 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpectation Error Bounds for Transfer Learning in Linear Regression and Linear Neural Networks
Mar 30, 2026In transfer learning, the learner leverages auxiliary data to improve generalization on a main task. However, the precise theoretical understanding of when and how auxiliary data help remains incomplete. We provide new insights on this issue in two canonical linear settings: ordinary least squares regression and under-parameterized linear neural networks. For linear regression, we derive exact closed-form expressions for the expected generalization error with bias-variance decomposition, yielding necessary and sufficient conditions for auxiliary tasks to improve generalization on the main task. We also derive globally optimal task weights as outputs of solvable optimization programs, with consistency guarantees for empirical estimates. For linear neural networks with shared representations of width $q \leq K$, where $K$ is the number of auxiliary tasks, we derive a non-asymptotic expectation bound on the generalization error, yielding the first non-vacuous sufficient condition for beneficial auxiliary learning in this setting, as well as principled directions for task weight curation. We achieve this by proving a new column-wise low-rank perturbation bound for random matrices, which improves upon existing bounds by preserving fine-grained column structures. Our results are verified on synthetic data simulated with controlled parameters.
Cross-attention Secretly Performs Orthogonal Alignment in Recommendation Models
Oct 10, 2025Cross-domain sequential recommendation (CDSR) aims to align heterogeneous user behavior sequences collected from different domains. While cross-attention is widely used to enhance alignment and improve recommendation performance, its underlying mechanism is not fully understood. Most researchers interpret cross-attention as residual alignment, where the output is generated by removing redundant and preserving non-redundant information from the query input by referencing another domain data which is input key and value. Beyond the prevailing view, we introduce Orthogonal Alignment, a phenomenon in which cross-attention discovers novel information that is not present in the query input, and further argue that those two contrasting alignment mechanisms can co-exist in recommendation models We find that when the query input and output of cross-attention are orthogonal, model performance improves over 300 experiments. Notably, Orthogonal Alignment emerges naturally, without any explicit orthogonality constraints. Our key insight is that Orthogonal Alignment emerges naturally because it improves scaling law. We show that baselines additionally incorporating cross-attention module outperform parameter-matched baselines, achieving a superior accuracy-per-model parameter. We hope these findings offer new directions for parameter-efficient scaling in multi-modal research.
Orthogonal Causal Calibration
Jun 04, 2024Estimates of causal parameters such as conditional average treatment effects and conditional quantile treatment effects play an important role in real-world decision making. Given this importance, one should ensure these estimators are calibrated. While there is a rich literature on calibrating estimators of non-causal parameters, very few methods have been derived for calibrating estimators of causal parameters, or more generally estimators of quantities involving nuisance parameters. In this work, we provide a general framework for calibrating predictors involving nuisance estimation. We consider a notion of calibration defined with respect to an arbitrary, nuisance-dependent loss $\ell$, under which we say an estimator $\theta$ is calibrated if its predictions cannot be changed on any level set to decrease loss. We prove generic upper bounds on the calibration error of any causal parameter estimate $\theta$ with respect to any loss $\ell$ using a concept called Neyman Orthogonality. Our bounds involve two decoupled terms - one measuring the error in estimating the unknown nuisance parameters, and the other representing the calibration error in a hypothetical world where the learned nuisance estimates were true. We use our bound to analyze the convergence of two sample splitting algorithms for causal calibration. One algorithm, which applies to universally orthogonalizable loss functions, transforms the data into generalized pseudo-outcomes and applies an off-the-shelf calibration procedure. The other algorithm, which applies to conditionally orthogonalizable loss functions, extends the classical uniform mass binning algorithm to include nuisance estimation. Our results are exceedingly general, showing that essentially any existing calibration algorithm can be used in causal settings, with additional loss only arising from errors in nuisance estimation.
Taking a Moment for Distributional Robustness
May 08, 2024A rich line of recent work has studied distributionally robust learning approaches that seek to learn a hypothesis that performs well, in the worst-case, on many different distributions over a population. We argue that although the most common approaches seek to minimize the worst-case loss over distributions, a more reasonable goal is to minimize the worst-case distance to the true conditional expectation of labels given each covariate. Focusing on the minmax loss objective can dramatically fail to output a solution minimizing the distance to the true conditional expectation when certain distributions contain high levels of label noise. We introduce a new min-max objective based on what is known as the adversarial moment violation and show that minimizing this objective is equivalent to minimizing the worst-case $\ell_2$-distance to the true conditional expectation if we take the adversary's strategy space to be sufficiently rich. Previous work has suggested minimizing the maximum regret over the worst-case distribution as a way to circumvent issues arising from differential noise levels. We show that in the case of square loss, minimizing the worst-case regret is also equivalent to minimizing the worst-case $\ell_2$-distance to the true conditional expectation. Although their objective and our objective both minimize the worst-case distance to the true conditional expectation, we show that our approach provides large empirical savings in computational cost in terms of the number of groups, while providing the same noise-oblivious worst-distribution guarantee as the minimax regret approach, thus making positive progress on an open question posed by Agarwal and Zhang (2022).
Oracle Efficient Online Multicalibration and Omniprediction
Jul 18, 2023A recent line of work has shown a surprising connection between multicalibration, a multi-group fairness notion, and omniprediction, a learning paradigm that provides simultaneous loss minimization guarantees for a large family of loss functions. Prior work studies omniprediction in the batch setting. We initiate the study of omniprediction in the online adversarial setting. Although there exist algorithms for obtaining notions of multicalibration in the online adversarial setting, unlike batch algorithms, they work only for small finite classes of benchmark functions $F$, because they require enumerating every function $f \in F$ at every round. In contrast, omniprediction is most interesting for learning theoretic hypothesis classes $F$, which are generally continuously large. We develop a new online multicalibration algorithm that is well defined for infinite benchmark classes $F$, and is oracle efficient (i.e. for any class $F$, the algorithm has the form of an efficient reduction to a no-regret learning algorithm for $F$). The result is the first efficient online omnipredictor -- an oracle efficient prediction algorithm that can be used to simultaneously obtain no regret guarantees to all Lipschitz convex loss functions. For the class $F$ of linear functions, we show how to make our algorithm efficient in the worst case. Also, we show upper and lower bounds on the extent to which our rates can be improved: our oracle efficient algorithm actually promises a stronger guarantee called swap-omniprediction, and we prove a lower bound showing that obtaining $O(\sqrt{T})$ bounds for swap-omniprediction is impossible in the online setting. On the other hand, we give a (non-oracle efficient) algorithm which can obtain the optimal $O(\sqrt{T})$ omniprediction bounds without going through multicalibration, giving an information theoretic separation between these two solution concepts.
Batch Multivalid Conformal Prediction
Sep 30, 2022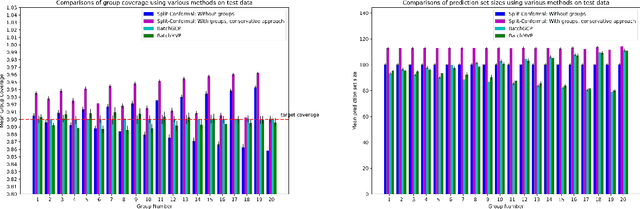
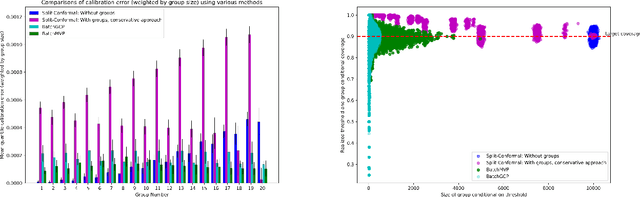
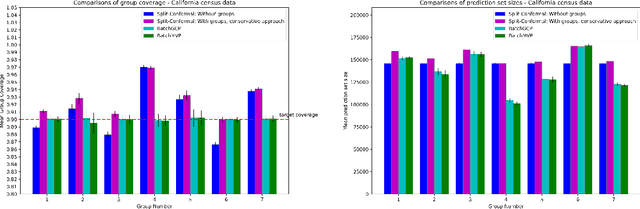
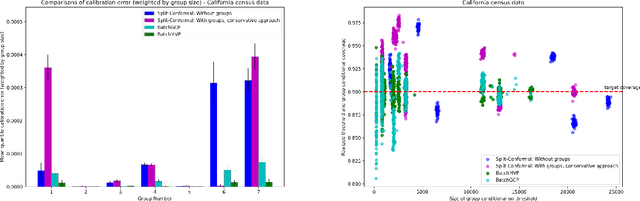
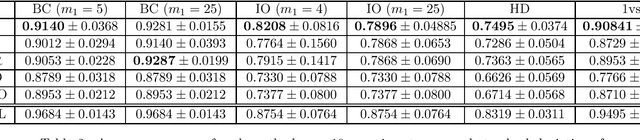
We develop fast distribution-free conformal prediction algorithms for obtaining multivalid coverage on exchangeable data in the batch setting. Multivalid coverage guarantees are stronger than marginal coverage guarantees in two ways: (1) They hold even conditional on group membership -- that is, the target coverage level $1-\alpha$ holds conditionally on membership in each of an arbitrary (potentially intersecting) group in a finite collection $\mathcal{G}$ of regions in the feature space. (2) They hold even conditional on the value of the threshold used to produce the prediction set on a given example. In fact multivalid coverage guarantees hold even when conditioning on group membership and threshold value simultaneously. We give two algorithms: both take as input an arbitrary non-conformity score and an arbitrary collection of possibly intersecting groups $\mathcal{G}$, and then can equip arbitrary black-box predictors with prediction sets. Our first algorithm (BatchGCP) is a direct extension of quantile regression, needs to solve only a single convex minimization problem, and produces an estimator which has group-conditional guarantees for each group in $\mathcal{G}$. Our second algorithm (BatchMVP) is iterative, and gives the full guarantees of multivalid conformal prediction: prediction sets that are valid conditionally both on group membership and non-conformity threshold. We evaluate the performance of both of our algorithms in an extensive set of experiments. Code to replicate all of our experiments can be found at https://github.com/ProgBelarus/BatchMultivalidConformal
Multicalibrated Regression for Downstream Fairness
Sep 15, 2022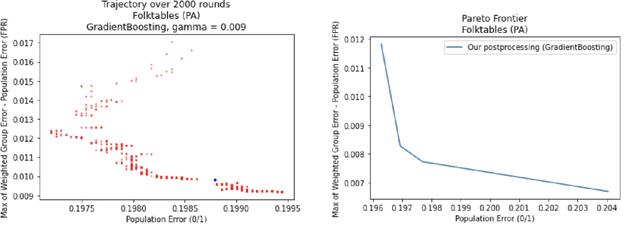
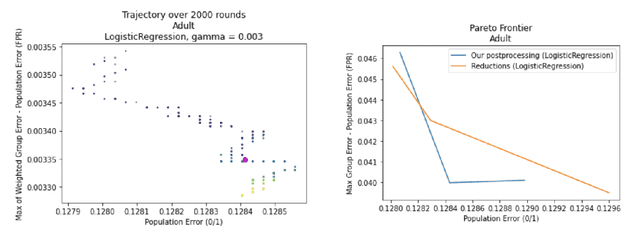
We show how to take a regression function $\hat{f}$ that is appropriately ``multicalibrated'' and efficiently post-process it into an approximately error minimizing classifier satisfying a large variety of fairness constraints. The post-processing requires no labeled data, and only a modest amount of unlabeled data and computation. The computational and sample complexity requirements of computing $\hat f$ are comparable to the requirements for solving a single fair learning task optimally, but it can in fact be used to solve many different downstream fairness-constrained learning problems efficiently. Our post-processing method easily handles intersecting groups, generalizing prior work on post-processing regression functions to satisfy fairness constraints that only applied to disjoint groups. Our work extends recent work showing that multicalibrated regression functions are ``omnipredictors'' (i.e. can be post-processed to optimally solve unconstrained ERM problems) to constrained optimization.
Practical Adversarial Multivalid Conformal Prediction
Jun 02, 2022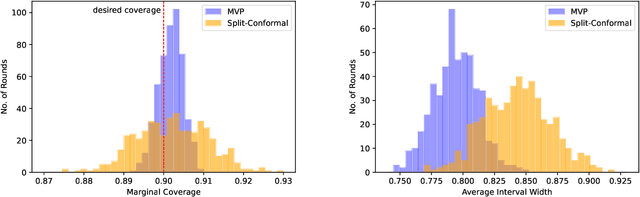
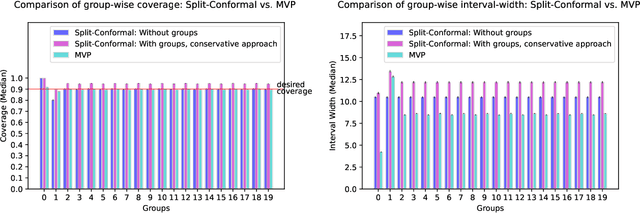
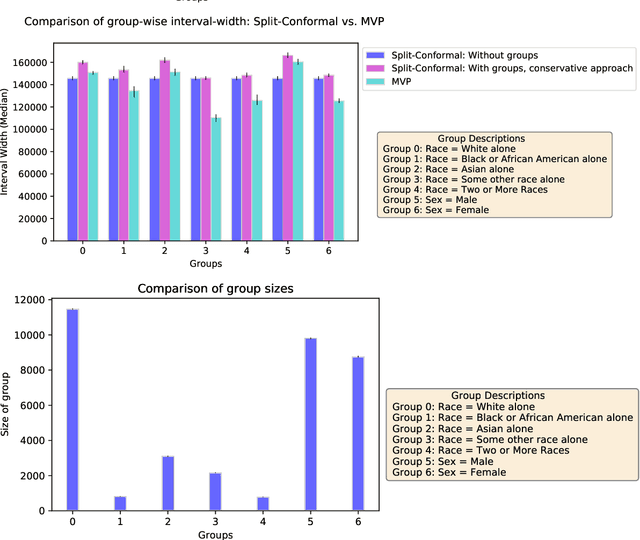
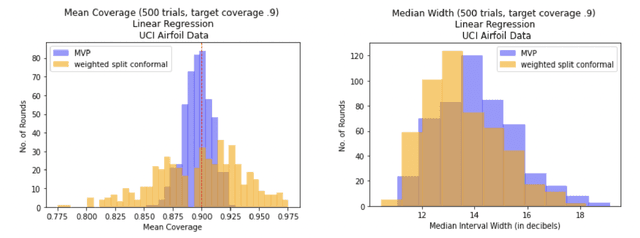
We give a simple, generic conformal prediction method for sequential prediction that achieves target empirical coverage guarantees against adversarially chosen data. It is computationally lightweight -- comparable to split conformal prediction -- but does not require having a held-out validation set, and so all data can be used for training models from which to derive a conformal score. It gives stronger than marginal coverage guarantees in two ways. First, it gives threshold calibrated prediction sets that have correct empirical coverage even conditional on the threshold used to form the prediction set from the conformal score. Second, the user can specify an arbitrary collection of subsets of the feature space -- possibly intersecting -- and the coverage guarantees also hold conditional on membership in each of these subsets. We call our algorithm MVP, short for MultiValid Prediction. We give both theory and an extensive set of empirical evaluations.
Distributionally Robust Data Join
Feb 11, 2022

Suppose we are given two datasets: a labeled dataset and unlabeled dataset which also has additional auxiliary features not present in the first dataset. What is the most principled way to use these datasets together to construct a predictor? The answer should depend upon whether these datasets are generated by the same or different distributions over their mutual feature sets, and how similar the test distribution will be to either of those distributions. In many applications, the two datasets will likely follow different distributions, but both may be close to the test distribution. We introduce the problem of building a predictor which minimizes the maximum loss over all probability distributions over the original features, auxiliary features, and binary labels, whose Wasserstein distance is $r_1$ away from the empirical distribution over the labeled dataset and $r_2$ away from that of the unlabeled dataset. This can be thought of as a generalization of distributionally robust optimization (DRO), which allows for two data sources, one of which is unlabeled and may contain auxiliary features.
Adaptive Machine Unlearning
Jun 08, 2021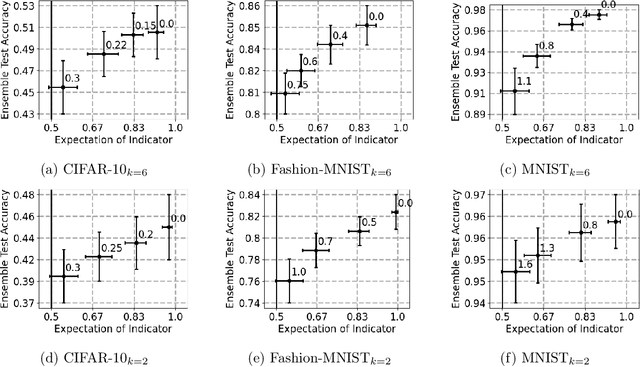
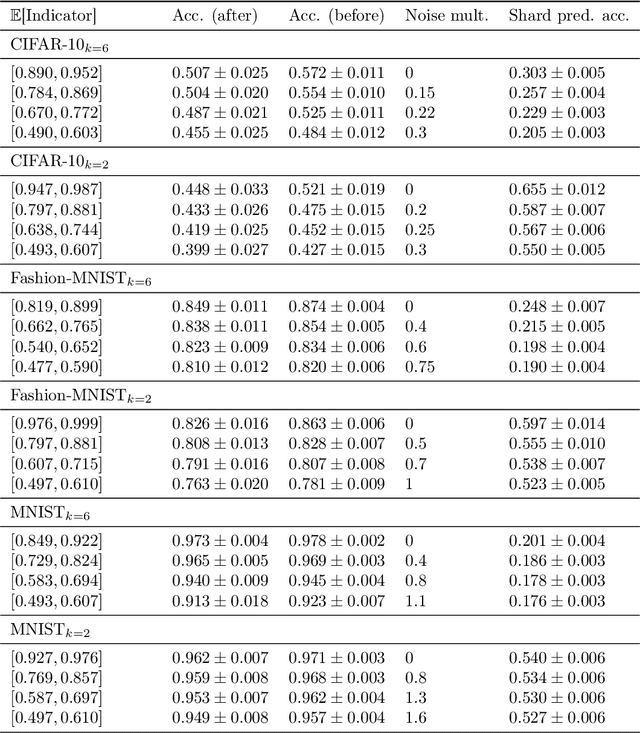
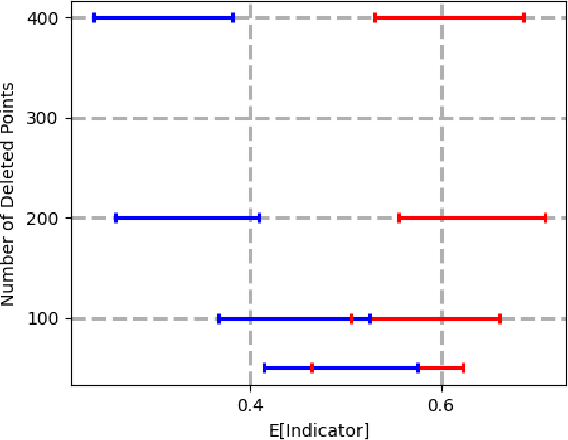
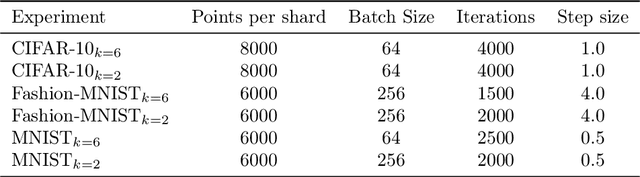
Data deletion algorithms aim to remove the influence of deleted data points from trained models at a cheaper computational cost than fully retraining those models. However, for sequences of deletions, most prior work in the non-convex setting gives valid guarantees only for sequences that are chosen independently of the models that are published. If people choose to delete their data as a function of the published models (because they don't like what the models reveal about them, for example), then the update sequence is adaptive. In this paper, we give a general reduction from deletion guarantees against adaptive sequences to deletion guarantees against non-adaptive sequences, using differential privacy and its connection to max information. Combined with ideas from prior work which give guarantees for non-adaptive deletion sequences, this leads to extremely flexible algorithms able to handle arbitrary model classes and training methodologies, giving strong provable deletion guarantees for adaptive deletion sequences. We show in theory how prior work for non-convex models fails against adaptive deletion sequences, and use this intuition to design a practical attack against the SISA algorithm of Bourtoule et al. [2021] on CIFAR-10, MNIST, Fashion-MNIST.