 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreat Traffic Like Trees: A Semantic-Preserving Hierarchical Graph-Based Expert Framework for Encrypted Traffic Analysis
Jun 03, 2026Graph-based deep learning methods have been widely employed in encrypted traffic analysis to exploit latent correlations across different granularities. However, while complex preprocessing pipelines and sophisticated model structures often achieve strong performance, they may obscure inherent protocol semantics during representation learning. Moreover, the hierarchical structure of protocol layers and their corresponding fields, defined by protocol specifications and routinely utilized in manual traffic analysis, remains underexplored in existing learning frameworks. In this paper, we propose Protocol Tree Graph Attention with Mixture of Experts (PTGAMoE), a semantic-preserving hierarchical graph-based expert framework for encrypted traffic analysis. The field-based graph construction and expert committee design enable PTGAMoE to quantify the model's preferences for specific fields and protocols. Extensive experimental results on representative benchmark datasets under strict no-data-leakage settings demonstrate that PTGAMoE significantly outperforms state-of-the-art (SOTA) models. Furthermore, the semantic-preserving design provides interpretable insights into protocol-level feature importance and expert-level contributions, reflecting the model's decision-making logic in encrypted traffic classification tasks.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
STEP: Scientific Time-Series Encoder Pretraining via Cross-Domain Distillation
Mar 19, 2026Scientific time series are central to scientific AI but are typically sparse, highly heterogeneous, and limited in scale, making unified representation learning particularly challenging. Meanwhile, foundation models pretrained on relevant time series domains such as audio, general time series, and brain signals contain rich knowledge, but their applicability to scientific signals remains underexplored. In this paper, we investigate the transferability and complementarity of foundation models from relevant time series domains, and study how to effectively leverage them to build a unified encoder for scientific time series. We first systematically evaluate relevant foundation models, showing the effectiveness of knowledge transfer to scientific tasks and their complementary strengths. Based on this observation, we propose STEP, a Scientific Time Series Encoder Pretraining framework via cross domain distillation. STEP introduces adaptive patching to handle extreme-length sequences and a statistics compensation scheme to accommodate diverse numerical scales. It further leverages cross-domain distillation to integrate knowledge from multiple foundation models into a unified encoder. By combining complementary representations across different domains, STEP learns general-purpose and transferable features tailored for scientific signals. Experiments on seven scientific time series tasks demonstrate that STEP provides both an effective structure and an effective pretraining paradigm, taking a STEP toward scientific time series representation learning.
Enhanced Drug-drug Interaction Prediction Using Adaptive Knowledge Integration
Mar 13, 2026Drug-drug interaction event (DDIE) prediction is crucial for preventing adverse reactions and ensuring optimal therapeutic outcomes. However, existing methods often face challenges with imbalanced datasets, complex interaction mechanisms, and poor generalization to unknown drug combinations. To address these challenges, we propose a knowledge augmentation framework that adaptively infuses prior drug knowledge into a large language model (LLM). This framework utilizes reinforcement learning techniques to facilitate adaptive knowledge extraction and synthesis, thereby efficiently optimizing the strategy space to enhance the accuracy of LLMs for DDIE predictions. As a result of few-shot learning, we achieved a notable improvement compared to the baseline. This approach establishes an effective framework for scientific knowledge learning for DDIE predictions.
A Multi-task Large Reasoning Model for Molecular Science
Mar 13, 2026Advancements in artificial intelligence for molecular science are necessitating a paradigm shift from purely data-driven predictions to knowledge-guided computational reasoning. Existing molecular models are predominantly proprietary, lacking general molecular intelligence and generalizability. This underscores the necessity for computational methods that can effectively integrate scientific logic with deep learning architectures. Here we introduce a multi-task large reasoning model designed to emulate the cognitive processes of molecular scientists through structured reasoning and reflection. Our approach incorporates multi-specialist modules to provide versatile molecular expertise and a chain-of-thought (CoT) framework enhanced by reinforcement learning infused with molecular knowledge, enabling structured and reflective reasoning. Systematic evaluations across 10 molecular tasks and 47 metrics demonstrate that our model achieves an average 50.3% improvement over the base architecture, outperforming over 20 state-of-the-art baselines, including ultra-large-parameter foundation models, despite using significantly fewer training data and computational resources. This validates that embedding explicit reasoning mechanisms enables high-efficiency learning, allowing smaller-scale models to surpass massive counterparts in both efficacy and interpretability. The practical utility of this computational framework was validated through a case study on the design of central nervous system (CNS) drug candidates, illustrating its capacity to bridge data-driven and knowledge-integrated approaches for intelligent molecular design.
GenMRP: A Generative Multi-Route Planning Framework for Efficient and Personalized Real-Time Industrial Navigation
Feb 04, 2026Existing industrial-scale navigation applications contend with massive road networks, typically employing two main categories of approaches for route planning. The first relies on precomputed road costs for optimal routing and heuristic algorithms for generating alternatives, while the second, generative methods, has recently gained significant attention. However, the former struggles with personalization and route diversity, while the latter fails to meet the efficiency requirements of large-scale real-time scenarios. To address these limitations, we propose GenMRP, a generative framework for multi-route planning. To ensure generation efficiency, GenMRP first introduces a skeleton-to-capillary approach that dynamically constructs a relevant sub-network significantly smaller than the full road network. Within this sub-network, routes are generated iteratively. The first iteration identifies the optimal route, while the subsequent ones generate alternatives that balance quality and diversity using the newly proposed correctional boosting approach. Each iteration incorporates road features, user historical sequences, and previously generated routes into a Link Cost Model to update road costs, followed by route generation using the Dijkstra algorithm. Extensive experiments show that GenMRP achieves state-of-the-art performance with high efficiency in both offline and online environments. To facilitate further research, we have publicly released the training and evaluation dataset. GenMRP has been fully deployed in a real-world navigation app, demonstrating its effectiveness and benefits.
Versatile Ordering Network: An Attention-based Neural Network for Ordering Across Scales and Quality Metrics
Dec 18, 2024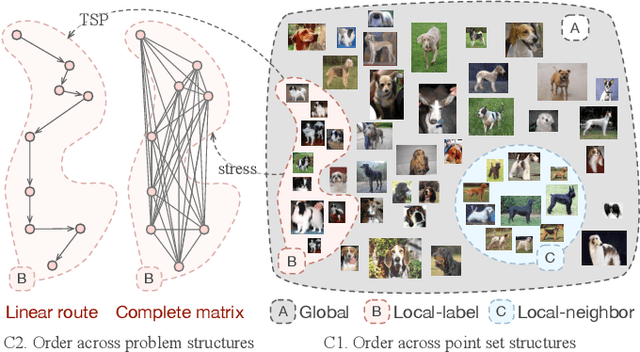

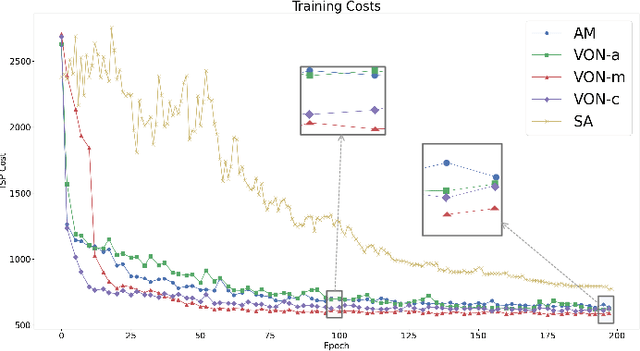

Ordering has been extensively studied in many visualization applications, such as axis and matrix reordering, for the simple reason that the order will greatly impact the perceived pattern of data. Many quality metrics concerning data pattern, perception, and aesthetics are proposed, and respective optimization algorithms are developed. However, the optimization problems related to ordering are often difficult to solve (e.g., TSP is NP-complete), and developing specialized optimization algorithms is costly. In this paper, we propose Versatile Ordering Network (VON), which automatically learns the strategy to order given a quality metric. VON uses the quality metric to evaluate its solutions, and leverages reinforcement learning with a greedy rollout baseline to improve itself. This keeps the metric transparent and allows VON to optimize over different metrics. Additionally, VON uses the attention mechanism to collect information across scales and reposition the data points with respect to the current context. This allows VONs to deal with data points following different distributions. We examine the effectiveness of VON under different usage scenarios and metrics. The results demonstrate that VON can produce comparable results to specialized solvers. The code is available at https://github.com/sysuvis/VON.
A Self-feedback Knowledge Elicitation Approach for Chemical Reaction Predictions
Apr 15, 2024The task of chemical reaction predictions (CRPs) plays a pivotal role in advancing drug discovery and material science. However, its effectiveness is constrained by the vast and uncertain chemical reaction space and challenges in capturing reaction selectivity, particularly due to existing methods' limitations in exploiting the data's inherent knowledge. To address these challenges, we introduce a data-curated self-feedback knowledge elicitation approach. This method starts from iterative optimization of molecular representations and facilitates the extraction of knowledge on chemical reaction types (RTs). Then, we employ adaptive prompt learning to infuse the prior knowledge into the large language model (LLM). As a result, we achieve significant enhancements: a 14.2% increase in retrosynthesis prediction accuracy, a 74.2% rise in reagent prediction accuracy, and an expansion in the model's capability for handling multi-task chemical reactions. This research offers a novel paradigm for knowledge elicitation in scientific research and showcases the untapped potential of LLMs in CRPs.
Scientific Language Modeling: A Quantitative Review of Large Language Models in Molecular Science
Feb 06, 2024Efficient molecular modeling and design are crucial for the discovery and exploration of novel molecules, and the incorporation of deep learning methods has revolutionized this field. In particular, large language models (LLMs) offer a fresh approach to tackle scientific problems from a natural language processing (NLP) perspective, introducing a research paradigm called scientific language modeling (SLM). However, two key issues remain: how to quantify the match between model and data modalities and how to identify the knowledge-learning preferences of models. To address these challenges, we propose a multi-modal benchmark, named ChEBI-20-MM, and perform 1263 experiments to assess the model's compatibility with data modalities and knowledge acquisition. Through the modal transition probability matrix, we provide insights into the most suitable modalities for tasks. Furthermore, we introduce a statistically interpretable approach to discover context-specific knowledge mapping by localized feature filtering. Our pioneering analysis offers an exploration of the learning mechanism and paves the way for advancing SLM in molecular science.
FlowHON: Representing Flow Fields Using Higher-Order Networks
Dec 04, 2023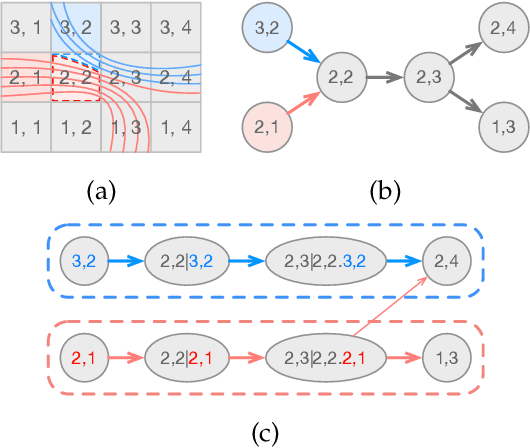
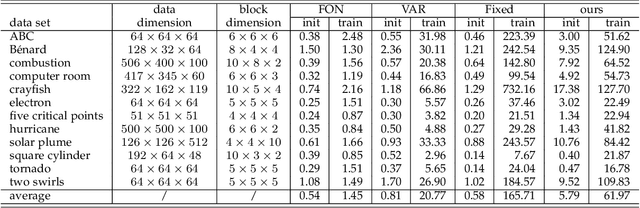
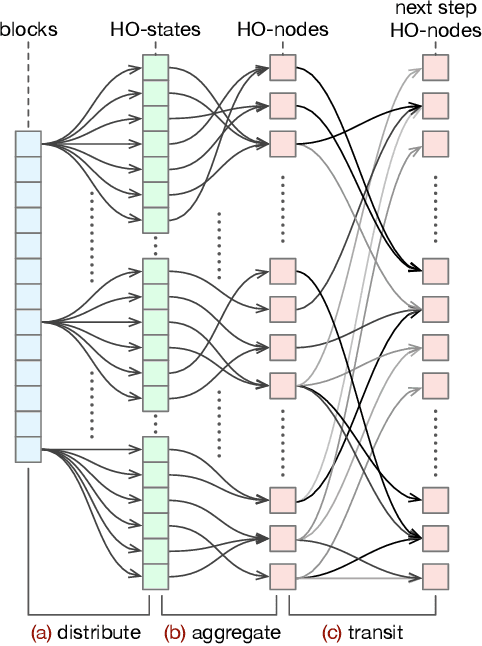
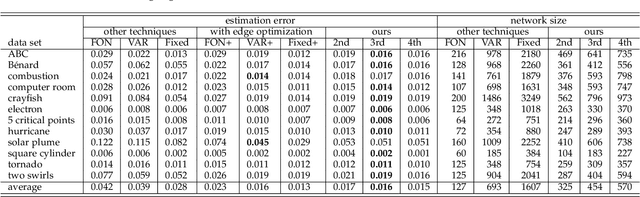
Flow fields are often partitioned into data blocks for massively parallel computation and analysis based on blockwise relationships. However, most of the previous techniques only consider the first-order dependencies among blocks, which is insufficient in describing complex flow patterns. In this work, we present FlowHON, an approach to construct higher-order networks (HONs) from flow fields. FlowHON captures the inherent higher-order dependencies in flow fields as nodes and estimates the transitions among them as edges. We formulate the HON construction as an optimization problem with three linear transformations. The first two layers correspond to the node generation and the third one corresponds to edge estimation. Our formulation allows the node generation and edge estimation to be solved in a unified framework. With FlowHON, the rich set of traditional graph algorithms can be applied without any modification to analyze flow fields, while leveraging the higher-order information to understand the inherent structure and manage flow data for efficiency. We demonstrate the effectiveness of FlowHON using a series of downstream tasks, including estimating the density of particles during tracing, partitioning flow fields for data management, and understanding flow fields using the node-link diagram representation of networks.