 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE: Ally Complementary Experts for Solving Long-Tailed Recognition in One-Shot
Paper and Code
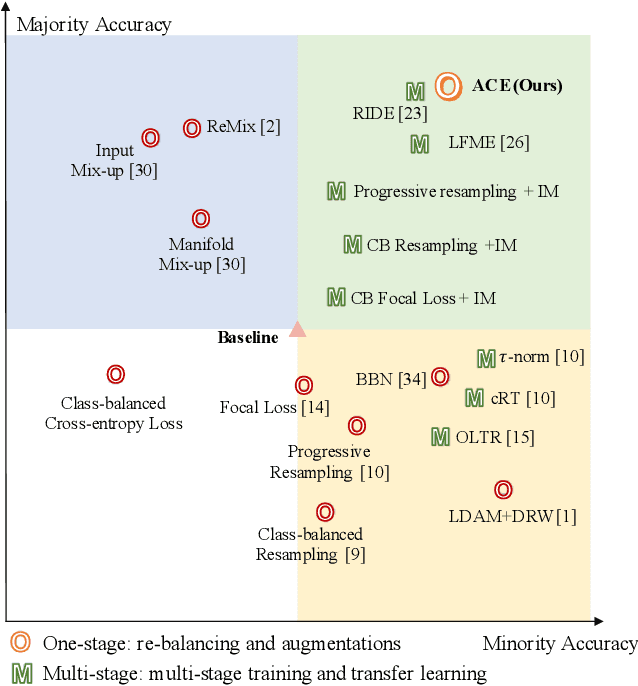

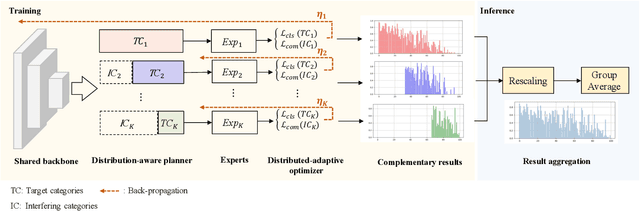
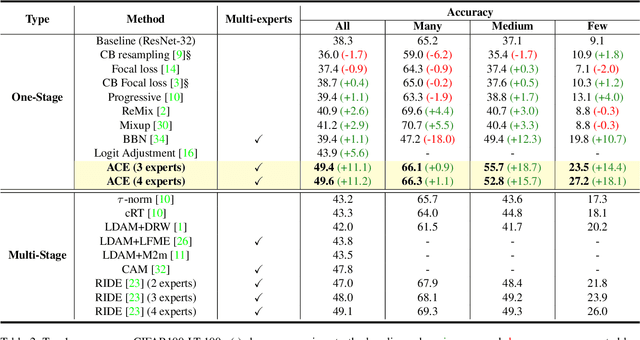
One-stage long-tailed recognition methods improve the overall performance in a "seesaw" manner, i.e., either sacrifice the head's accuracy for better tail classification or elevate the head's accuracy even higher but ignore the tail. Existing algorithms bypass such trade-off by a multi-stage training process: pre-training on imbalanced set and fine-tuning on balanced set. Though achieving promising performance, not only are they sensitive to the generalizability of the pre-trained model, but also not easily integrated into other computer vision tasks like detection and segmentation, where pre-training of classifiers solely is not applicable. In this paper, we propose a one-stage long-tailed recognition scheme, ally complementary experts (ACE), where the expert is the most knowledgeable specialist in a sub-set that dominates its training, and is complementary to other experts in the less-seen categories without being disturbed by what it has never seen. We design a distribution-adaptive optimizer to adjust the learning pace of each expert to avoid over-fitting. Without special bells and whistles, the vanilla ACE outperforms the current one-stage SOTA method by 3-10% on CIFAR10-LT, CIFAR100-LT, ImageNet-LT and iNaturalist datasets. It is also shown to be the first one to break the "seesaw" trade-off by improving the accuracy of the majority and minority categories simultaneously in only one stage. Code and trained models are at https://github.com/jrcai/ACE.