 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Temporal Convolution Network for Classroom Voice Detection
May 31, 2021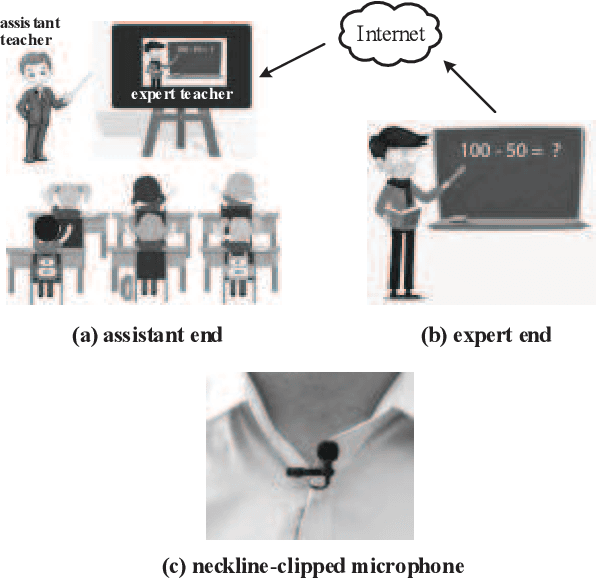
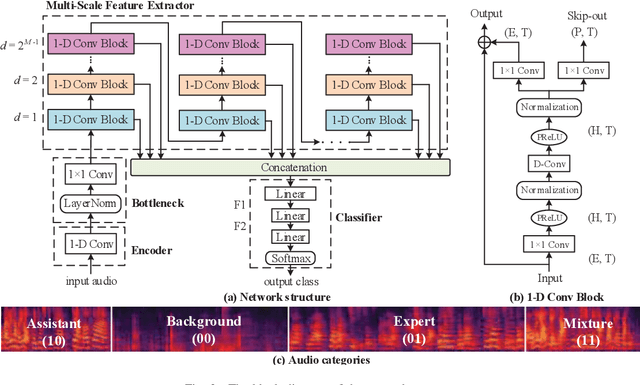
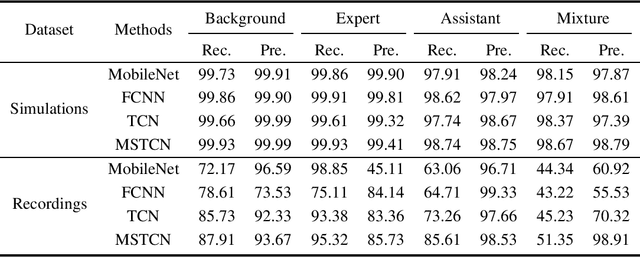
Teaching with the cooperation of expert teacher and assistant teacher, which is the so-called "double-teachers classroom", i.e., the course is giving by the expert online and presented through projection screen at the classroom, and the teacher at the classroom performs as an assistant for guiding the students in learning, is becoming more prevalent in today's teaching method for K-12 education. For monitoring the teaching quality, a microphone clipped on the assistant's neckline is always used for voice recording, then fed to the downstream tasks of automatic speech recognition (ASR) and neural language processing (NLP). However, besides its voice, there would be some other interfering voices, including the expert's one and the student's one. Here, we propose to extract the assistant' voices from the perspective of sound event detection, i.e., the voices are classified into four categories, namely the expert, the teacher, the mixture of them, and the background. To make frame-level identification, which is important for grabbing sensitive words for the downstream tasks, a multi-scale temporal convolution neural network is constructed with stacked dilated convolutions for considering both local and global properties. These features are concatenated and fed to a classification network constructed by three linear layers. The framework is evaluated on simulated data and real-world recordings, giving considerable performance in terms of precision and recall, compared with some classical classification methods.
EchoFilter: End-to-End Neural Network for Acoustic Echo Cancellation
May 31, 2021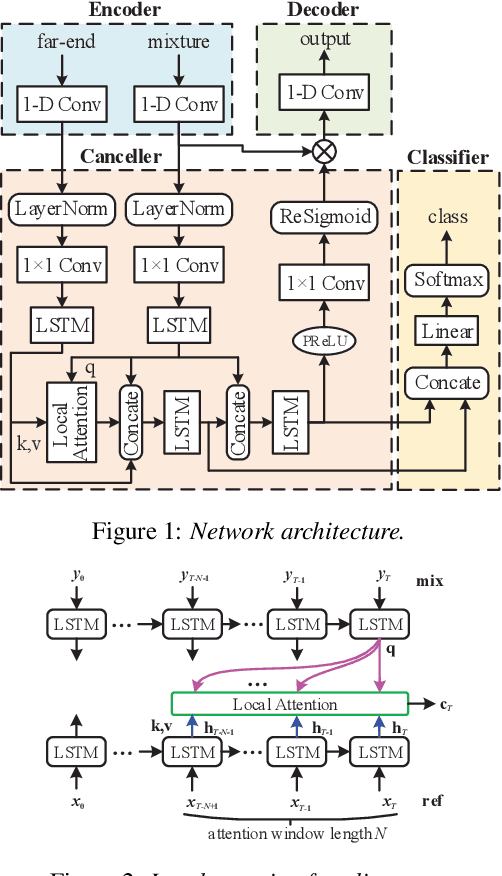

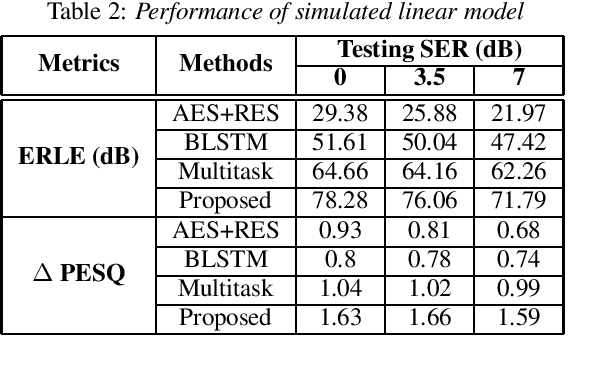
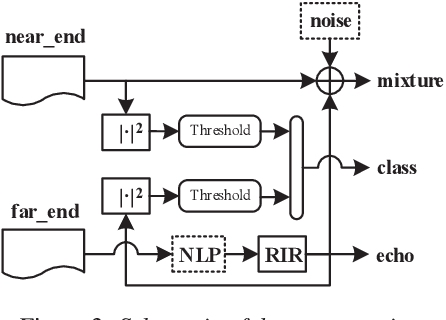
Acoustic Echo Cancellation (AEC) whose aim is to suppress the echo originated from acoustic coupling between loudspeakers and microphones, plays a key role in voice interaction. Linear adaptive filter (AF) is always used for handling this problem. However, since there would be some severe effects in real scenarios, such nonlinear distortions, background noises, and microphone clipping, it would lead to considerable residual echo, giving poor performance in practice. In this paper, we propose an end-to-end network structure for echo cancellation, which is directly done on time-domain audio waveform. It is transformed to deep representation by temporal convolution, and modelled by Long Short-Term Memory (LSTM) for considering temporal property. Since time delay and severe reverberation may exist at the near-end with respect to the far-end, a local attention is employed for alignment. The network is trained using multitask learning by employing an auxiliary classification network for double-talk detection. Experiments show the superiority of our proposed method in terms of the echo return loss enhancement (ERLE) for single-talk periods and the perceptual evaluation of speech quality (PESQ) score for double-talk periods in background noise and nonlinear distortion scenarios.