 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models Meet Network Management: Improving Traffic Matrix Analysis with Diffusion-based Approach
Nov 29, 2024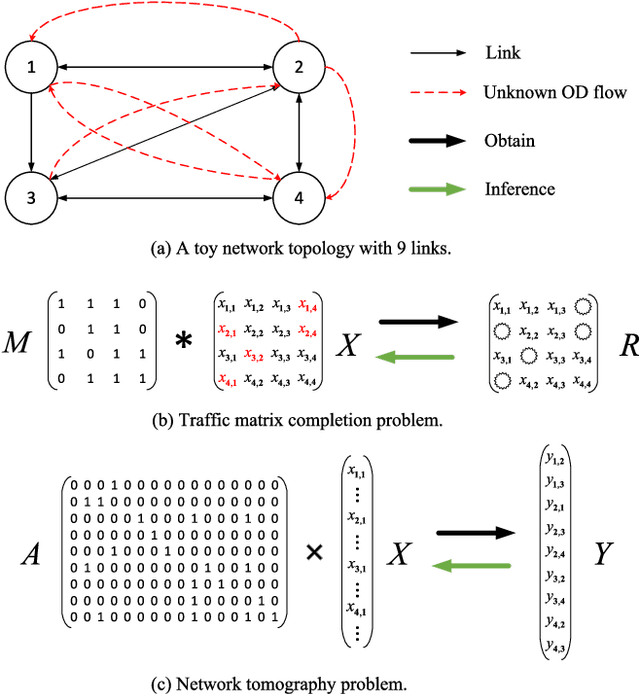
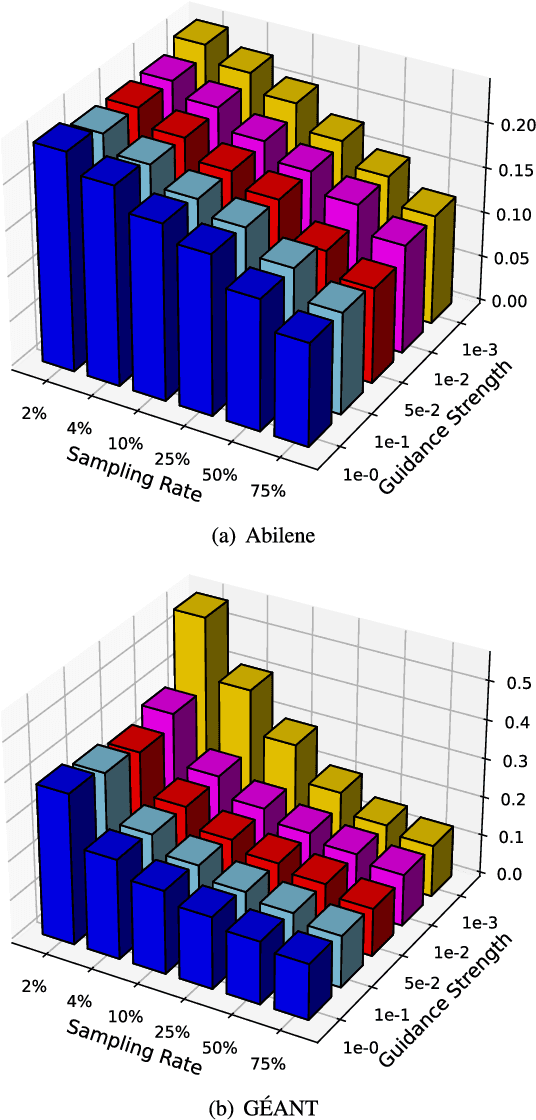
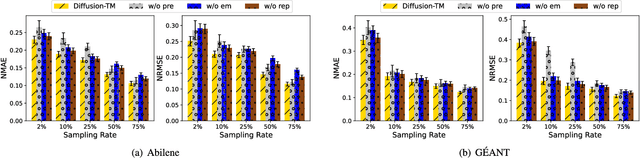
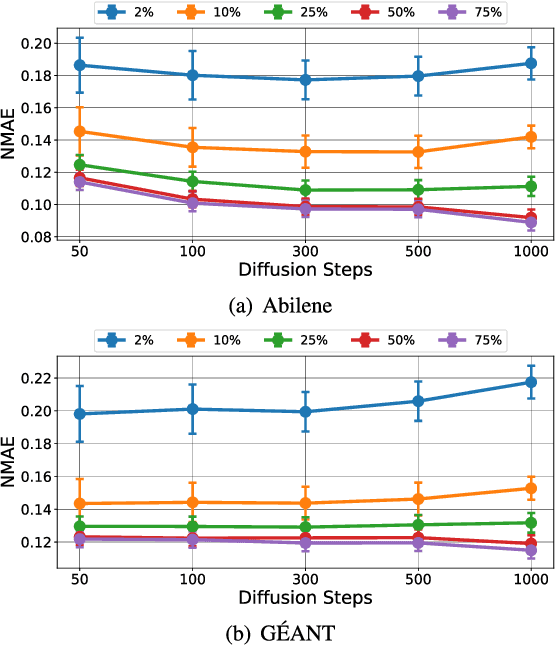
Due to network operation and maintenance relying heavily on network traffic monitoring, traffic matrix analysis has been one of the most crucial issues for network management related tasks. However, it is challenging to reliably obtain the precise measurement in computer networks because of the high measurement cost, and the unavoidable transmission loss. Although some methods proposed in recent years allowed estimating network traffic from partial flow-level or link-level measurements, they often perform poorly for traffic matrix estimation nowadays. Despite strong assumptions like low-rank structure and the prior distribution, existing techniques are usually task-specific and tend to be significantly worse as modern network communication is extremely complicated and dynamic. To address the dilemma, this paper proposed a diffusion-based traffic matrix analysis framework named Diffusion-TM, which leverages problem-agnostic diffusion to notably elevate the estimation performance in both traffic distribution and accuracy. The novel framework not only takes advantage of the powerful generative ability of diffusion models to produce realistic network traffic, but also leverages the denoising process to unbiasedly estimate all end-to-end traffic in a plug-and-play manner under theoretical guarantee. Moreover, taking into account that compiling an intact traffic dataset is usually infeasible, we also propose a two-stage training scheme to make our framework be insensitive to missing values in the dataset. With extensive experiments with real-world datasets, we illustrate the effectiveness of Diffusion-TM on several tasks. Moreover, the results also demonstrate that our method can obtain promising results even with $5\%$ known values left in the datasets.
Traffic Matrix Estimation based on Denoising Diffusion Probabilistic Model
Oct 21, 2024



The traffic matrix estimation (TME) problem has been widely researched for decades of years. Recent progresses in deep generative models offer new opportunities to tackle TME problems in a more advanced way. In this paper, we leverage the powerful ability of denoising diffusion probabilistic models (DDPMs) on distribution learning, and for the first time adopt DDPM to address the TME problem. To ensure a good performance of DDPM on learning the distributions of TMs, we design a preprocessing module to reduce the dimensions of TMs while keeping the data variety of each OD flow. To improve the estimation accuracy, we parameterize the noise factors in DDPM and transform the TME problem into a gradient-descent optimization problem. Finally, we compared our method with the state-of-the-art TME methods using two real-world TM datasets, the experimental results strongly demonstrate the superiority of our method on both TM synthesis and TM estimation.
A Real-Time Voice Activity Detection Based On Lightweight Neural
May 27, 2024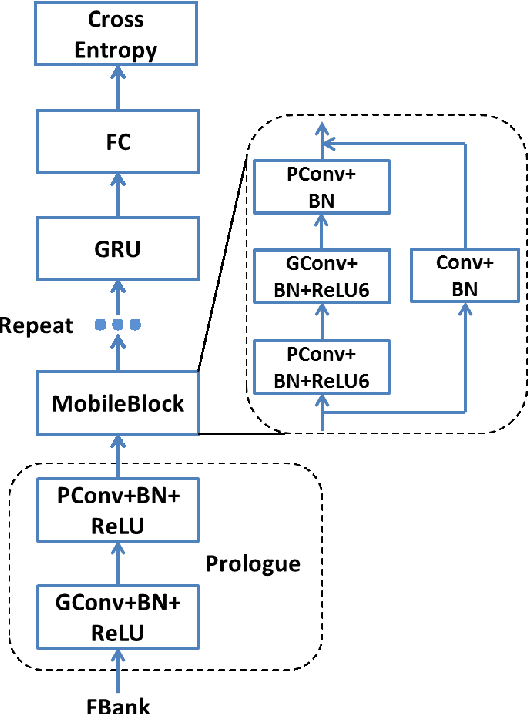
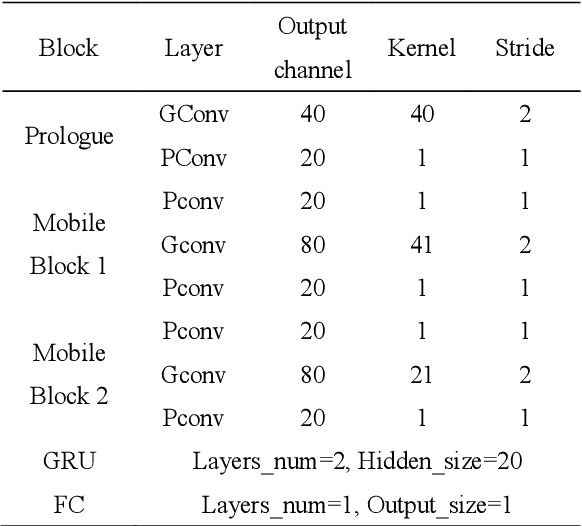

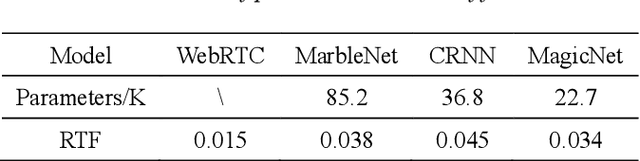
Voice activity detection (VAD) is the task of detecting speech in an audio stream, which is challenging due to numerous unseen noises and low signal-to-noise ratios in real environments. Recently, neural network-based VADs have alleviated the degradation of performance to some extent. However, the majority of existing studies have employed excessively large models and incorporated future context, while neglecting to evaluate the operational efficiency and latency of the models. In this paper, we propose a lightweight and real-time neural network called MagicNet, which utilizes casual and depth separable 1-D convolutions and GRU. Without relying on future features as input, our proposed model is compared with two state-of-the-art algorithms on synthesized in-domain and out-domain test datasets. The evaluation results demonstrate that MagicNet can achieve improved performance and robustness with fewer parameter costs.
Competitive Wakeup Scheme for Distributed Devices
May 19, 2020



Wakeup is the primary function in voice interaction which is the mainstream scheme in man-machine interaction (HMI) applications for smart home. All devices will response if the same wake-up word is used for all devices. This will bring chaos and reduce user quality of experience (QoE). The only way to solve this problem is to make all the devices in the same wireless local area network (WLAN) competing to wake-up based on the same scoring rule. The one closest to the user would be selected for response. To this end, a competitive wakeup scheme is proposed in this paper with elaborately designed calibration method for receiving energy of microphones. Moreover, the user orientation is assisted to determine the optimal device. Experiments reveal the feasibility and validity of this scheme.
A Lite Microphone Array Beamforming Scheme with Maximum Signal-to-Noise Ratio Filter
May 19, 2020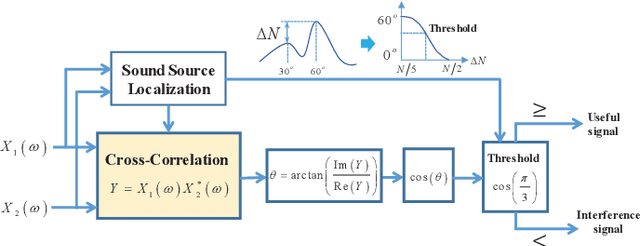
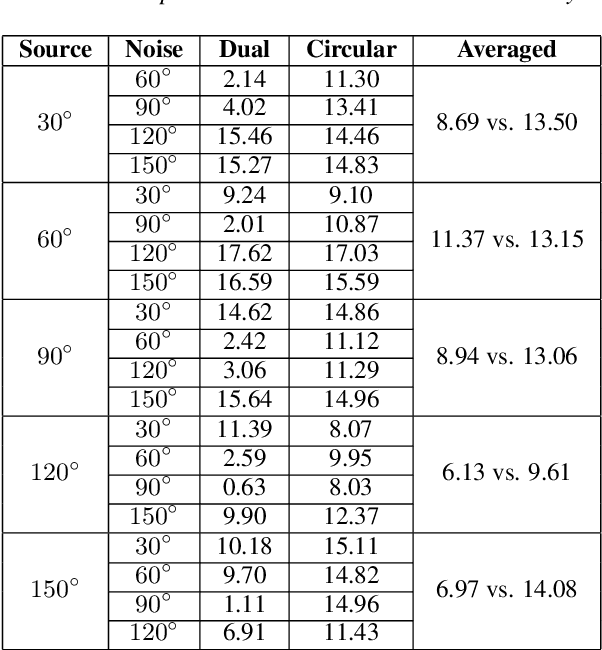
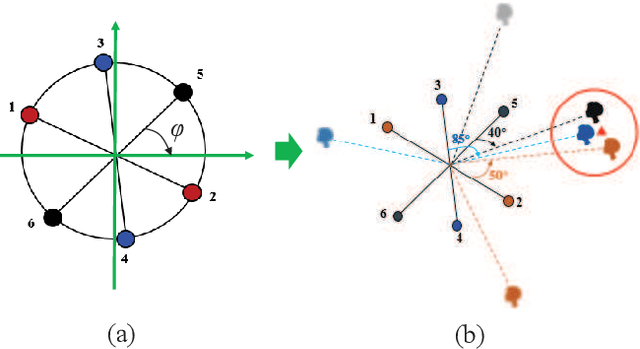
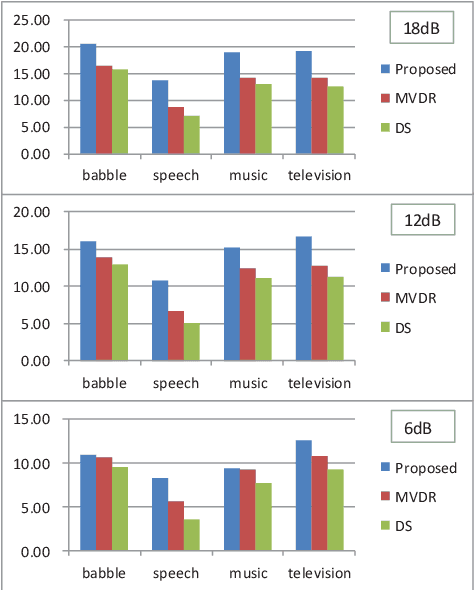
Since space-domain information can be utilized, microphone array beamforming is often used to enhance the quality of the speech by suppressing directional disturbance. However, with the increasing number of microphone, the complexity would be increased. In this paper, a concise beamforming scheme using Maximum Signal-to-Noise Ratio (SNR) filter is proposed to reduce the beamforming complexity. The maximum SNR filter is implemented by using the estimated direction-of-arrival (DOA) of the speech source localization (SSL) and the solving method of independent vector analysis (IVA). Our experiments show that when compared with other widely-used algorithms, the proposed algorithm obtain higher gain of signal-to-interference and noise ratio (SINR).
Acoustic Echo Cancellation by Combining Adaptive Digital Filter and Recurrent Neural Network
May 19, 2020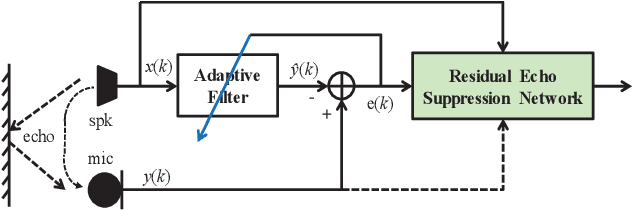
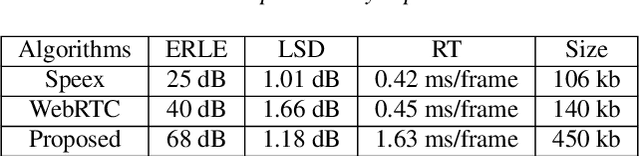
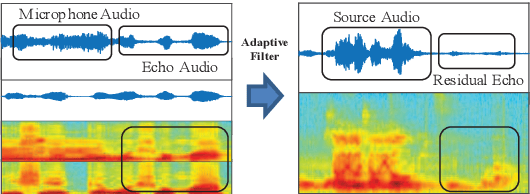
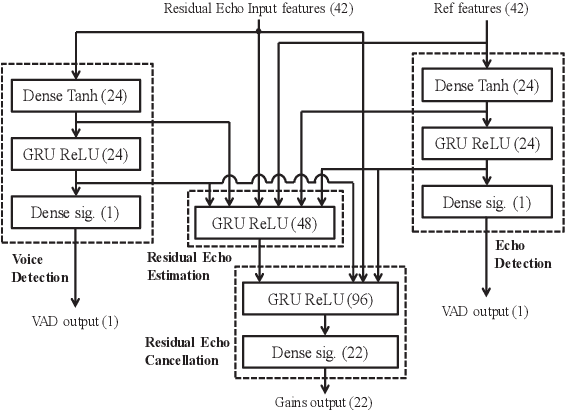
Acoustic Echo Cancellation (AEC) plays a key role in voice interaction. Due to the explicit mathematical principle and intelligent nature to accommodate conditions, adaptive filters with different types of implementations are always used for AEC, giving considerable performance. However, there would be some kinds of residual echo in the results, including linear residue introduced by mismatching between estimation and the reality and non-linear residue mostly caused by non-linear components on the audio devices. The linear residue can be reduced with elaborate structure and methods, leaving the non-linear residue intractable for suppression. Though, some non-linear processing methods have already be raised, they are complicated and inefficient for suppression, and would bring damage to the speech audio. In this paper, a fusion scheme by combining adaptive filter and neural network is proposed for AEC. The echo could be reduced in a large scale by adaptive filtering, resulting in little residual echo. Though it is much smaller than speech audio, it could also be perceived by human ear and would make communication annoy. The neural network is elaborately designed and trained for suppressing such residual echo. Experiments compared with prevailing methods are conducted, validating the effectiveness and superiority of the proposed combination scheme.