 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Vision and Language: Codebook Anchored Visual Adaptation
Feb 23, 2026Large Vision-Language Models (LVLMs) use their vision encoders to translate images into representations for downstream reasoning, but the encoders often underperform in domain-specific visual tasks such as medical image diagnosis or fine-grained classification, where representation errors can cascade through the language model, leading to incorrect responses. Existing adaptation methods modify the continuous feature interface between encoder and language model through projector tuning or other parameter-efficient updates, which still couples the two components and requires re-alignment whenever the encoder changes. We introduce CRAFT (Codebook RegulAted Fine-Tuning), a lightweight method that fine-tunes the encoder using a discrete codebook that anchors visual representations to a stable token space, achieving domain adaptation without modifying other parts of the model. This decoupled design allows the adapted encoder to seamlessly boost the performance of LVLMs with different language architectures, as long as they share the same codebook. Empirically, CRAFT achieves an average gain of 13.51% across 10 domain-specific benchmarks such as VQARAD and PlantVillage, while preserving the LLM's linguistic capabilities and outperforming peer methods that operate on continuous tokens.
Nemotron ColEmbed V2: Top-Performing Late Interaction embedding models for Visual Document Retrieval
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems have been popular for generative applications, powering language models by injecting external knowledge. Companies have been trying to leverage their large catalog of documents (e.g. PDFs, presentation slides) in such RAG pipelines, whose first step is the retrieval component. Dense retrieval has been a popular approach, where embedding models are used to generate a dense representation of the user query that is closer to relevant content embeddings. More recently, VLM-based embedding models have become popular for visual document retrieval, as they preserve visual information and simplify the indexing pipeline compared to OCR text extraction. Motivated by the growing demand for visual document retrieval, we introduce Nemotron ColEmbed V2, a family of models that achieve state-of-the-art performance on the ViDoRe benchmarks. We release three variants - with 3B, 4B, and 8B parameters - based on pre-trained VLMs: NVIDIA Eagle 2 with Llama 3.2 3B backbone, Qwen3-VL-4B-Instruct and Qwen3-VL-8B-Instruct, respectively. The 8B model ranks first on the ViDoRe V3 leaderboard as of February 03, 2026, achieving an average NDCG@10 of 63.42. We describe the main techniques used across data processing, training, and post-training - such as cluster-based sampling, hard-negative mining, bidirectional attention, late interaction, and model merging - that helped us build our top-performing models. We also discuss compute and storage engineering challenges posed by the late interaction mechanism and present experiments on how to balance accuracy and storage with lower dimension embeddings.
Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
Jan 08, 2026We introduce Talk2Move, a reinforcement learning (RL) based diffusion framework for text-instructed spatial transformation of objects within scenes. Spatially manipulating objects in a scene through natural language poses a challenge for multimodal generation systems. While existing text-based manipulation methods can adjust appearance or style, they struggle to perform object-level geometric transformations-such as translating, rotating, or resizing objects-due to scarce paired supervision and pixel-level optimization limits. Talk2Move employs Group Relative Policy Optimization (GRPO) to explore geometric actions through diverse rollouts generated from input images and lightweight textual variations, removing the need for costly paired data. A spatial reward guided model aligns geometric transformations with linguistic description, while off-policy step evaluation and active step sampling improve learning efficiency by focusing on informative transformation stages. Furthermore, we design object-centric spatial rewards that evaluate displacement, rotation, and scaling behaviors directly, enabling interpretable and coherent transformations. Experiments on curated benchmarks demonstrate that Talk2Move achieves precise, consistent, and semantically faithful object transformations, outperforming existing text-guided editing approaches in both spatial accuracy and scene coherence.
InsQABench: Benchmarking Chinese Insurance Domain Question Answering with Large Language Models
Jan 19, 2025The application of large language models (LLMs) has achieved remarkable success in various fields, but their effectiveness in specialized domains like the Chinese insurance industry remains underexplored. The complexity of insurance knowledge, encompassing specialized terminology and diverse data types, poses significant challenges for both models and users. To address this, we introduce InsQABench, a benchmark dataset for the Chinese insurance sector, structured into three categories: Insurance Commonsense Knowledge, Insurance Structured Database, and Insurance Unstructured Documents, reflecting real-world insurance question-answering tasks.We also propose two methods, SQL-ReAct and RAG-ReAct, to tackle challenges in structured and unstructured data tasks. Evaluations show that while LLMs struggle with domain-specific terminology and nuanced clause texts, fine-tuning on InsQABench significantly improves performance. Our benchmark establishes a solid foundation for advancing LLM applications in the insurance domain, with data and code available at https://github.com/HaileyFamo/InsQABench.git.
Hyperbolic Learning with Synthetic Captions for Open-World Detection
Apr 07, 2024



Open-world detection poses significant challenges, as it requires the detection of any object using either object class labels or free-form texts. Existing related works often use large-scale manual annotated caption datasets for training, which are extremely expensive to collect. Instead, we propose to transfer knowledge from vision-language models (VLMs) to enrich the open-vocabulary descriptions automatically. Specifically, we bootstrap dense synthetic captions using pre-trained VLMs to provide rich descriptions on different regions in images, and incorporate these captions to train a novel detector that generalizes to novel concepts. To mitigate the noise caused by hallucination in synthetic captions, we also propose a novel hyperbolic vision-language learning approach to impose a hierarchy between visual and caption embeddings. We call our detector ``HyperLearner''. We conduct extensive experiments on a wide variety of open-world detection benchmarks (COCO, LVIS, Object Detection in the Wild, RefCOCO) and our results show that our model consistently outperforms existing state-of-the-art methods, such as GLIP, GLIPv2 and Grounding DINO, when using the same backbone.
MeMOT: Multi-Object Tracking with Memory
Mar 31, 2022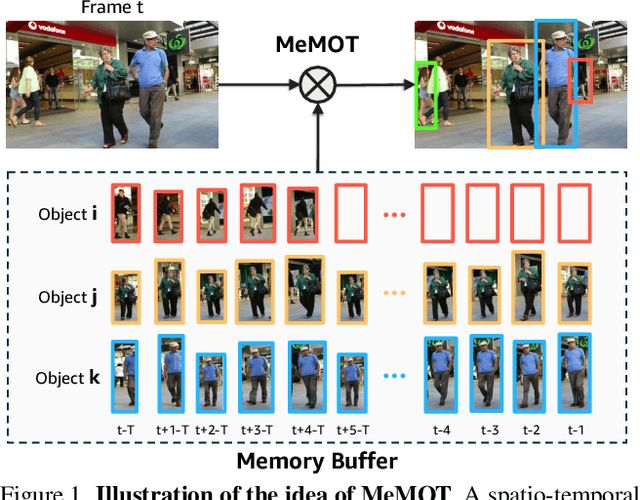
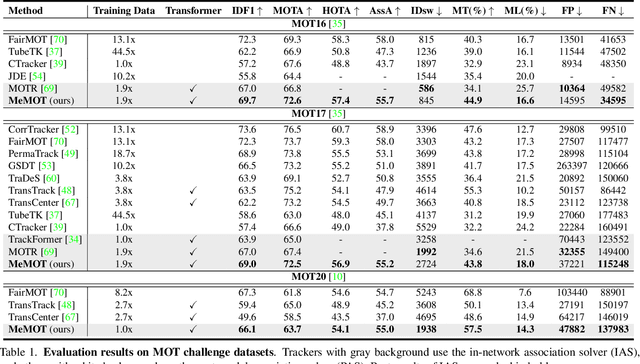
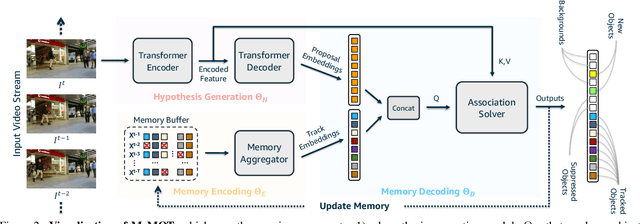
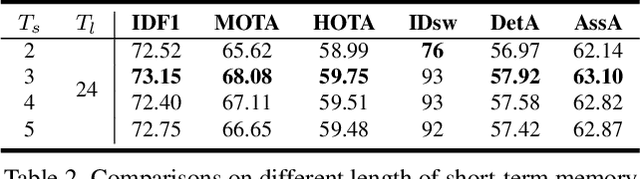
We propose an online tracking algorithm that performs the object detection and data association under a common framework, capable of linking objects after a long time span. This is realized by preserving a large spatio-temporal memory to store the identity embeddings of the tracked objects, and by adaptively referencing and aggregating useful information from the memory as needed. Our model, called MeMOT, consists of three main modules that are all Transformer-based: 1) Hypothesis Generation that produce object proposals in the current video frame; 2) Memory Encoding that extracts the core information from the memory for each tracked object; and 3) Memory Decoding that solves the object detection and data association tasks simultaneously for multi-object tracking. When evaluated on widely adopted MOT benchmark datasets, MeMOT observes very competitive performance.
ACE: Ally Complementary Experts for Solving Long-Tailed Recognition in One-Shot
Aug 05, 2021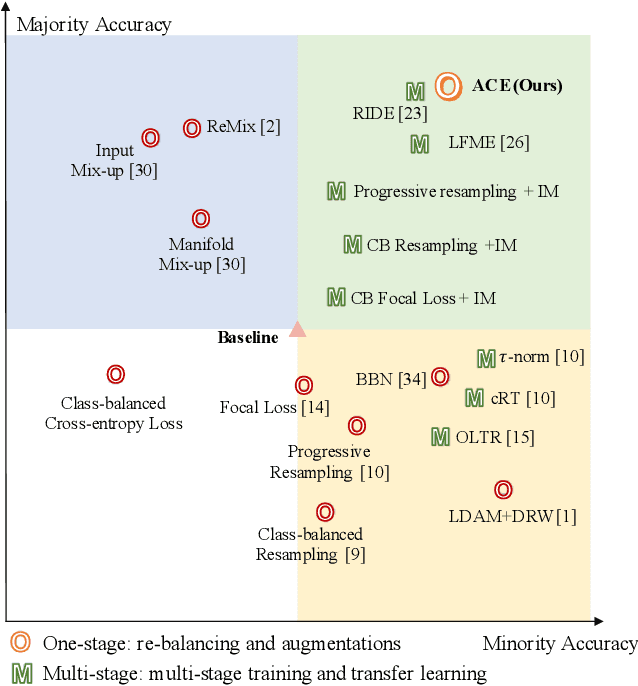

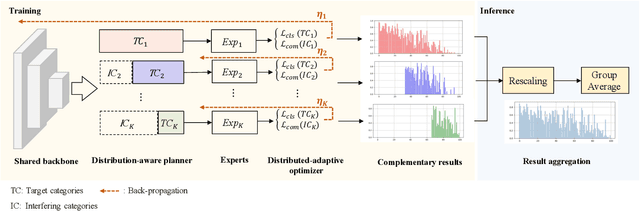
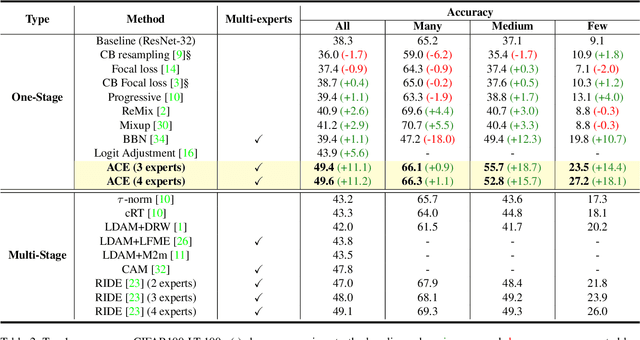
One-stage long-tailed recognition methods improve the overall performance in a "seesaw" manner, i.e., either sacrifice the head's accuracy for better tail classification or elevate the head's accuracy even higher but ignore the tail. Existing algorithms bypass such trade-off by a multi-stage training process: pre-training on imbalanced set and fine-tuning on balanced set. Though achieving promising performance, not only are they sensitive to the generalizability of the pre-trained model, but also not easily integrated into other computer vision tasks like detection and segmentation, where pre-training of classifiers solely is not applicable. In this paper, we propose a one-stage long-tailed recognition scheme, ally complementary experts (ACE), where the expert is the most knowledgeable specialist in a sub-set that dominates its training, and is complementary to other experts in the less-seen categories without being disturbed by what it has never seen. We design a distribution-adaptive optimizer to adjust the learning pace of each expert to avoid over-fitting. Without special bells and whistles, the vanilla ACE outperforms the current one-stage SOTA method by 3-10% on CIFAR10-LT, CIFAR100-LT, ImageNet-LT and iNaturalist datasets. It is also shown to be the first one to break the "seesaw" trade-off by improving the accuracy of the majority and minority categories simultaneously in only one stage. Code and trained models are at https://github.com/jrcai/ACE.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
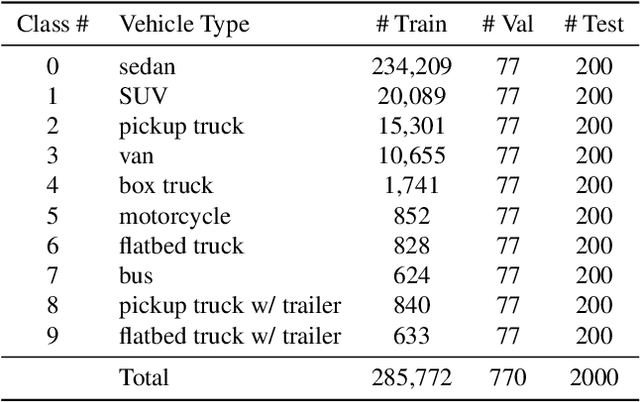
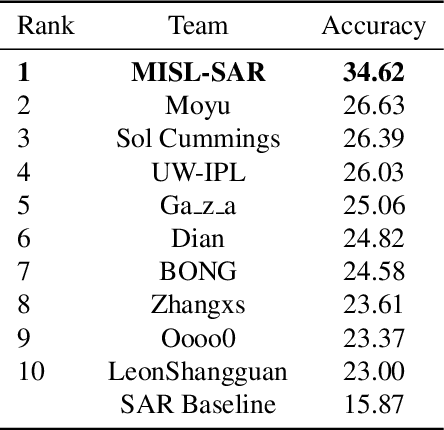
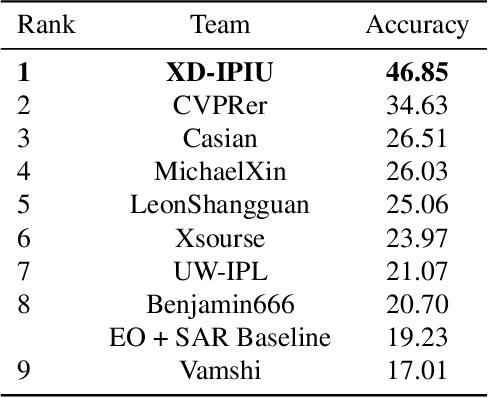
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
Multi-Target Multi-Camera Tracking of Vehicles using Metadata-Aided Re-ID and Trajectory-Based Camera Link Model
May 03, 2021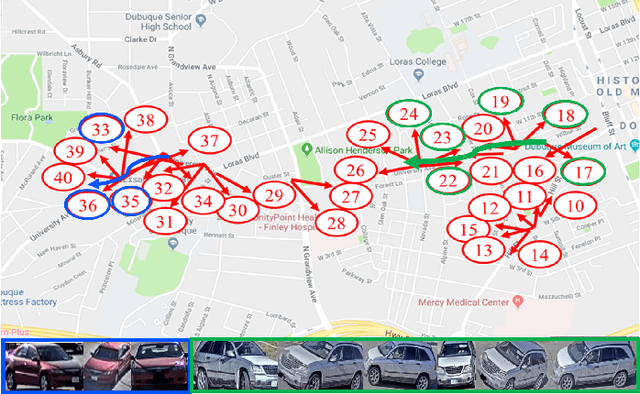

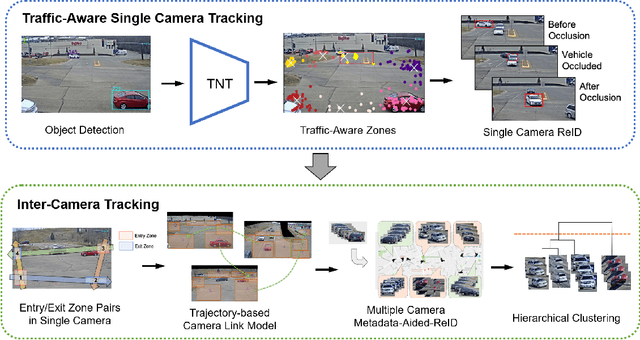
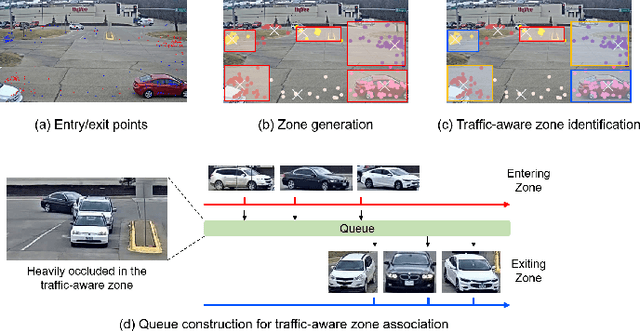
In this paper, we propose a novel framework for multi-target multi-camera tracking (MTMCT) of vehicles based on metadata-aided re-identification (MA-ReID) and the trajectory-based camera link model (TCLM). Given a video sequence and the corresponding frame-by-frame vehicle detections, we first address the isolated tracklets issue from single camera tracking (SCT) by the proposed traffic-aware single-camera tracking (TSCT). Then, after automatically constructing the TCLM, we solve MTMCT by the MA-ReID. The TCLM is generated from camera topological configuration to obtain the spatial and temporal information to improve the performance of MTMCT by reducing the candidate search of ReID. We also use the temporal attention model to create more discriminative embeddings of trajectories from each camera to achieve robust distance measures for vehicle ReID. Moreover, we train a metadata classifier for MTMCT to obtain the metadata feature, which is concatenated with the temporal attention based embeddings. Finally, the TCLM and hierarchical clustering are jointly applied for global ID assignment. The proposed method is evaluated on the CityFlow dataset, achieving IDF1 76.77%, which outperforms the state-of-the-art MTMCT methods.
IA-MOT: Instance-Aware Multi-Object Tracking with Motion Consistency
Jun 24, 2020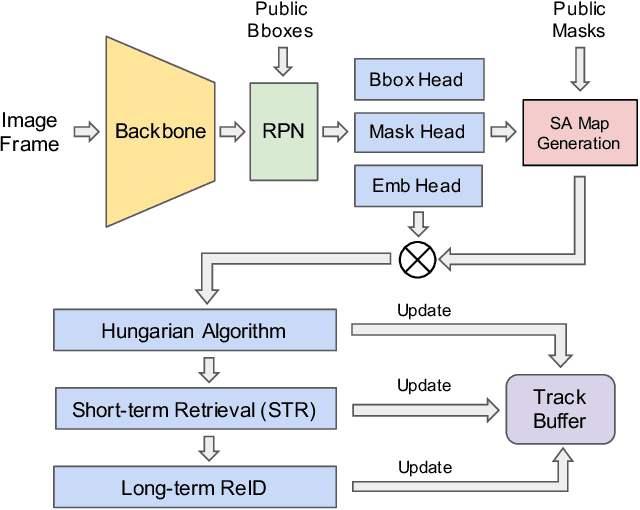
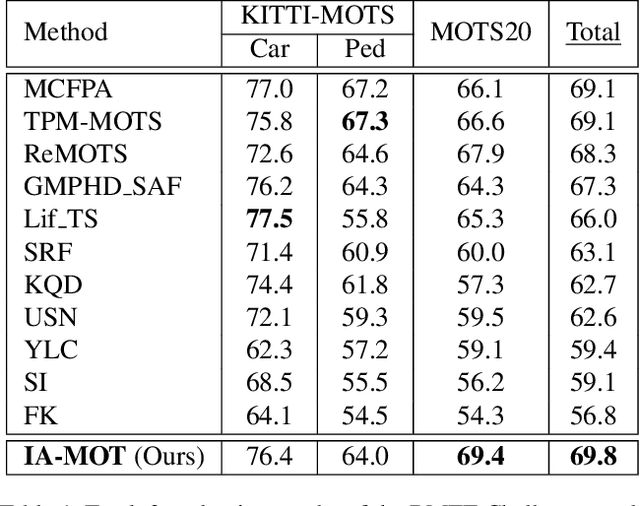

Multiple object tracking (MOT) is a crucial task in computer vision society. However, most tracking-by-detection MOT methods, with available detected bounding boxes, cannot effectively handle static, slow-moving and fast-moving camera scenarios simultaneously due to ego-motion and frequent occlusion. In this work, we propose a novel tracking framework, called "instance-aware MOT" (IA-MOT), that can track multiple objects in either static or moving cameras by jointly considering the instance-level features and object motions. First, robust appearance features are extracted from a variant of Mask R-CNN detector with an additional embedding head, by sending the given detections as the region proposals. Meanwhile, the spatial attention, which focuses on the foreground within the bounding boxes, is generated from the given instance masks and applied to the extracted embedding features. In the tracking stage, object instance masks are aligned by feature similarity and motion consistency using the Hungarian association algorithm. Moreover, object re-identification (ReID) is incorporated to recover ID switches caused by long-term occlusion or missing detection. Overall, when evaluated on the MOTS20 and KITTI-MOTS dataset, our proposed method won the first place in Track 3 of the BMTT Challenge in CVPR2020 workshops.