 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Pavement Crack Classification with Bidirectional Cascaded Neural Networks
Mar 27, 2025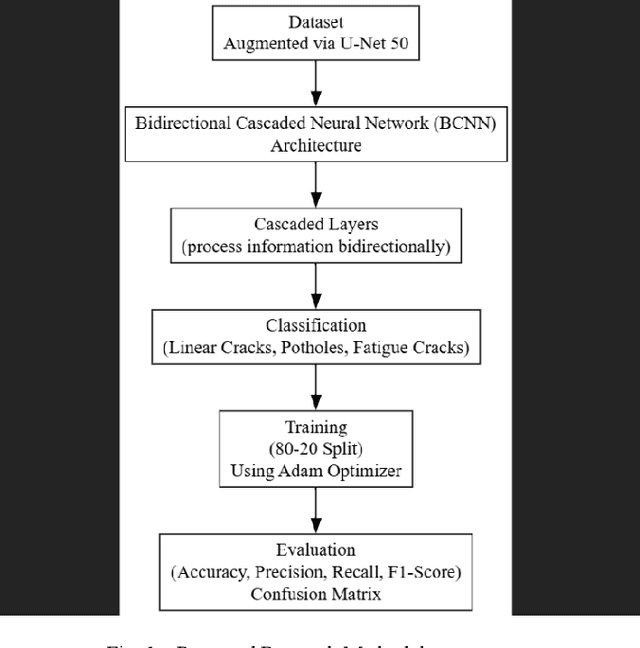

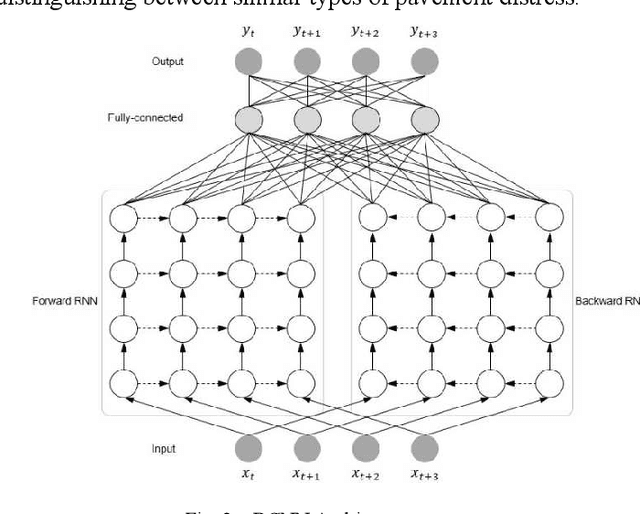
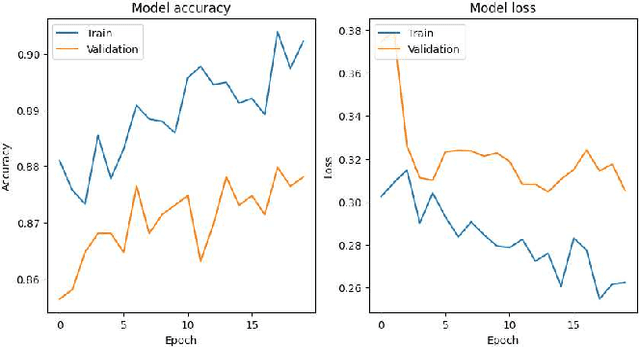
Pavement distress, such as cracks and potholes, is a significant issue affecting road safety and maintenance. In this study, we present the implementation and evaluation of Bidirectional Cascaded Neural Networks (BCNNs) for the classification of pavement crack images following image augmentation. We classified pavement cracks into three main categories: linear cracks, potholes, and fatigue cracks on an enhanced dataset utilizing U-Net 50 for image augmentation. The augmented dataset comprised 599 images. Our proposed BCNN model was designed to leverage both forward and backward information flows, with detection accuracy enhanced by its cascaded structure wherein each layer progressively refines the output of the preceding one. Our model achieved an overall accuracy of 87%, with precision, recall, and F1-score measures indicating high effectiveness across the categories. For fatigue cracks, the model recorded a precision of 0.87, recall of 0.83, and F1-score of 0.85 on 205 images. Linear cracks were detected with a precision of 0.81, recall of 0.89, and F1-score of 0.85 on 205 images, and potholes with a precision of 0.96, recall of 0.90, and F1-score of 0.93 on 189 images. The macro and weighted average of precision, recall, and F1-score were identical at 0.88, confirming the BCNN's excellent performance in classifying complex pavement crack patterns. This research demonstrates the potential of BCNNs to significantly enhance the accuracy and reliability of pavement distress classification, resulting in more effective and efficient pavement maintenance and management systems.
Visual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
Jun 26, 2024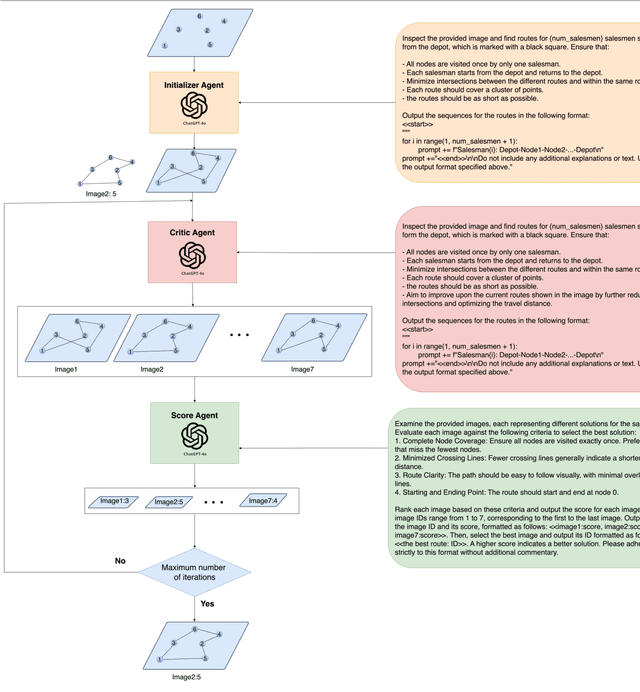
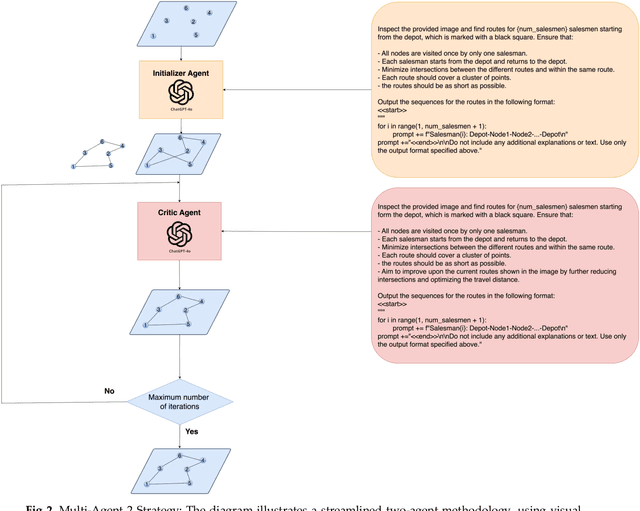
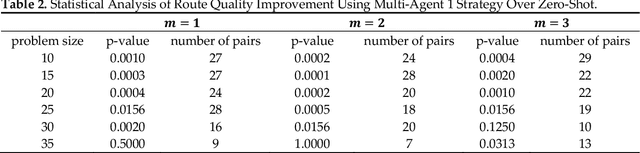
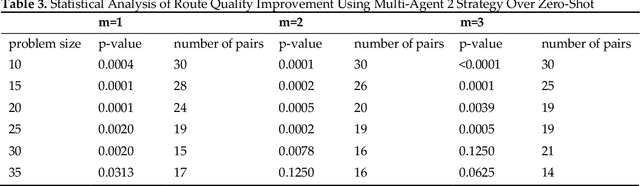
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems, including zero-shot in-context learning scenarios. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. Our experimental investigation includes rigorous evaluations across zero-shot settings and introduces innovative multi-agent zero-shot in-context scenarios. The results demonstrated that both multi-agent models. Multi-Agent 1, which includes the Initializer, Critic, and Scorer agents, and Multi-Agent 2, which comprises only the Initializer and Critic agents; significantly improved solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the Initializer and Critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field. Project link: https://github.com/ahmed-abdulhuy/Solving-TSP-and-mTSP-Combinatorial-Challenges-using-Visual-Reasoning-and-Multi-Agent-Approach-MLLMs-.git
Object Detection using Oriented Window Learning Vi-sion Transformer: Roadway Assets Recognition
Jun 15, 2024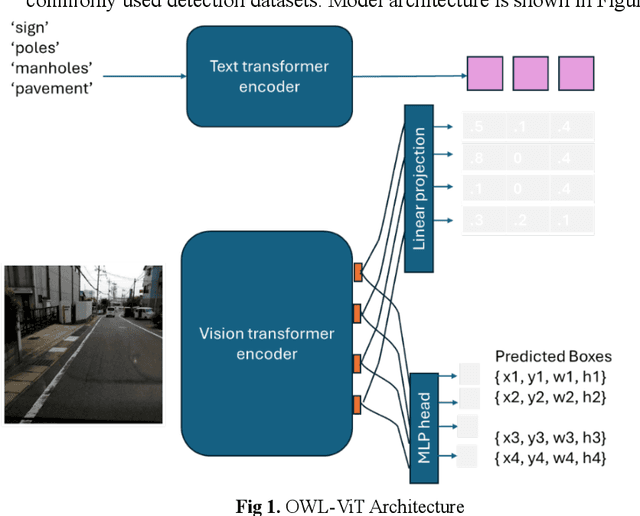
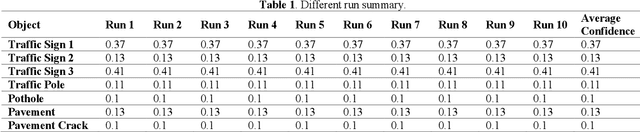
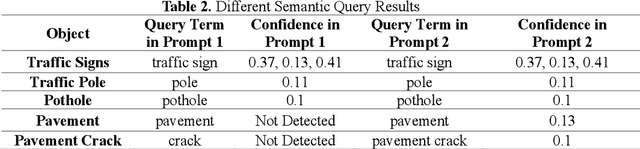

Object detection is a critical component of transportation systems, particularly for applications such as autonomous driving, traffic monitoring, and infrastructure maintenance. Traditional object detection methods often struggle with limited data and variability in object appearance. The Oriented Window Learning Vision Transformer (OWL-ViT) offers a novel approach by adapting window orientations to the geometry and existence of objects, making it highly suitable for detecting diverse roadway assets. This study leverages OWL-ViT within a one-shot learning framework to recognize transportation infrastructure components, such as traffic signs, poles, pavement, and cracks. This study presents a novel method for roadway asset detection using OWL-ViT. We conducted a series of experiments to evaluate the performance of the model in terms of detection consistency, semantic flexibility, visual context adaptability, resolution robustness, and impact of non-max suppression. The results demonstrate the high efficiency and reliability of the OWL-ViT across various scenarios, underscoring its potential to enhance the safety and efficiency of intelligent transportation systems.
Exploring Traffic Crash Narratives in Jordan Using Text Mining Analytics
Jun 11, 2024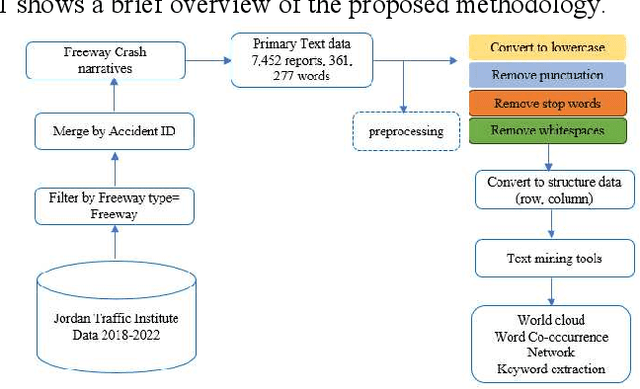
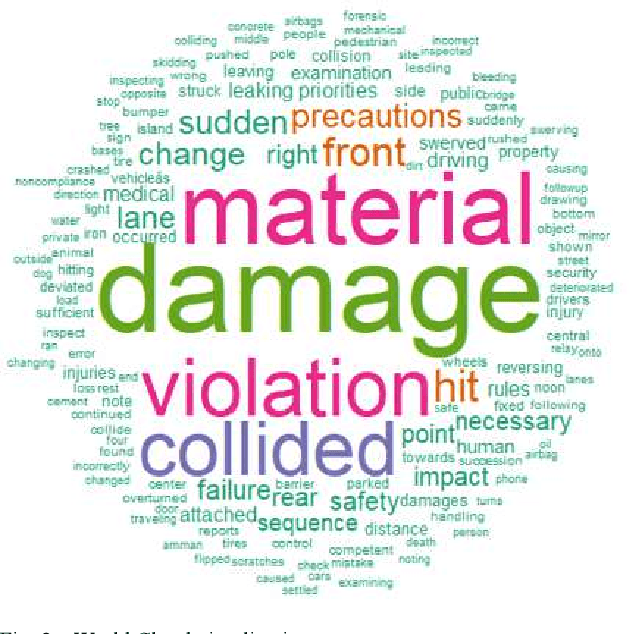
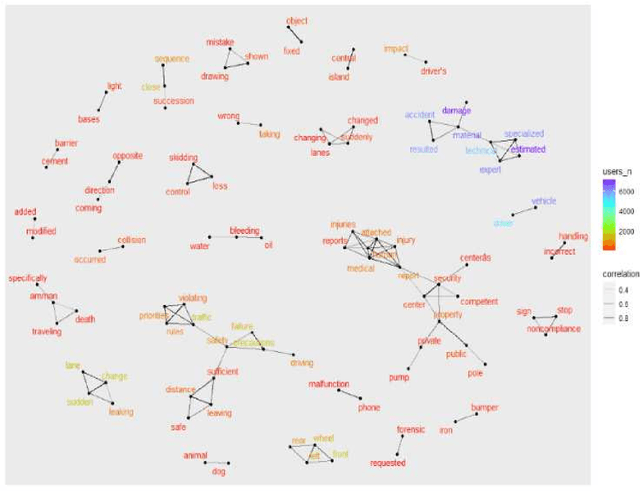
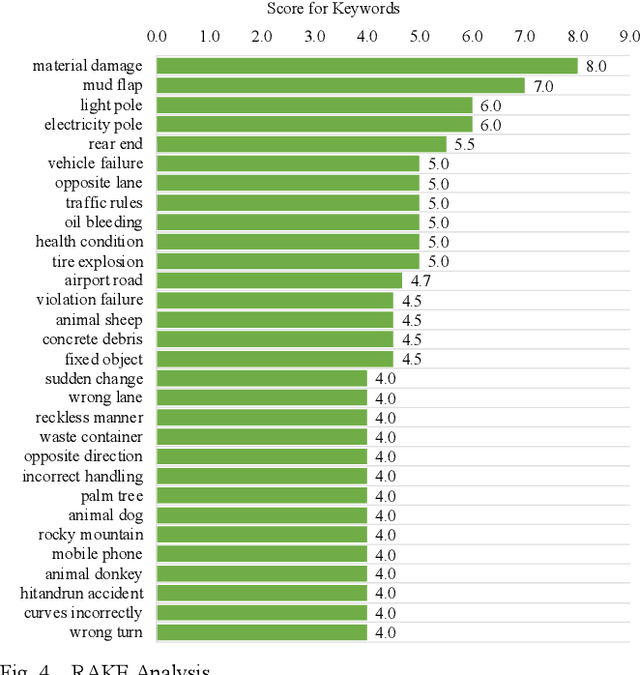
This study explores traffic crash narratives in an attempt to inform and enhance effective traffic safety policies using text-mining analytics. Text mining techniques are employed to unravel key themes and trends within the narratives, aiming to provide a deeper understanding of the factors contributing to traffic crashes. This study collected crash data from five major freeways in Jordan that cover narratives of 7,587 records from 2018-2022. An unsupervised learning method was adopted to learn the pattern from crash data. Various text mining techniques, such as topic modeling, keyword extraction, and Word Co-Occurrence Network, were also used to reveal the co-occurrence of crash patterns. Results show that text mining analytics is a promising method and underscore the multifactorial nature of traffic crashes, including intertwining human decisions and vehicular conditions. The recurrent themes across all analyses highlight the need for a balanced approach to road safety, merging both proactive and reactive measures. Emphasis on driver education and awareness around animal-related incidents is paramount.
Eyeballing Combinatorial Problems: A Case Study of Using Multimodal Large Language Models to Solve Traveling Salesman Problems
Jun 11, 2024



Multimodal Large Language Models (MLLMs) have demonstrated proficiency in processing di-verse modalities, including text, images, and audio. These models leverage extensive pre-existing knowledge, enabling them to address complex problems with minimal to no specific training examples, as evidenced in few-shot and zero-shot in-context learning scenarios. This paper investigates the use of MLLMs' visual capabilities to 'eyeball' solutions for the Traveling Salesman Problem (TSP) by analyzing images of point distributions on a two-dimensional plane. Our experiments aimed to validate the hypothesis that MLLMs can effectively 'eyeball' viable TSP routes. The results from zero-shot, few-shot, self-ensemble, and self-refine zero-shot evaluations show promising outcomes. We anticipate that these findings will inspire further exploration into MLLMs' visual reasoning abilities to tackle other combinatorial problems.