 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovid-19 Detection from Chest X-ray and Patient Metadata using Graph Convolutional Neural Networks
May 21, 2021
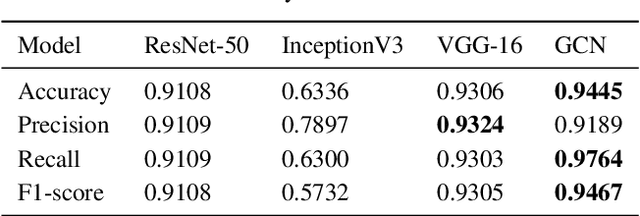
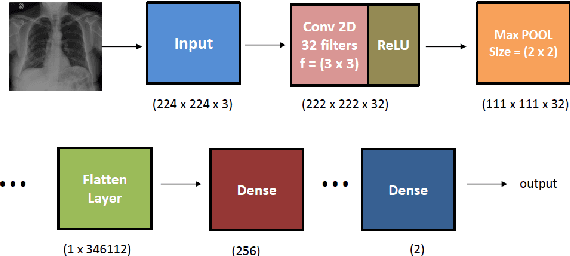
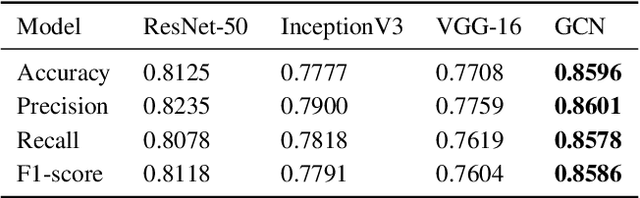
The novel corona virus (Covid-19) has introduced significant challenges due to its rapid spreading nature through respiratory transmission. As a result, there is a huge demand for Artificial Intelligence (AI) based quick disease diagnosis methods as an alternative to high demand tests such as Polymerase Chain Reaction (PCR). Chest X-ray (CXR) Image analysis is such cost-effective radiography technique due to resource availability and quick screening. But, a sufficient and systematic data collection that is required by complex deep leaning (DL) models is more difficult and hence there are recent efforts that utilize transfer learning to address this issue. Still these transfer learnt models suffer from lack of generalization and increased bias to the training dataset resulting poor performance for unseen data. Limited correlation of the transferred features from the pre-trained model to a specific medical imaging domain like X-ray and overfitting on fewer data can be reasons for this circumstance. In this work, we propose a novel Graph Convolution Neural Network (GCN) that is capable of identifying bio-markers of Covid-19 pneumonia from CXR images and meta information about patients. The proposed method exploits important relational knowledge between data instances and their features using graph representation and applies convolution to learn the graph data which is not possible with conventional convolution on Euclidean domain. The results of extensive experiments of proposed model on binary (Covid vs normal) and three class (Covid, normal, other pneumonia) classification problems outperform different benchmark transfer learnt models, hence overcoming the aforementioned drawbacks.
Infant Vocal Tract Development Analysis and Diagnosis by Cry Signals with CNN Age Classification
Apr 23, 2021
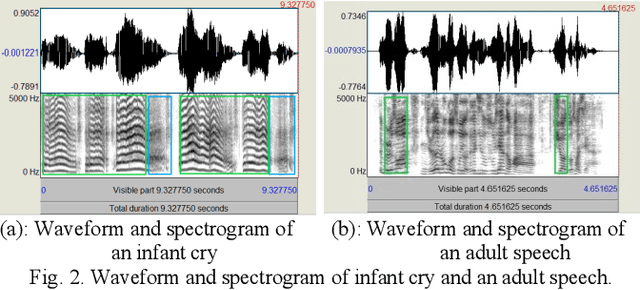
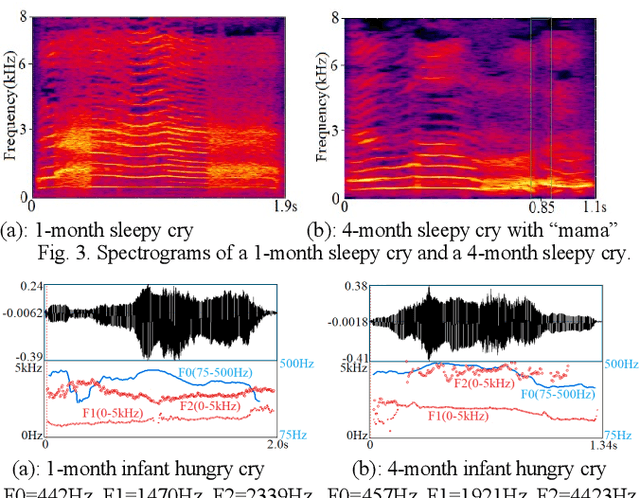
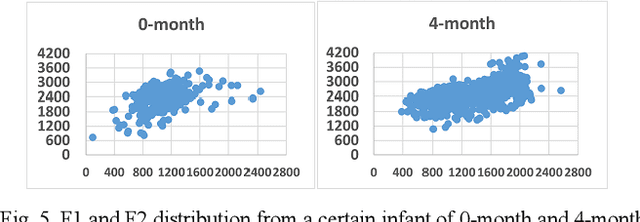
From crying to babbling and then to speech, infant's vocal tract goes through anatomic restructuring. In this paper, we propose a non-invasive fast method of using infant cry signals with convolutional neural network (CNN) based age classification to diagnose the abnormality of the vocal tract development as early as 4-month age. We study F0, F1, F2, and spectrograms and relate them to the postnatal development of infant vocalization. A novel CNN based age classification is performed with binary age pairs to discover the pattern and tendency of the vocal tract changes. The effectiveness of this approach is evaluated on Baby2020 with healthy infant cries and Baby Chillanto database with pathological infant cries. The results show that our approach yields 79.20% accuracy for healthy cries, 84.80% for asphyxiated cries, and 91.20% for deaf cries. Our method first reveals that infants' vocal tract develops to a certain level at 4-month age and infants can start controlling the vocal folds to produce discontinuous cry sounds leading to babbling. Early diagnosis of growth abnormality of the vocal tract can help parents keep vigilant and adopt medical treatment or training therapy for their infants as early as possible.
Infant Cry Classification with Graph Convolutional Networks
Jan 31, 2021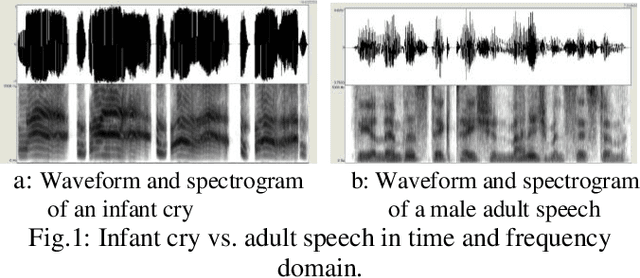
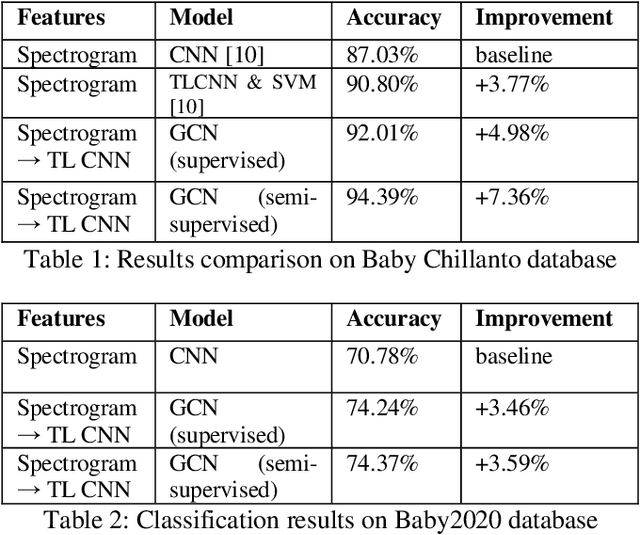

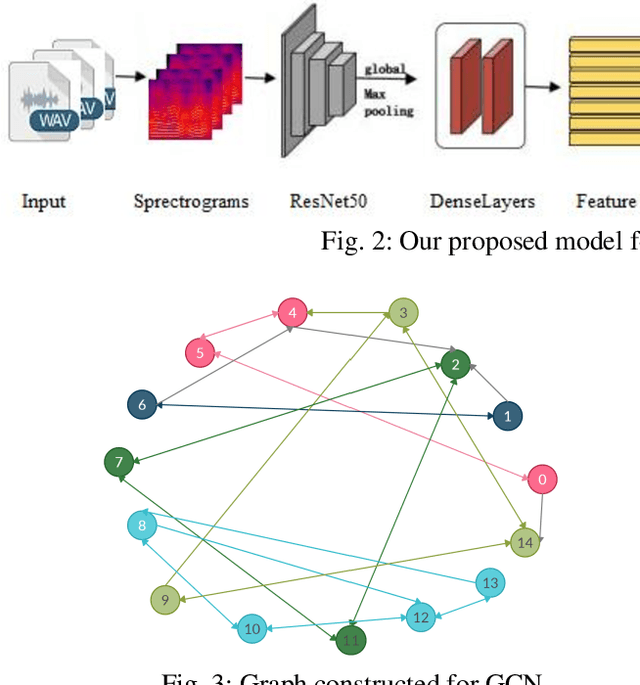
We propose an approach of graph convolutional networks for robust infant cry classification. We construct non-fully connected graphs based on the similarities among the relevant nodes in both supervised and semi-supervised node classification with convolutional neural networks to consider the short-term and long-term effects of infant cry signals related to inner-class and inter-class messages. The approach captures the diversity of variations within infant cries, especially for limited training samples. The effectiveness of this approach is evaluated on Baby Chillanto Database and Baby2020 database. With as limited as 20% of labeled training data, our model outperforms that of CNN model with 80% labeled training data and the accuracy stably improves as the number of labeled training samples increases. The best results give significant improvements of 7.36% and 3.59% compared with the results of the CNN models on Baby Chillanto database and Baby2020 database respectively.
PK-GCN: Prior Knowledge Assisted Image Classification using Graph Convolution Networks
Sep 24, 2020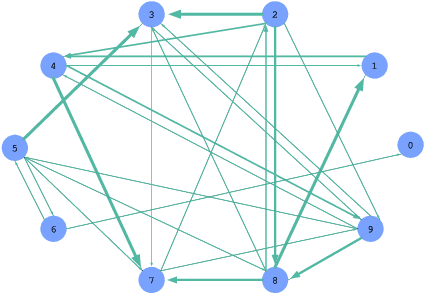
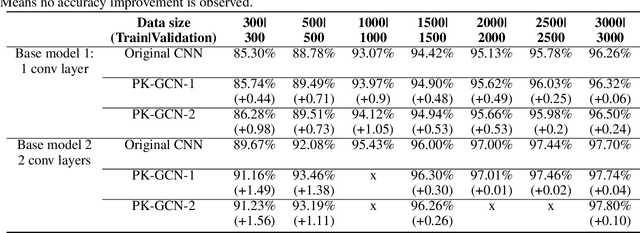
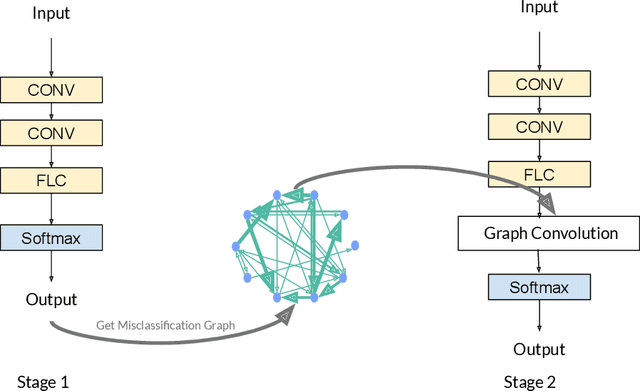
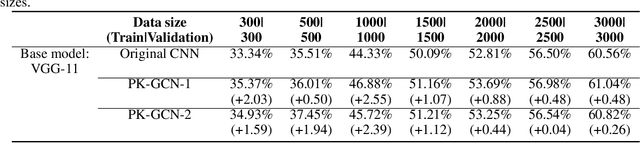
Deep learning has gained great success in various classification tasks. Typically, deep learning models learn underlying features directly from data, and no underlying relationship between classes are included. Similarity between classes can influence the performance of classification. In this article, we propose a method that incorporates class similarity knowledge into convolutional neural networks models using a graph convolution layer. We evaluate our method on two benchmark image datasets: MNIST and CIFAR10, and analyze the results on different data and model sizes. Experimental results show that our model can improve classification accuracy, especially when the amount of available data is small.
Efficient Hyperparameter Optimization in Deep Learning Using a Variable Length Genetic Algorithm
Jun 23, 2020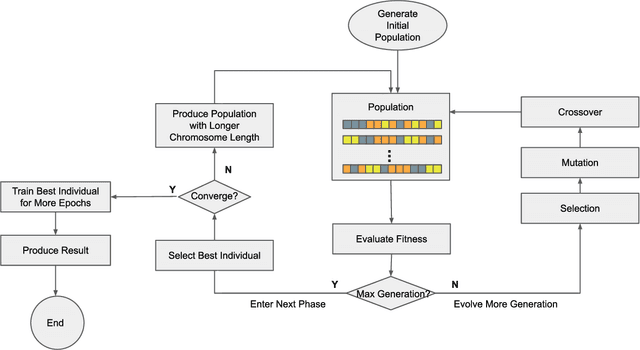
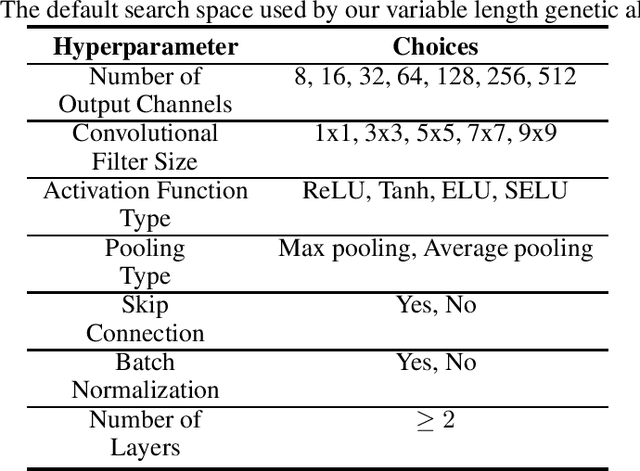

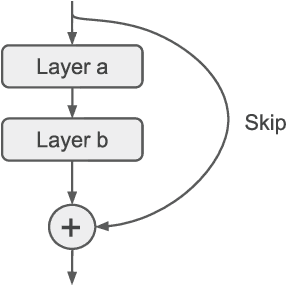
Convolutional Neural Networks (CNN) have gained great success in many artificial intelligence tasks. However, finding a good set of hyperparameters for a CNN remains a challenging task. It usually takes an expert with deep knowledge, and trials and errors. Genetic algorithms have been used in hyperparameter optimizations. However, traditional genetic algorithms with fixed-length chromosomes may not be a good fit for optimizing deep learning hyperparameters, because deep learning models have variable number of hyperparameters depending on the model depth. As the depth increases, the number of hyperparameters grows exponentially, and searching becomes exponentially harder. It is important to have an efficient algorithm that can find a good model in reasonable time. In this article, we propose to use a variable length genetic algorithm (GA) to systematically and automatically tune the hyperparameters of a CNN to improve its performance. Experimental results show that our algorithm can find good CNN hyperparameters efficiently. It is clear from our experiments that if more time is spent on optimizing the hyperparameters, better results could be achieved. Theoretically, if we had unlimited time and CPU power, we could find the optimized hyperparameters and achieve the best results in the future.
Gradient Amplification: An efficient way to train deep neural networks
Jun 16, 2020
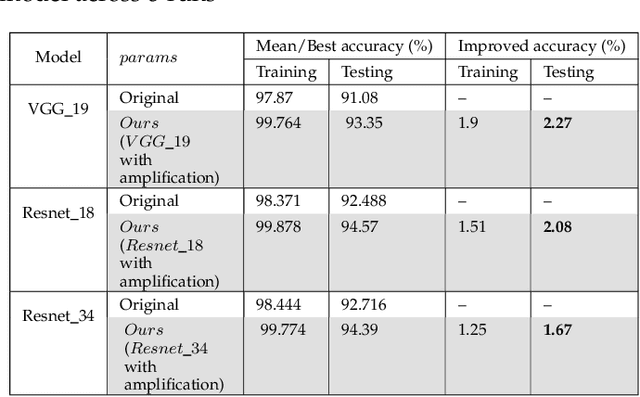

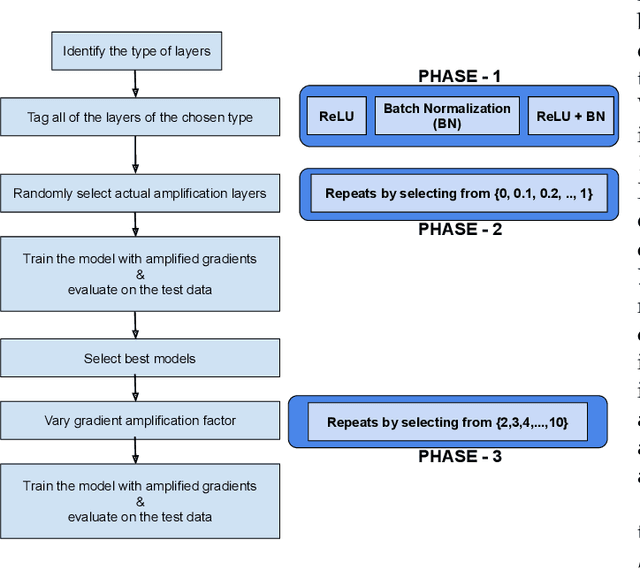
Improving performance of deep learning models and reducing their training times are ongoing challenges in deep neural networks. There are several approaches proposed to address these challenges one of which is to increase the depth of the neural networks. Such deeper networks not only increase training times, but also suffer from vanishing gradients problem while training. In this work, we propose gradient amplification approach for training deep learning models to prevent vanishing gradients and also develop a training strategy to enable or disable gradient amplification method across several epochs with different learning rates. We perform experiments on VGG-19 and resnet (Resnet-18 and Resnet-34) models, and study the impact of amplification parameters on these models in detail. Our proposed approach improves performance of these deep learning models even at higher learning rates, thereby allowing these models to achieve higher performance with reduced training time.
* 9 page document with 7 figures and one results table