identifying Contributions to Sustainable Development Goals
Nov 26, 2024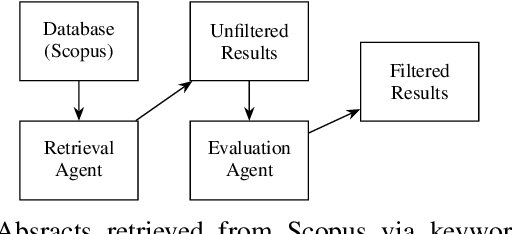
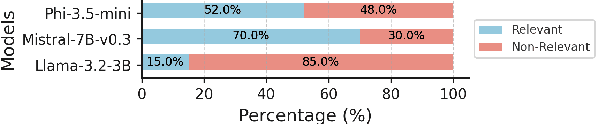
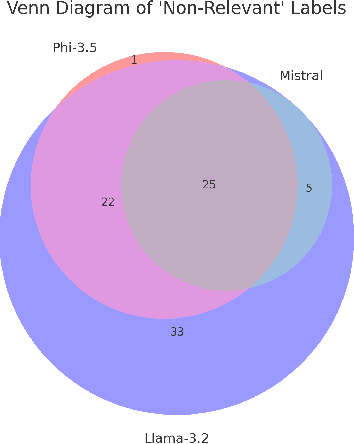
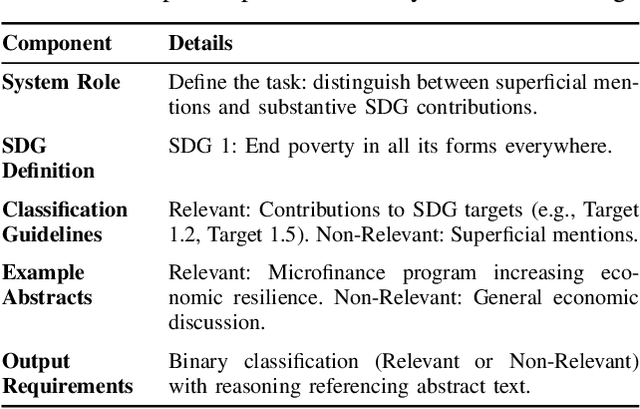
As research institutions increasingly commit to supporting the United Nations' Sustainable Development Goals (SDGs), there is a pressing need to accurately assess their research output against these goals. Current approaches, primarily reliant on keyword-based Boolean search queries, conflate incidental keyword matches with genuine contributions, reducing retrieval precision and complicating benchmarking efforts. This study investigates the application of autoregressive Large Language Models (LLMs) as evaluation agents to identify relevant scholarly contributions to SDG targets in scholarly publications. Using a dataset of academic abstracts retrieved via SDG-specific keyword queries, we demonstrate that small, locally-hosted LLMs can differentiate semantically relevant contributions to SDG targets from documents retrieved due to incidental keyword matches, addressing the limitations of traditional methods. By leveraging the contextual understanding of LLMs, this approach provides a scalable framework for improving SDG-related research metrics and informing institutional reporting.
VTechAGP: An Academic-to-General-Audience Text Paraphrase Dataset and Benchmark Models
Nov 07, 2024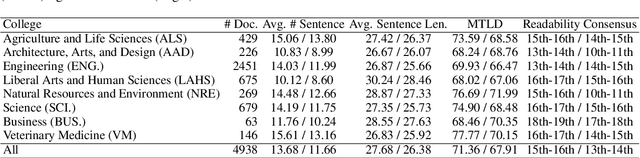
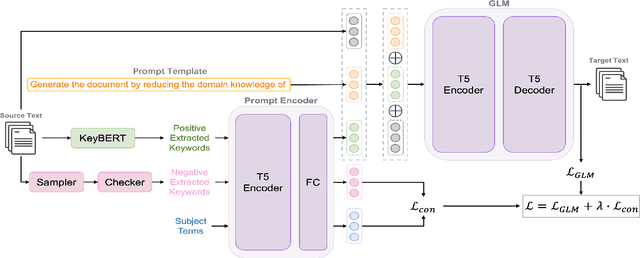
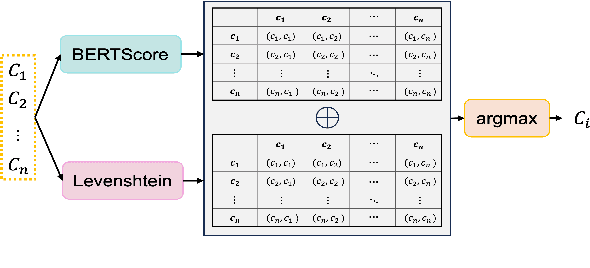
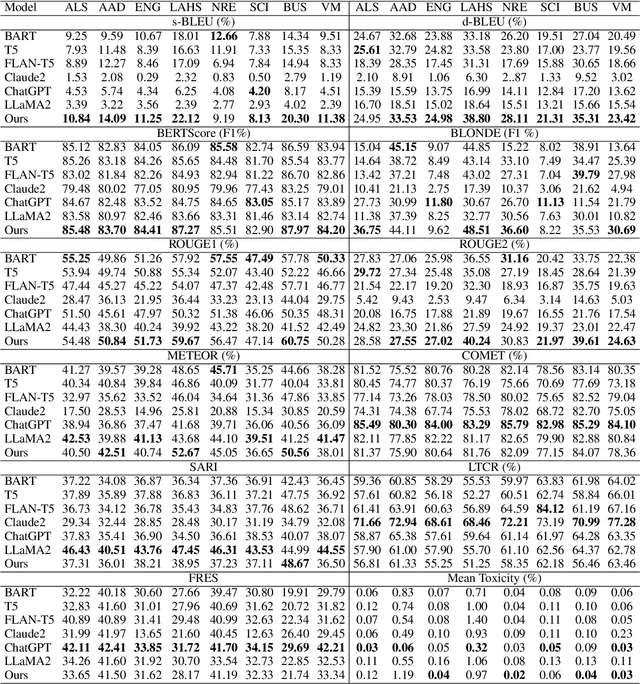
Existing text simplification or paraphrase datasets mainly focus on sentence-level text generation in a general domain. These datasets are typically developed without using domain knowledge. In this paper, we release a novel dataset, VTechAGP, which is the first academic-to-general-audience text paraphrase dataset consisting of 4,938 document-level these and dissertation academic and general-audience abstract pairs from 8 colleges authored over 25 years. We also propose a novel dynamic soft prompt generative language model, DSPT5. For training, we leverage a contrastive-generative loss function to learn the keyword vectors in the dynamic prompt. For inference, we adopt a crowd-sampling decoding strategy at both semantic and structural levels to further select the best output candidate. We evaluate DSPT5 and various state-of-the-art large language models (LLMs) from multiple perspectives. Results demonstrate that the SOTA LLMs does not provide satisfactory outcomes, while the lightweight DSPT5 can achieve competitive results. To the best of our knowledge, we are the first to build a benchmark dataset and solutions for academic-to-general-audience text paraphrase dataset.
ETDPC: A Multimodality Framework for Classifying Pages in Electronic Theses and Dissertations
Nov 07, 2023



Electronic theses and dissertations (ETDs) have been proposed, advocated, and generated for more than 25 years. Although ETDs are hosted by commercial or institutional digital library repositories, they are still an understudied type of scholarly big data, partially because they are usually longer than conference proceedings and journals. Segmenting ETDs will allow researchers to study sectional content. Readers can navigate to particular pages of interest, discover, and explore the content buried in these long documents. Most existing frameworks on document page classification are designed for classifying general documents and perform poorly on ETDs. In this paper, we propose ETDPC. Its backbone is a two-stream multimodal model with a cross-attention network to classify ETD pages into 13 categories. To overcome the challenge of imbalanced labeled samples, we augmented data for minority categories and employed a hierarchical classifier. ETDPC outperforms the state-of-the-art models in all categories, achieving an F1 of 0.84 -- 0.96 for 9 out of 13 categories. We also demonstrated its data efficiency. The code and data can be found on GitHub (https://github.com/lamps-lab/ETDMiner/tree/master/etd_segmentation).
MetaEnhance: Metadata Quality Improvement for Electronic Theses and Dissertations of University Libraries
Mar 30, 2023



Metadata quality is crucial for digital objects to be discovered through digital library interfaces. However, due to various reasons, the metadata of digital objects often exhibits incomplete, inconsistent, and incorrect values. We investigate methods to automatically detect, correct, and canonicalize scholarly metadata, using seven key fields of electronic theses and dissertations (ETDs) as a case study. We propose MetaEnhance, a framework that utilizes state-of-the-art artificial intelligence methods to improve the quality of these fields. To evaluate MetaEnhance, we compiled a metadata quality evaluation benchmark containing 500 ETDs, by combining subsets sampled using multiple criteria. We tested MetaEnhance on this benchmark and found that the proposed methods achieved nearly perfect F1-scores in detecting errors and F1-scores in correcting errors ranging from 0.85 to 1.00 for five of seven fields.
Automatic Metadata Extraction Incorporating Visual Features from Scanned Electronic Theses and Dissertations
Jul 01, 2021



Electronic Theses and Dissertations (ETDs) contain domain knowledge that can be used for many digital library tasks, such as analyzing citation networks and predicting research trends. Automatic metadata extraction is important to build scalable digital library search engines. Most existing methods are designed for born-digital documents, so they often fail to extract metadata from scanned documents such as for ETDs. Traditional sequence tagging methods mainly rely on text-based features. In this paper, we propose a conditional random field (CRF) model that combines text-based and visual features. To verify the robustness of our model, we extended an existing corpus and created a new ground truth corpus consisting of 500 ETD cover pages with human validated metadata. Our experiments show that CRF with visual features outperformed both a heuristic and a CRF model with only text-based features. The proposed model achieved 81.3%-96% F1 measure on seven metadata fields. The data and source code are publicly available on Google Drive (https://tinyurl.com/y8kxzwrp) and a GitHub repository (https://github.com/lamps-lab/ETDMiner/tree/master/etd_crf), respectively.
ScanBank: A Benchmark Dataset for Figure Extraction from Scanned Electronic Theses and Dissertations
Jun 23, 2021
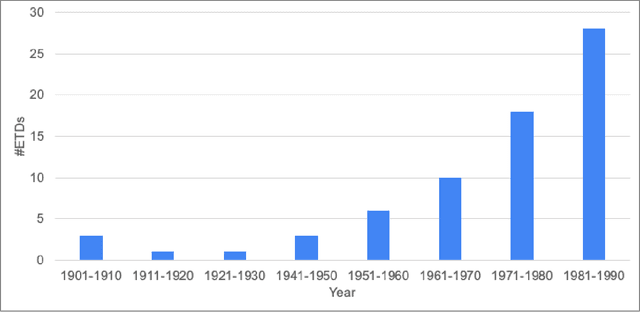


We focus on electronic theses and dissertations (ETDs), aiming to improve access and expand their utility, since more than 6 million are publicly available, and they constitute an important corpus to aid research and education across disciplines. The corpus is growing as new born-digital documents are included, and since millions of older theses and dissertations have been converted to digital form to be disseminated electronically in institutional repositories. In ETDs, as with other scholarly works, figures and tables can communicate a large amount of information in a concise way. Although methods have been proposed for extracting figures and tables from born-digital PDFs, they do not work well with scanned ETDs. Considering this problem, our assessment of state-of-the-art figure extraction systems is that the reason they do not function well on scanned PDFs is that they have only been trained on born-digital documents. To address this limitation, we present ScanBank, a new dataset containing 10 thousand scanned page images, manually labeled by humans as to the presence of the 3.3 thousand figures or tables found therein. We use this dataset to train a deep neural network model based on YOLOv5 to accurately extract figures and tables from scanned ETDs. We pose and answer important research questions aimed at finding better methods for figure extraction from scanned documents. One of those concerns the value for training, of data augmentation techniques applied to born-digital documents which are used to train models better suited for figure extraction from scanned documents. To the best of our knowledge, ScanBank is the first manually annotated dataset for figure and table extraction for scanned ETDs. A YOLOv5-based model, trained on ScanBank, outperforms existing comparable open-source and freely available baseline methods by a considerable margin.