 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Temporal Credit Assignment for Optimal Policy Preservation in Sparse Multi-Agent Reinforcement Learning
Dec 19, 2024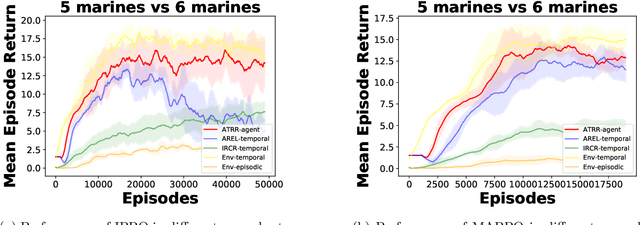
In multi-agent environments, agents often struggle to learn optimal policies due to sparse or delayed global rewards, particularly in long-horizon tasks where it is challenging to evaluate actions at intermediate time steps. We introduce Temporal-Agent Reward Redistribution (TAR$^2$), a novel approach designed to address the agent-temporal credit assignment problem by redistributing sparse rewards both temporally and across agents. TAR$^2$ decomposes sparse global rewards into time-step-specific rewards and calculates agent-specific contributions to these rewards. We theoretically prove that TAR$^2$ is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirical results demonstrate that TAR$^2$ stabilizes and accelerates the learning process. Additionally, we show that when TAR$^2$ is integrated with single-agent reinforcement learning algorithms, it performs as well as or better than traditional multi-agent reinforcement learning methods.
SocNavGym: A Reinforcement Learning Gym for Social Navigation
Apr 27, 2023



It is essential for autonomous robots to be socially compliant while navigating in human-populated environments. Machine Learning and, especially, Deep Reinforcement Learning have recently gained considerable traction in the field of Social Navigation. This can be partially attributed to the resulting policies not being bound by human limitations in terms of code complexity or the number of variables that are handled. Unfortunately, the lack of safety guarantees and the large data requirements by DRL algorithms make learning in the real world unfeasible. To bridge this gap, simulation environments are frequently used. We propose SocNavGym, an advanced simulation environment for social navigation that can generate a wide variety of social navigation scenarios and facilitates the development of intelligent social agents. SocNavGym is light-weight, fast, easy-to-use, and can be effortlessly configured to generate different types of social navigation scenarios. It can also be configured to work with different hand-crafted and data-driven social reward signals and to yield a variety of evaluation metrics to benchmark agents' performance. Further, we also provide a case study where a Dueling-DQN agent is trained to learn social-navigation policies using SocNavGym. The results provides evidence that SocNavGym can be used to train an agent from scratch to navigate in simple as well as complex social scenarios. Our experiments also show that the agents trained using the data-driven reward function displays more advanced social compliance in comparison to the heuristic-based reward function.