 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSTGD:A Memory Stochastic sTratified Gradient Descent Method with an Exponential Convergence Rate
Paper and Code
Feb 21, 2022
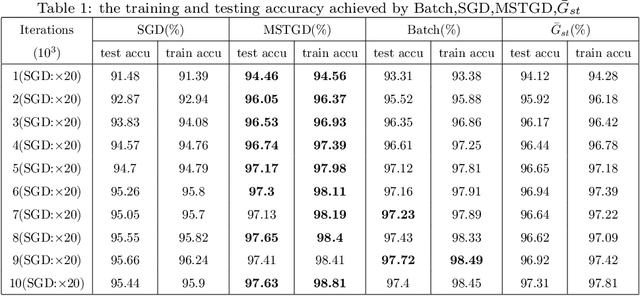
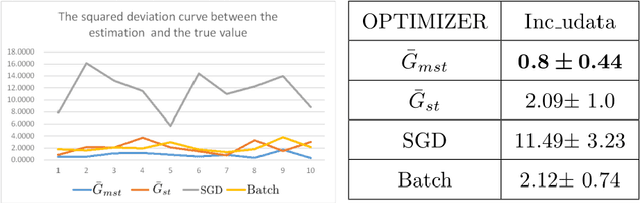

The fluctuation effect of gradient expectation and variance caused by parameter update between consecutive iterations is neglected or confusing by current mainstream gradient optimization algorithms.Using this fluctuation effect, combined with the stratified sampling strategy, this paper designs a novel \underline{M}emory \underline{S}tochastic s\underline{T}ratified Gradient Descend(\underline{MST}GD) algorithm with an exponential convergence rate. Specifically, MSTGD uses two strategies for variance reduction: the first strategy is to perform variance reduction according to the proportion p of used historical gradient, which is estimated from the mean and variance of sample gradients before and after iteration, and the other strategy is stratified sampling by category. The statistic \ $\bar{G}_{mst}$\ designed under these two strategies can be adaptively unbiased, and its variance decays at a geometric rate. This enables MSTGD based on $\bar{G}_{mst}$ to obtain an exponential convergence rate of the form $\lambda^{2(k-k_0)}$($\lambda\in (0,1)$,k is the number of iteration steps,$\lambda$ is a variable related to proportion p).Unlike most other algorithms that claim to achieve an exponential convergence rate, the convergence rate is independent of parameters such as dataset size N, batch size n, etc., and can be achieved at a constant step size.Theoretical and experimental results show the effectiveness of MSTGD