 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
GIFT: Unlocking Global Optimality in Post-Training via Finite-Temperature Gibbs Initialization
Jan 14, 2026The prevailing post-training paradigm for Large Reasoning Models (LRMs)--Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL)--suffers from an intrinsic optimization mismatch: the rigid supervision inherent in SFT induces distributional collapse, thereby exhausting the exploration space necessary for subsequent RL. In this paper, we reformulate SFT within a unified post-training framework and propose Gibbs Initialization with Finite Temperature (GIFT). We characterize standard SFT as a degenerate zero-temperature limit that suppresses base priors. Conversely, GIFT incorporates supervision as a finite-temperature energy potential, establishing a distributional bridge that ensures objective consistency throughout the post-training pipeline. Our experiments demonstrate that GIFT significantly outperforms standard SFT and other competitive baselines when utilized for RL initialization, providing a mathematically principled pathway toward achieving global optimality in post-training. Our code is available at https://github.com/zzy1127/GIFT.
Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Model
Dec 25, 2025



Existing approaches typically rely on fixed length penalties, but such penalties are hard to tune and fail to adapt to the evolving reasoning abilities of LLMs, leading to suboptimal trade-offs between accuracy and conciseness. To address this challenge, we propose Leash (adaptive LEngth penAlty and reward SHaping), a reinforcement learning framework for efficient reasoning in LLMs. We formulate length control as a constrained optimization problem and employ a Lagrangian primal-dual method to dynamically adjust the penalty coefficient. When generations exceed the target length, the penalty is intensified; when they are shorter, it is relaxed. This adaptive mechanism guides models toward producing concise reasoning without sacrificing task performance. Experiments on Deepseek-R1-Distill-Qwen-1.5B and Qwen3-4B-Thinking-2507 show that Leash reduces the average reasoning length by 60% across diverse tasks - including in-distribution mathematical reasoning and out-of-distribution domains such as coding and instruction following - while maintaining competitive performance. Our work thus presents a practical and effective paradigm for developing controllable and efficient LLMs that balance reasoning capabilities with computational budgets.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Jun 14, 2025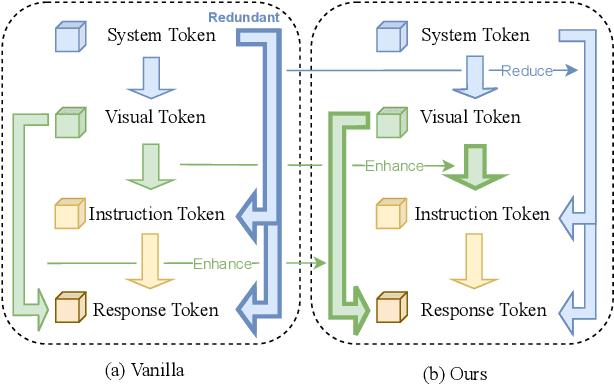
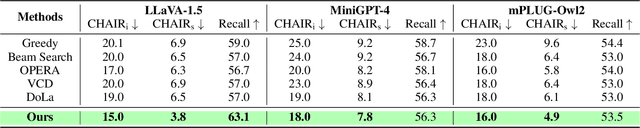
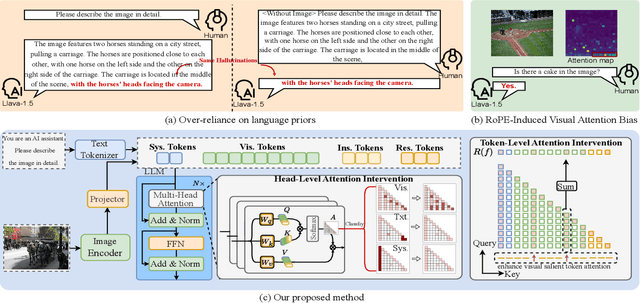

Large vision-language models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, they remain prone to visual hallucination (VH), often producing confident but incorrect descriptions of visual content. We present VisFlow, an efficient and training-free framework designed to mitigate VH by directly manipulating attention patterns during inference. Through systematic analysis, we identify three key pathological attention behaviors in LVLMs: (1) weak visual grounding, where attention to visual tokens is insufficient or misallocated, over-focusing on uninformative regions; (2) language prior dominance, where excessive attention to prior response tokens reinforces autoregressive patterns and impairs multimodal alignment; (3) prompt redundancy, where many attention heads fixate on system prompt tokens, disrupting the integration of image, instruction, and response content. To address these issues, we introduce two inference-time interventions: token-level attention intervention (TAI), which enhances focus on salient visual content, and head-level attention intervention (HAI), which suppresses over-attention to prompt and nearby text tokens. VisFlow operates without additional training or model modifications. Extensive experiments across models and benchmarks show that VisFlow effectively reduces hallucinations and improves visual factuality, with negligible computational cost.
Spectra-to-Structure and Structure-to-Spectra Inference Across the Periodic Table
Jun 13, 2025X-ray Absorption Spectroscopy (XAS) is a powerful technique for probing local atomic environments, yet its interpretation remains limited by the need for expert-driven analysis, computationally expensive simulations, and element-specific heuristics. Recent advances in machine learning have shown promise for accelerating XAS interpretation, but many existing models are narrowly focused on specific elements, edge types, or spectral regimes. In this work, we present XAStruct, a learning framework capable of both predicting XAS spectra from crystal structures and inferring local structural descriptors from XAS input. XAStruct is trained on a large-scale dataset spanning over 70 elements across the periodic table, enabling generalization to a wide variety of chemistries and bonding environments. The model includes the first machine learning approach for predicting neighbor atom types directly from XAS spectra, as well as a unified regression model for mean nearest-neighbor distance that requires no element-specific tuning. While we explored integrating the two pipelines into a single end-to-end model, empirical results showed performance degradation. As a result, the two tasks were trained independently to ensure optimal accuracy and task-specific performance. By combining deep neural networks for complex structure-property mappings with efficient baseline models for simpler tasks, XAStruct offers a scalable and extensible solution for data-driven XAS analysis and local structure inference. The source code will be released upon paper acceptance.
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions
Jun 09, 2025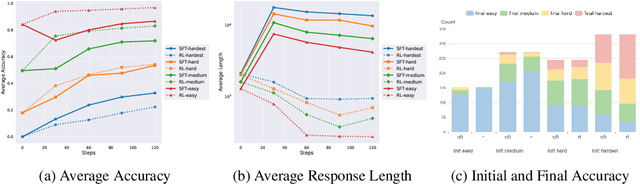
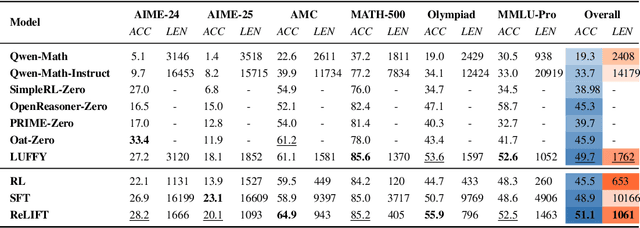
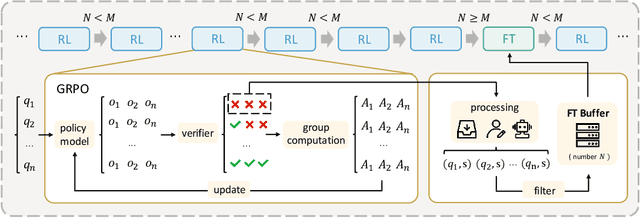
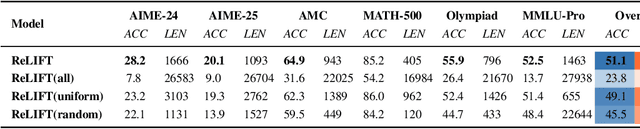
Recent advances in large language model (LLM) reasoning have shown that sophisticated behaviors such as planning and self-reflection can emerge through reinforcement learning (RL). However, despite these successes, RL in its current form remains insufficient to induce capabilities that exceed the limitations of the base model, as it is primarily optimized based on existing knowledge of the model rather than facilitating the acquisition of new information. To address this limitation, we employ supervised fine-tuning (SFT) to learn what RL cannot, which enables the incorporation of new knowledge and reasoning patterns by leveraging high-quality demonstration data. We analyze the training dynamics of RL and SFT for LLM reasoning and find that RL excels at maintaining and improving performance on questions within the model's original capabilities, while SFT is more effective at enabling progress on questions beyond the current scope of the model. Motivated by the complementary strengths of RL and SFT, we introduce a novel training approach, \textbf{ReLIFT} (\textbf{Re}inforcement \textbf{L}earning \textbf{I}nterleaved with Online \textbf{F}ine-\textbf{T}uning). In ReLIFT, the model is primarily trained using RL, but when it encounters challenging questions, high-quality solutions are collected for fine-tuning, and the training process alternates between RL and fine-tuning to enhance the model's reasoning abilities. ReLIFT achieves an average improvement of over +5.2 points across five competition-level benchmarks and one out-of-distribution benchmark compared to other zero-RL models. Furthermore, we demonstrate that ReLIFT outperforms both RL and SFT while using only 13\% of the detailed demonstration data, highlighting its scalability. These results provide compelling evidence that ReLIFT overcomes the fundamental limitations of RL and underscores the significant potential.
An adaptive filter bank based neural network approach for time delay estimation and speech enhancement
Feb 10, 2025



Time delay estimation (TDE) plays a key role in acoustic echo cancellation (AEC) using adaptive filter method. Considerable residual echo will be left if estimation error arises. Here, in this paper, we proposed an adaptive filter bank based neural network approach where the delay is estimated by a bank of adaptive filters with overlapped time scope, and all the energy of filter weights are concatenated and feed to a classification network. The index with maximal probability is chosen as the estimated delay. Based on this TDE, an AEC scheme is designed using a neural network for residual echo and noise suppression, and the optimally-modified log-spectral amplitude (OMLSA) algorithm is adopted to make it robust. Also, a robust automatic gain control (AGC) scheme with spectrum smoothing method is designed to amplify speech segments. Performance evaluations reveal that higher performance can be achieved for our scheme.
Acceleration Algorithms in GNNs: A Survey
May 07, 2024


Graph Neural Networks (GNNs) have demonstrated effectiveness in various graph-based tasks. However, their inefficiency in training and inference presents challenges for scaling up to real-world and large-scale graph applications. To address the critical challenges, a range of algorithms have been proposed to accelerate training and inference of GNNs, attracting increasing attention from the research community. In this paper, we present a systematic review of acceleration algorithms in GNNs, which can be categorized into three main topics based on their purpose: training acceleration, inference acceleration, and execution acceleration. Specifically, we summarize and categorize the existing approaches for each main topic, and provide detailed characterizations of the approaches within each category. Additionally, we review several libraries related to acceleration algorithms in GNNs and discuss our Scalable Graph Learning (SGL) library. Finally, we propose promising directions for future research. A complete summary is presented in our GitHub repository: https://github.com/PKU-DAIR/SGL/blob/main/Awsome-GNN-Acceleration.md.
Vector Approximate Message Passing based Channel Estimation for MIMO-OFDM Underwater Acoustic Communications
Nov 22, 2022



Accurate channel estimation is critical to the performance of orthogonal frequency-division multiplexing (OFDM) underwater acoustic (UWA) communications, especially under multiple-input multiple-output (MIMO) scenarios. In this paper, we explore Vector Approximate Message Passing (VAMP) coupled with Expected Maximum (EM) to obtain channel estimation (CE) for MIMO OFDM UWA communications. The EM-VAMP-CE scheme is developed by employing a Bernoulli-Gaussian (BG) prior distribution for the channel impulse response, and hyperparameters of the BG prior distribution are learned via the EM algorithm. Performance of the EM-VAMP-CE is evaluated through both synthesized data and real data collected in two at-sea UWA communication experiments. It is shown the EM-VAMP-CE achieves better performance-complexity tradeoff compared with existing channel estimation methods.