 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowHON: Representing Flow Fields Using Higher-Order Networks
Dec 04, 2023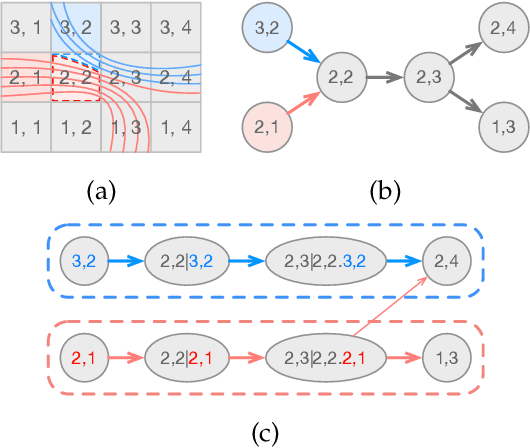
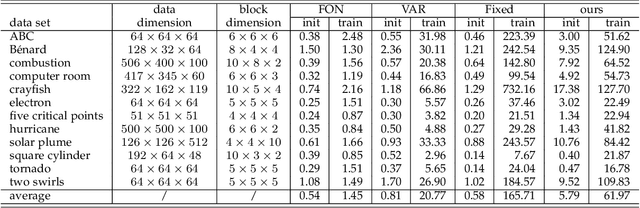
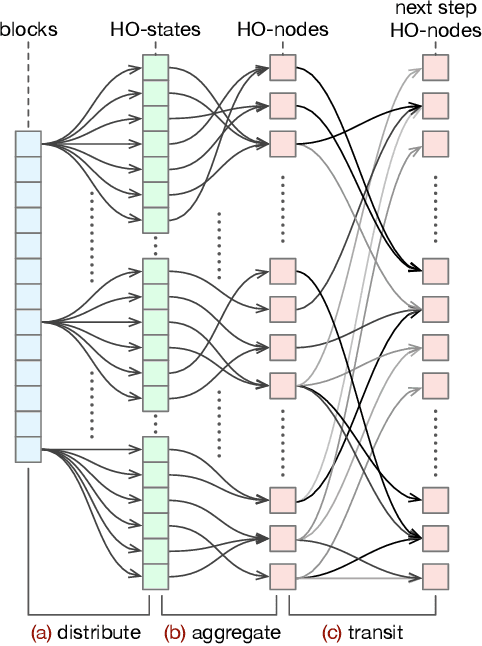
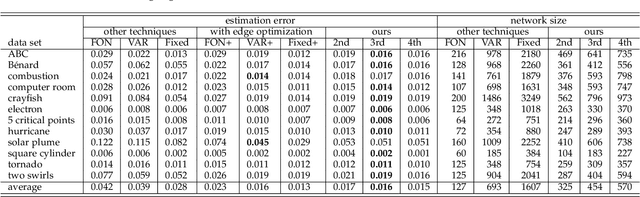
Flow fields are often partitioned into data blocks for massively parallel computation and analysis based on blockwise relationships. However, most of the previous techniques only consider the first-order dependencies among blocks, which is insufficient in describing complex flow patterns. In this work, we present FlowHON, an approach to construct higher-order networks (HONs) from flow fields. FlowHON captures the inherent higher-order dependencies in flow fields as nodes and estimates the transitions among them as edges. We formulate the HON construction as an optimization problem with three linear transformations. The first two layers correspond to the node generation and the third one corresponds to edge estimation. Our formulation allows the node generation and edge estimation to be solved in a unified framework. With FlowHON, the rich set of traditional graph algorithms can be applied without any modification to analyze flow fields, while leveraging the higher-order information to understand the inherent structure and manage flow data for efficiency. We demonstrate the effectiveness of FlowHON using a series of downstream tasks, including estimating the density of particles during tracing, partitioning flow fields for data management, and understanding flow fields using the node-link diagram representation of networks.
MSTGD:A Memory Stochastic sTratified Gradient Descent Method with an Exponential Convergence Rate
Feb 21, 2022
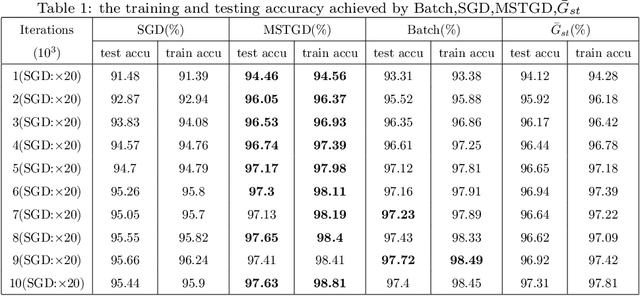
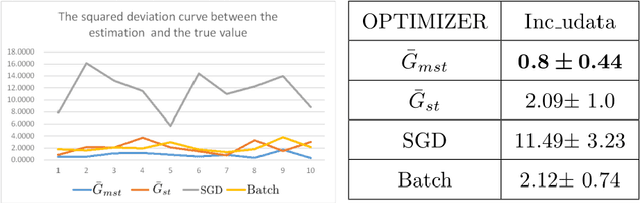

The fluctuation effect of gradient expectation and variance caused by parameter update between consecutive iterations is neglected or confusing by current mainstream gradient optimization algorithms.Using this fluctuation effect, combined with the stratified sampling strategy, this paper designs a novel \underline{M}emory \underline{S}tochastic s\underline{T}ratified Gradient Descend(\underline{MST}GD) algorithm with an exponential convergence rate. Specifically, MSTGD uses two strategies for variance reduction: the first strategy is to perform variance reduction according to the proportion p of used historical gradient, which is estimated from the mean and variance of sample gradients before and after iteration, and the other strategy is stratified sampling by category. The statistic \ $\bar{G}_{mst}$\ designed under these two strategies can be adaptively unbiased, and its variance decays at a geometric rate. This enables MSTGD based on $\bar{G}_{mst}$ to obtain an exponential convergence rate of the form $\lambda^{2(k-k_0)}$($\lambda\in (0,1)$,k is the number of iteration steps,$\lambda$ is a variable related to proportion p).Unlike most other algorithms that claim to achieve an exponential convergence rate, the convergence rate is independent of parameters such as dataset size N, batch size n, etc., and can be achieved at a constant step size.Theoretical and experimental results show the effectiveness of MSTGD