 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing
Paper and Code
Sep 26, 2024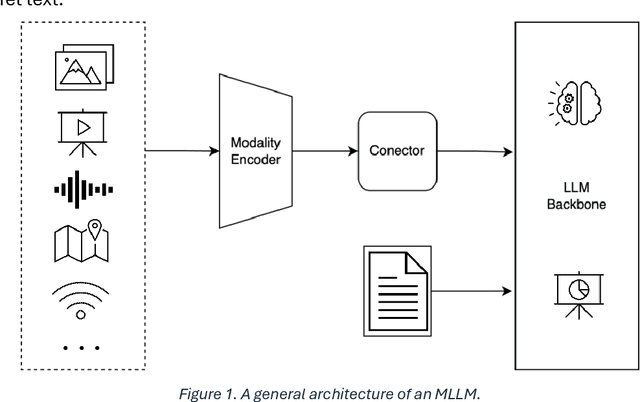
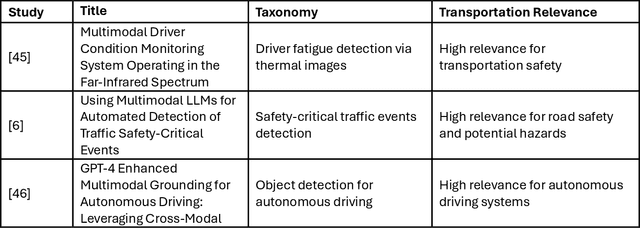
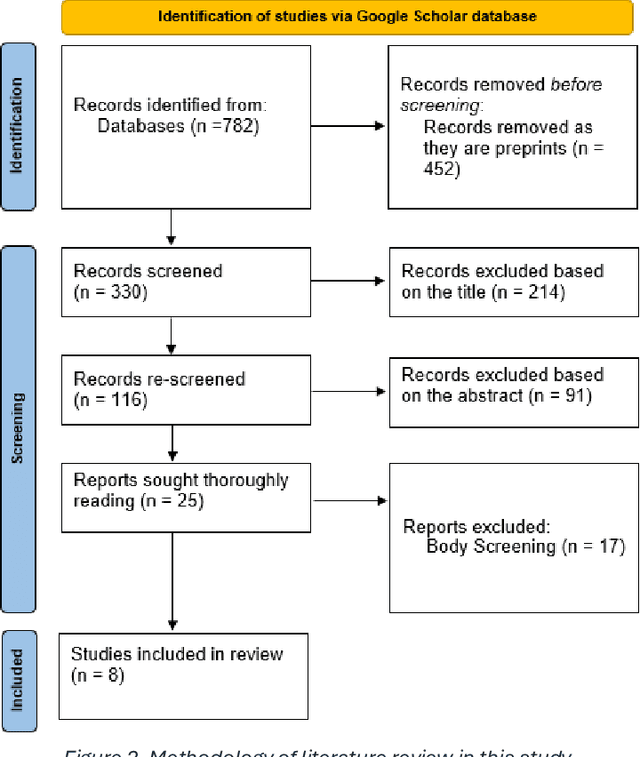
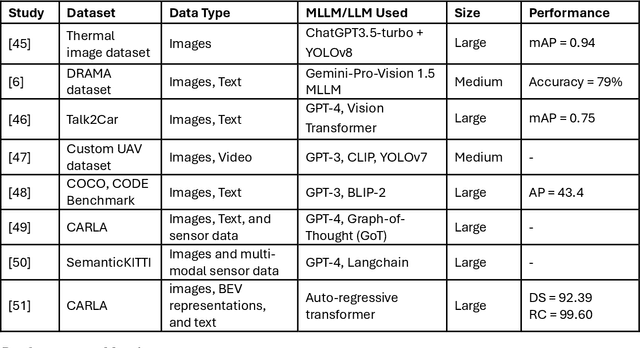
This study aims to comprehensively review and empirically evaluate the application of multimodal large language models (MLLMs) and Large Vision Models (VLMs) in object detection for transportation systems. In the first fold, we provide a background about the potential benefits of MLLMs in transportation applications and conduct a comprehensive review of current MLLM technologies in previous studies. We highlight their effectiveness and limitations in object detection within various transportation scenarios. The second fold involves providing an overview of the taxonomy of end-to-end object detection in transportation applications and future directions. Building on this, we proposed empirical analysis for testing MLLMs on three real-world transportation problems that include object detection tasks namely, road safety attributes extraction, safety-critical event detection, and visual reasoning of thermal images. Our findings provide a detailed assessment of MLLM performance, uncovering both strengths and areas for improvement. Finally, we discuss practical limitations and challenges of MLLMs in enhancing object detection in transportation, thereby offering a roadmap for future research and development in this critical area.