 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWADEPre: A Wavelet-based Decomposition Model for Extreme Precipitation Nowcasting with Multi-Scale Learning
Feb 02, 2026The heavy-tailed nature of precipitation intensity impedes precise precipitation nowcasting. Standard models that optimize pixel-wise losses are prone to regression-to-the-mean bias, which blurs extreme values. Existing Fourier-based methods also lack the spatial localization needed to resolve transient convective cells. To overcome these intrinsic limitations, we propose WADEPre, a wavelet-based decomposition model for extreme precipitation that transitions the modeling into the wavelet domain. By leveraging the Discrete Wavelet Transform for explicit decomposition, WADEPre employs a dual-branch architecture: an Approximation Network to model stable, low-frequency advection, isolating deterministic trends from statistical bias, and a spatially localized Detail Network to capture high-frequency stochastic convection, resolving transient singularities and preserving sharp boundaries. A subsequent Refiner module then dynamically reconstructs these decoupled multi-scale components into the final high-fidelity forecast. To address optimization instability, we introduce a multi-scale curriculum learning strategy that progressively shifts supervision from coarse scales to fine-grained details. Extensive experiments on the SEVIR and Shanghai Radar datasets demonstrate that WADEPre achieves state-of-the-art performance, yielding significant improvements in capturing extreme thresholds and maintaining structural fidelity. Our code is available at https://github.com/sonderlau/WADEPre.
Gradient Amplification: An efficient way to train deep neural networks
Jun 16, 2020
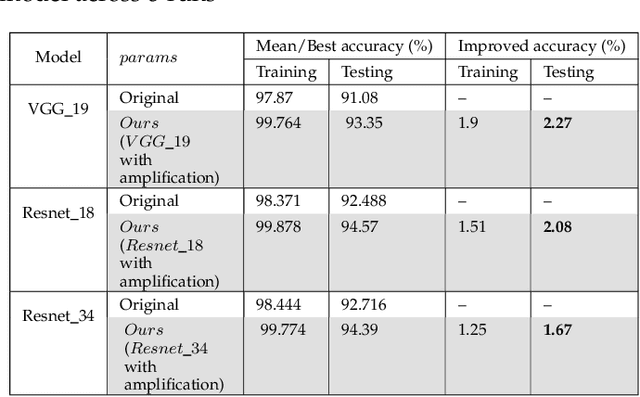

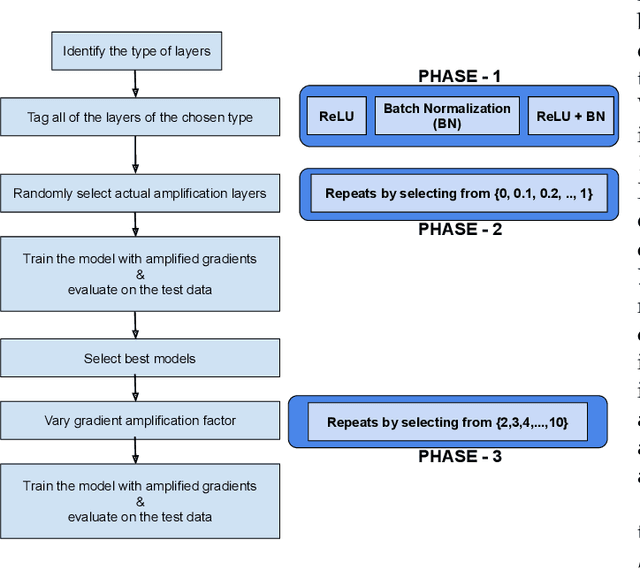
Improving performance of deep learning models and reducing their training times are ongoing challenges in deep neural networks. There are several approaches proposed to address these challenges one of which is to increase the depth of the neural networks. Such deeper networks not only increase training times, but also suffer from vanishing gradients problem while training. In this work, we propose gradient amplification approach for training deep learning models to prevent vanishing gradients and also develop a training strategy to enable or disable gradient amplification method across several epochs with different learning rates. We perform experiments on VGG-19 and resnet (Resnet-18 and Resnet-34) models, and study the impact of amplification parameters on these models in detail. Our proposed approach improves performance of these deep learning models even at higher learning rates, thereby allowing these models to achieve higher performance with reduced training time.
* 9 page document with 7 figures and one results table
Competitive Wakeup Scheme for Distributed Devices
May 19, 2020



Wakeup is the primary function in voice interaction which is the mainstream scheme in man-machine interaction (HMI) applications for smart home. All devices will response if the same wake-up word is used for all devices. This will bring chaos and reduce user quality of experience (QoE). The only way to solve this problem is to make all the devices in the same wireless local area network (WLAN) competing to wake-up based on the same scoring rule. The one closest to the user would be selected for response. To this end, a competitive wakeup scheme is proposed in this paper with elaborately designed calibration method for receiving energy of microphones. Moreover, the user orientation is assisted to determine the optimal device. Experiments reveal the feasibility and validity of this scheme.