 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent gradient amplification for deep neural networks
May 29, 2023Deep learning models offer superior performance compared to other machine learning techniques for a variety of tasks and domains, but pose their own challenges. In particular, deep learning models require larger training times as the depth of a model increases, and suffer from vanishing gradients. Several solutions address these problems independently, but there have been minimal efforts to identify an integrated solution that improves the performance of a model by addressing vanishing gradients, as well as accelerates the training process to achieve higher performance at larger learning rates. In this work, we intelligently determine which layers of a deep learning model to apply gradient amplification to, using a formulated approach that analyzes gradient fluctuations of layers during training. Detailed experiments are performed for simpler and deeper neural networks using two different intelligent measures and two different thresholds that determine the amplification layers, and a training strategy where gradients are amplified only during certain epochs. Results show that our amplification offers better performance compared to the original models, and achieves accuracy improvement of around 2.5% on CIFAR- 10 and around 4.5% on CIFAR-100 datasets, even when the models are trained with higher learning rates.
Efficient Hyperparameter Optimization in Deep Learning Using a Variable Length Genetic Algorithm
Jun 23, 2020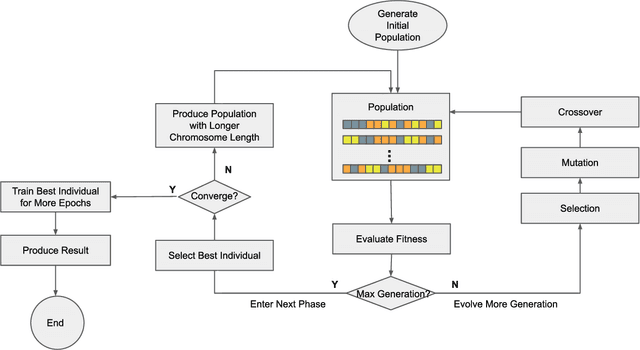
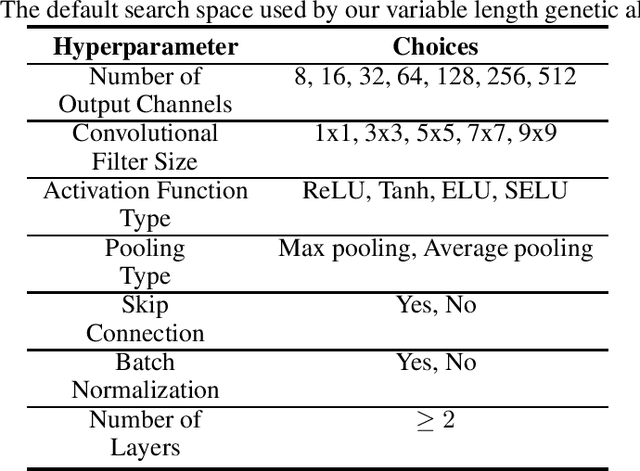

Convolutional Neural Networks (CNN) have gained great success in many artificial intelligence tasks. However, finding a good set of hyperparameters for a CNN remains a challenging task. It usually takes an expert with deep knowledge, and trials and errors. Genetic algorithms have been used in hyperparameter optimizations. However, traditional genetic algorithms with fixed-length chromosomes may not be a good fit for optimizing deep learning hyperparameters, because deep learning models have variable number of hyperparameters depending on the model depth. As the depth increases, the number of hyperparameters grows exponentially, and searching becomes exponentially harder. It is important to have an efficient algorithm that can find a good model in reasonable time. In this article, we propose to use a variable length genetic algorithm (GA) to systematically and automatically tune the hyperparameters of a CNN to improve its performance. Experimental results show that our algorithm can find good CNN hyperparameters efficiently. It is clear from our experiments that if more time is spent on optimizing the hyperparameters, better results could be achieved. Theoretically, if we had unlimited time and CPU power, we could find the optimized hyperparameters and achieve the best results in the future.
Gradient Amplification: An efficient way to train deep neural networks
Jun 16, 2020
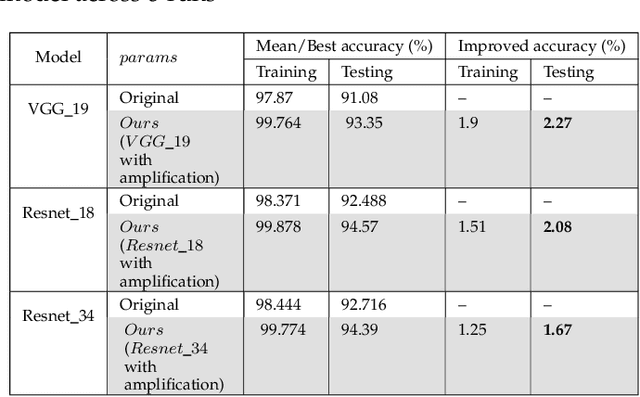

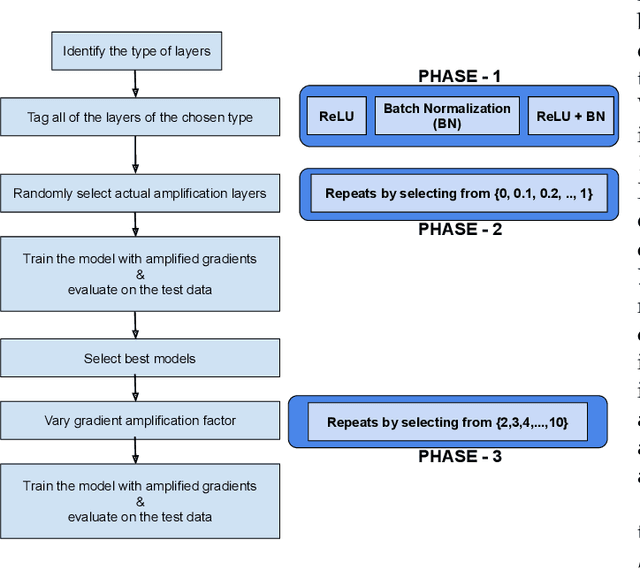
Improving performance of deep learning models and reducing their training times are ongoing challenges in deep neural networks. There are several approaches proposed to address these challenges one of which is to increase the depth of the neural networks. Such deeper networks not only increase training times, but also suffer from vanishing gradients problem while training. In this work, we propose gradient amplification approach for training deep learning models to prevent vanishing gradients and also develop a training strategy to enable or disable gradient amplification method across several epochs with different learning rates. We perform experiments on VGG-19 and resnet (Resnet-18 and Resnet-34) models, and study the impact of amplification parameters on these models in detail. Our proposed approach improves performance of these deep learning models even at higher learning rates, thereby allowing these models to achieve higher performance with reduced training time.
* 9 page document with 7 figures and one results table