 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent gradient amplification for deep neural networks
May 29, 2023Deep learning models offer superior performance compared to other machine learning techniques for a variety of tasks and domains, but pose their own challenges. In particular, deep learning models require larger training times as the depth of a model increases, and suffer from vanishing gradients. Several solutions address these problems independently, but there have been minimal efforts to identify an integrated solution that improves the performance of a model by addressing vanishing gradients, as well as accelerates the training process to achieve higher performance at larger learning rates. In this work, we intelligently determine which layers of a deep learning model to apply gradient amplification to, using a formulated approach that analyzes gradient fluctuations of layers during training. Detailed experiments are performed for simpler and deeper neural networks using two different intelligent measures and two different thresholds that determine the amplification layers, and a training strategy where gradients are amplified only during certain epochs. Results show that our amplification offers better performance compared to the original models, and achieves accuracy improvement of around 2.5% on CIFAR- 10 and around 4.5% on CIFAR-100 datasets, even when the models are trained with higher learning rates.
PK-GCN: Prior Knowledge Assisted Image Classification using Graph Convolution Networks
Sep 24, 2020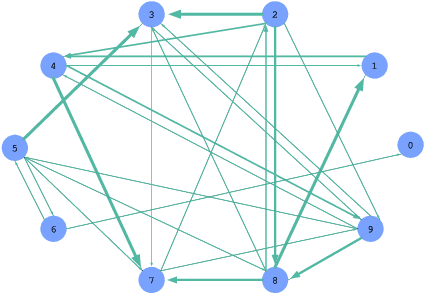
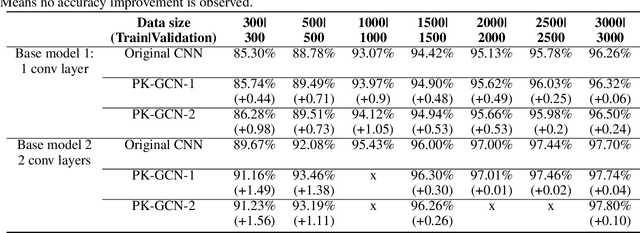
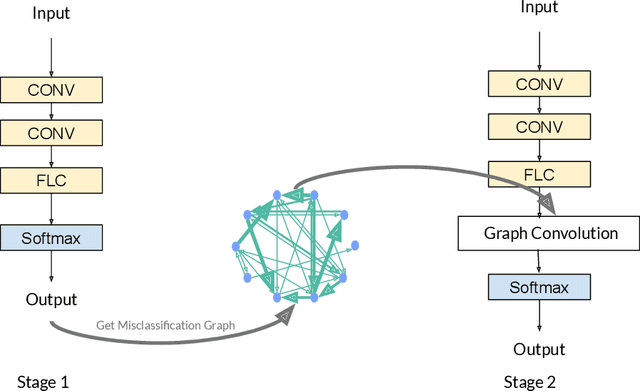
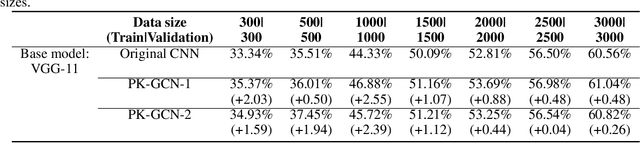
Deep learning has gained great success in various classification tasks. Typically, deep learning models learn underlying features directly from data, and no underlying relationship between classes are included. Similarity between classes can influence the performance of classification. In this article, we propose a method that incorporates class similarity knowledge into convolutional neural networks models using a graph convolution layer. We evaluate our method on two benchmark image datasets: MNIST and CIFAR10, and analyze the results on different data and model sizes. Experimental results show that our model can improve classification accuracy, especially when the amount of available data is small.
Deep Neural Networks with Short Circuits for Improved Gradient Learning
Sep 23, 2020
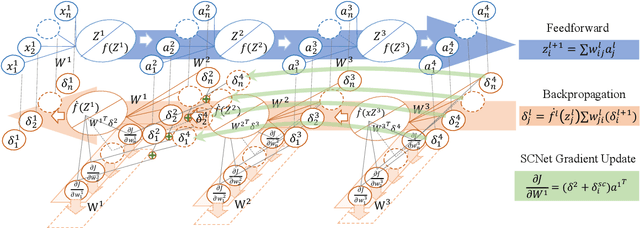
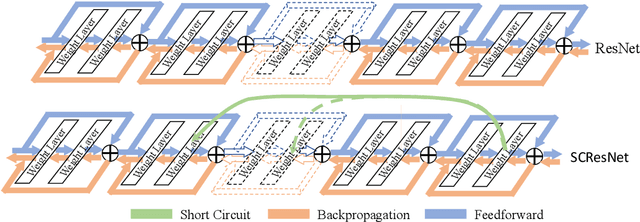
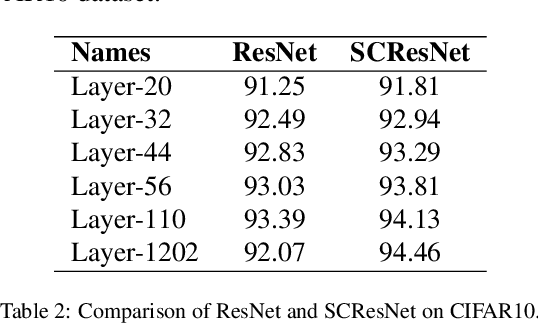
Deep neural networks have achieved great success both in computer vision and natural language processing tasks. However, mostly state-of-art methods highly rely on external training or computing to improve the performance. To alleviate the external reliance, we proposed a gradient enhancement approach, conducted by the short circuit neural connections, to improve the gradient learning of deep neural networks. The proposed short circuit is a unidirectional connection that single back propagates the sensitive from the deep layer to the shallows. Moreover, the short circuit formulates to be a gradient truncation of its crossing layers which can plug into the backbone deep neural networks without introducing external training parameters. Extensive experiments demonstrate deep neural networks with our short circuit gain a large margin over the baselines on both computer vision and natural language processing tasks.
Efficient Hyperparameter Optimization in Deep Learning Using a Variable Length Genetic Algorithm
Jun 23, 2020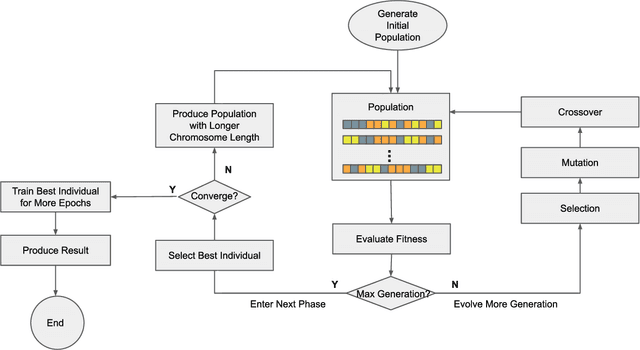
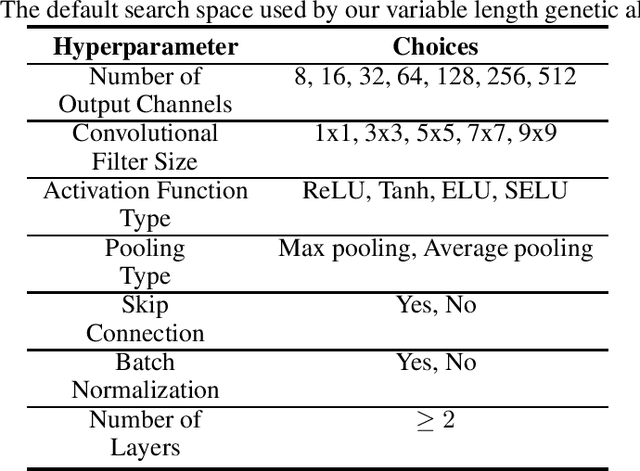

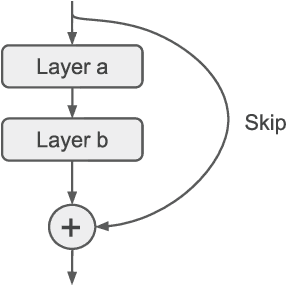
Convolutional Neural Networks (CNN) have gained great success in many artificial intelligence tasks. However, finding a good set of hyperparameters for a CNN remains a challenging task. It usually takes an expert with deep knowledge, and trials and errors. Genetic algorithms have been used in hyperparameter optimizations. However, traditional genetic algorithms with fixed-length chromosomes may not be a good fit for optimizing deep learning hyperparameters, because deep learning models have variable number of hyperparameters depending on the model depth. As the depth increases, the number of hyperparameters grows exponentially, and searching becomes exponentially harder. It is important to have an efficient algorithm that can find a good model in reasonable time. In this article, we propose to use a variable length genetic algorithm (GA) to systematically and automatically tune the hyperparameters of a CNN to improve its performance. Experimental results show that our algorithm can find good CNN hyperparameters efficiently. It is clear from our experiments that if more time is spent on optimizing the hyperparameters, better results could be achieved. Theoretically, if we had unlimited time and CPU power, we could find the optimized hyperparameters and achieve the best results in the future.