 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Group Fairness in Strategic Classification
Oct 03, 2024In strategic classification, agents manipulate their features, at a cost, to receive a positive classification outcome from the learner's classifier. The goal of the learner in such settings is to learn a classifier that is robust to strategic manipulations. While the majority of works in this domain consider accuracy as the primary objective of the learner, in this work, we consider learning objectives that have group fairness guarantees in addition to accuracy guarantees. We work with the minimax group fairness notion that asks for minimizing the maximal group error rate across population groups. We formalize a fairness-aware Stackelberg game between a population of agents consisting of several groups, with each group having its own cost function, and a learner in the agnostic PAC setting in which the learner is working with a hypothesis class H. When the cost functions of the agents are separable, we show the existence of an efficient algorithm that finds an approximately optimal deterministic classifier for the learner when the number of groups is small. This algorithm remains efficient, both statistically and computationally, even when H is the set of all classifiers. We then consider cost functions that are not necessarily separable and show the existence of oracle-efficient algorithms that find approximately optimal randomized classifiers for the learner when H has finite strategic VC dimension. These algorithms work under the assumption that the learner is fully transparent: the learner draws a classifier from its distribution (randomized classifier) before the agents respond by manipulating their feature vectors. We highlight the effectiveness of such transparency in developing oracle-efficient algorithms. We conclude with verifying the efficacy of our algorithms on real data by conducting an experimental analysis.
Bayesian Strategic Classification
Feb 13, 2024In strategic classification, agents modify their features, at a cost, to ideally obtain a positive classification from the learner's classifier. The typical response of the learner is to carefully modify their classifier to be robust to such strategic behavior. When reasoning about agent manipulations, most papers that study strategic classification rely on the following strong assumption: agents fully know the exact parameters of the deployed classifier by the learner. This often is an unrealistic assumption when using complex or proprietary machine learning techniques in real-world prediction tasks. We initiate the study of partial information release by the learner in strategic classification. We move away from the traditional assumption that agents have full knowledge of the classifier. Instead, we consider agents that have a common distributional prior on which classifier the learner is using. The learner in our model can reveal truthful, yet not necessarily complete, information about the deployed classifier to the agents. The learner's goal is to release just enough information about the classifier to maximize accuracy. We show how such partial information release can, counter-intuitively, benefit the learner's accuracy, despite increasing agents' abilities to manipulate. We show that while it is intractable to compute the best response of an agent in the general case, there exist oracle-efficient algorithms that can solve the best response of the agents when the learner's hypothesis class is the class of linear classifiers, or when the agents' cost function satisfies a natural notion of submodularity as we define. We then turn our attention to the learner's optimization problem and provide both positive and negative results on the algorithmic problem of how much information the learner should release about the classifier to maximize their expected accuracy.
Sequential Strategic Screening
Feb 11, 2023We initiate the study of strategic behavior in screening processes with multiple classifiers. We focus on two contrasting settings: a conjunctive setting in which an individual must satisfy all classifiers simultaneously, and a sequential setting in which an individual to succeed must satisfy classifiers one at a time. In other words, we introduce the combination of strategic classification with screening processes. We show that sequential screening pipelines exhibit new and surprising behavior where individuals can exploit the sequential ordering of the tests to zig-zag between classifiers without having to simultaneously satisfy all of them. We demonstrate an individual can obtain a positive outcome using a limited manipulation budget even when far from the intersection of the positive regions of every classifier. Finally, we consider a learner whose goal is to design a sequential screening process that is robust to such manipulations, and provide a construction for the learner that optimizes a natural objective.
Multiaccurate Proxies for Downstream Fairness
Jul 09, 2021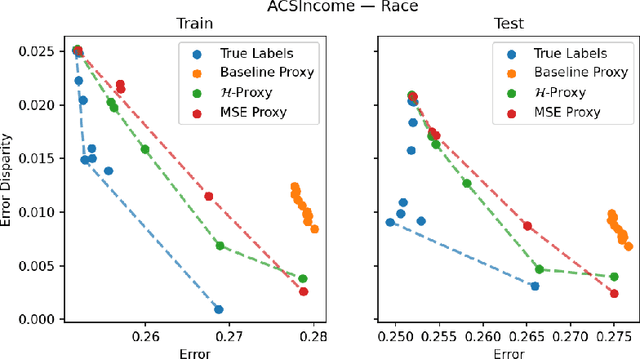
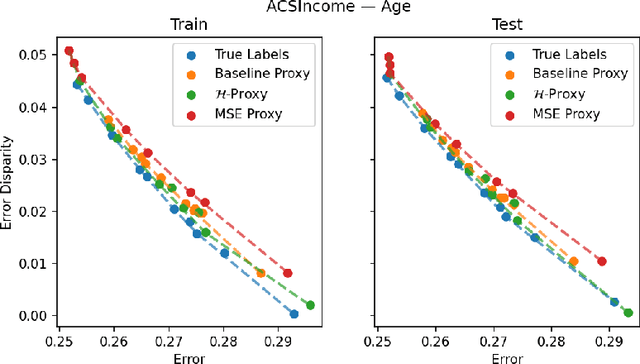
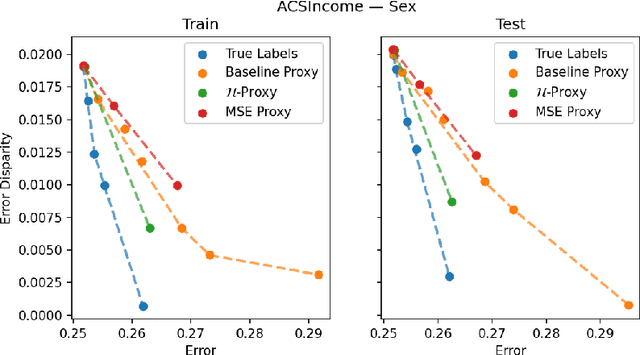
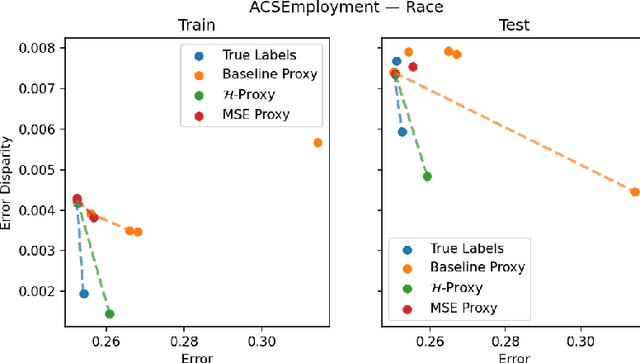
We study the problem of training a model that must obey demographic fairness conditions when the sensitive features are not available at training time -- in other words, how can we train a model to be fair by race when we don't have data about race? We adopt a fairness pipeline perspective, in which an "upstream" learner that does have access to the sensitive features will learn a proxy model for these features from the other attributes. The goal of the proxy is to allow a general "downstream" learner -- with minimal assumptions on their prediction task -- to be able to use the proxy to train a model that is fair with respect to the true sensitive features. We show that obeying multiaccuracy constraints with respect to the downstream model class suffices for this purpose, and provide sample- and oracle efficient-algorithms and generalization bounds for learning such proxies. In general, multiaccuracy can be much easier to satisfy than classification accuracy, and can be satisfied even when the sensitive features are hard to predict.
Adaptive Machine Unlearning
Jun 08, 2021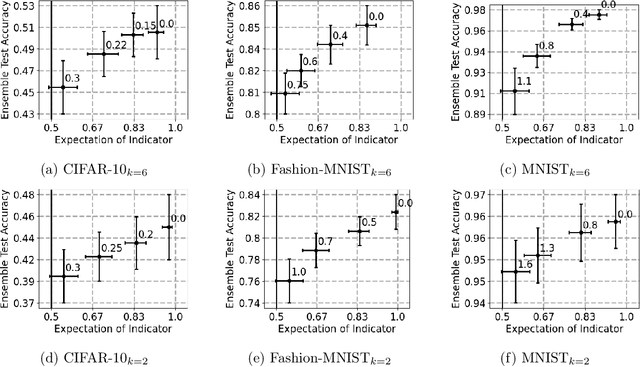
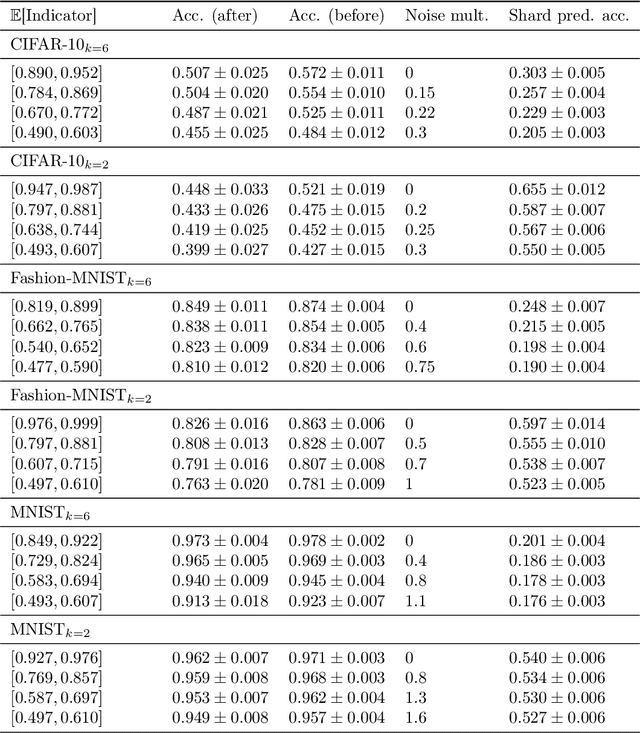
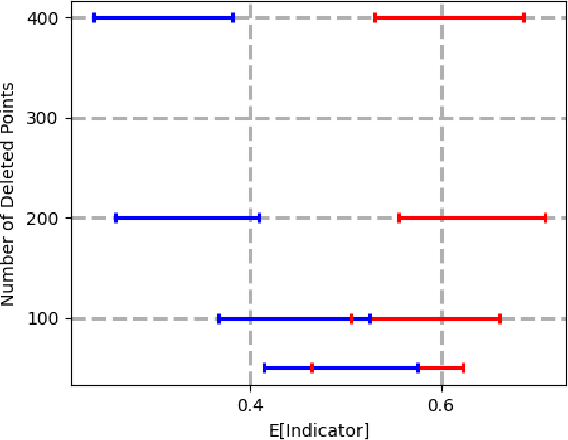
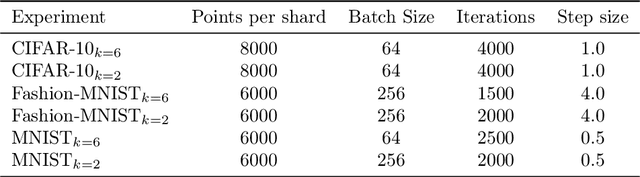
Data deletion algorithms aim to remove the influence of deleted data points from trained models at a cheaper computational cost than fully retraining those models. However, for sequences of deletions, most prior work in the non-convex setting gives valid guarantees only for sequences that are chosen independently of the models that are published. If people choose to delete their data as a function of the published models (because they don't like what the models reveal about them, for example), then the update sequence is adaptive. In this paper, we give a general reduction from deletion guarantees against adaptive sequences to deletion guarantees against non-adaptive sequences, using differential privacy and its connection to max information. Combined with ideas from prior work which give guarantees for non-adaptive deletion sequences, this leads to extremely flexible algorithms able to handle arbitrary model classes and training methodologies, giving strong provable deletion guarantees for adaptive deletion sequences. We show in theory how prior work for non-convex models fails against adaptive deletion sequences, and use this intuition to design a practical attack against the SISA algorithm of Bourtoule et al. [2021] on CIFAR-10, MNIST, Fashion-MNIST.
Lexicographically Fair Learning: Algorithms and Generalization
Feb 16, 2021We extend the notion of minimax fairness in supervised learning problems to its natural conclusion: lexicographic minimax fairness (or lexifairness for short). Informally, given a collection of demographic groups of interest, minimax fairness asks that the error of the group with the highest error be minimized. Lexifairness goes further and asks that amongst all minimax fair solutions, the error of the group with the second highest error should be minimized, and amongst all of those solutions, the error of the group with the third highest error should be minimized, and so on. Despite its naturalness, correctly defining lexifairness is considerably more subtle than minimax fairness, because of inherent sensitivity to approximation error. We give a notion of approximate lexifairness that avoids this issue, and then derive oracle-efficient algorithms for finding approximately lexifair solutions in a very general setting. When the underlying empirical risk minimization problem absent fairness constraints is convex (as it is, for example, with linear and logistic regression), our algorithms are provably efficient even in the worst case. Finally, we show generalization bounds -- approximate lexifairness on the training sample implies approximate lexifairness on the true distribution with high probability. Our ability to prove generalization bounds depends on our choosing definitions that avoid the instability of naive definitions.
Descent-to-Delete: Gradient-Based Methods for Machine Unlearning
Jul 06, 2020
We study the data deletion problem for convex models. By leveraging techniques from convex optimization and reservoir sampling, we give the first data deletion algorithms that are able to handle an arbitrarily long sequence of adversarial updates while promising both per-deletion run-time and steady-state error that do not grow with the length of the update sequence. We also introduce several new conceptual distinctions: for example, we can ask that after a deletion, the entire state maintained by the optimization algorithm is statistically indistinguishable from the state that would have resulted had we retrained, or we can ask for the weaker condition that only the observable output is statistically indistinguishable from the observable output that would have resulted from retraining. We are able to give more efficient deletion algorithms under this weaker deletion criterion.
Algorithms and Learning for Fair Portfolio Design
Jun 12, 2020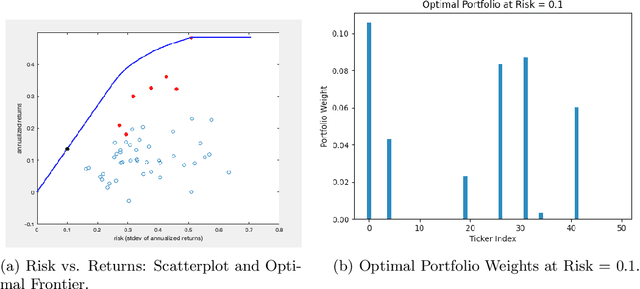
We consider a variation on the classical finance problem of optimal portfolio design. In our setting, a large population of consumers is drawn from some distribution over risk tolerances, and each consumer must be assigned to a portfolio of lower risk than her tolerance. The consumers may also belong to underlying groups (for instance, of demographic properties or wealth), and the goal is to design a small number of portfolios that are fair across groups in a particular and natural technical sense. Our main results are algorithms for optimal and near-optimal portfolio design for both social welfare and fairness objectives, both with and without assumptions on the underlying group structure. We describe an efficient algorithm based on an internal two-player zero-sum game that learns near-optimal fair portfolios ex ante and show experimentally that it can be used to obtain a small set of fair portfolios ex post as well. For the special but natural case in which group structure coincides with risk tolerances (which models the reality that wealthy consumers generally tolerate greater risk), we give an efficient and optimal fair algorithm. We also provide generalization guarantees for the underlying risk distribution that has no dependence on the number of portfolios and illustrate the theory with simulation results.
A New Analysis of Differential Privacy's Generalization Guarantees
Sep 09, 2019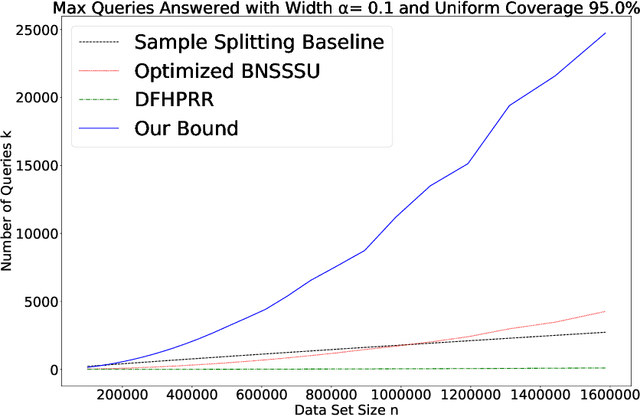
We give a new proof of the "transfer theorem" underlying adaptive data analysis: that any mechanism for answering adaptively chosen statistical queries that is differentially private and sample-accurate is also accurate out-of-sample. Our new proof is elementary and gives structural insights that we expect will be useful elsewhere. We show: 1) that differential privacy ensures that the expectation of any query on the posterior distribution on datasets induced by the transcript of the interaction is close to its true value on the data distribution, and 2) sample accuracy on its own ensures that any query answer produced by the mechanism is close to its posterior expectation with high probability. This second claim follows from a thought experiment in which we imagine that the dataset is resampled from the posterior distribution after the mechanism has committed to its answers. The transfer theorem then follows by summing these two bounds, and in particular, avoids the "monitor argument" used to derive high probability bounds in prior work. An upshot of our new proof technique is that the concrete bounds we obtain are substantially better than the best previously known bounds, even though the improvements are in the constants, rather than the asymptotics (which are known to be tight). As we show, our new bounds outperform the naive "sample-splitting" baseline at dramatically smaller dataset sizes compared to the previous state of the art, bringing techniques from this literature closer to practicality.
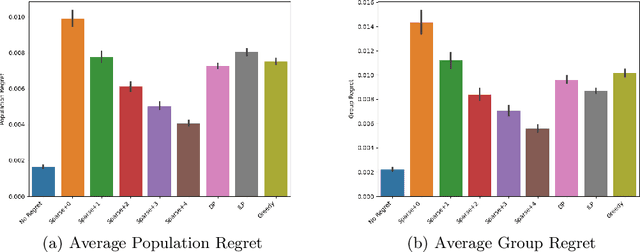
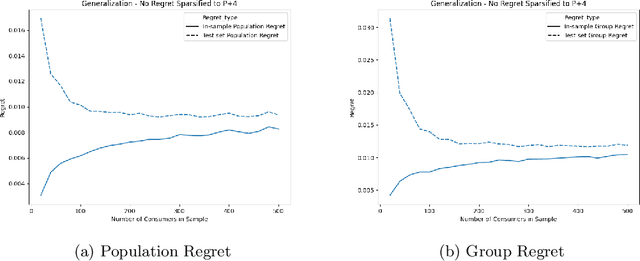
Average Individual Fairness: Algorithms, Generalization and Experiments
May 25, 2019

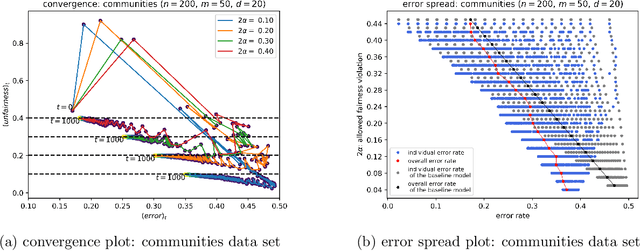
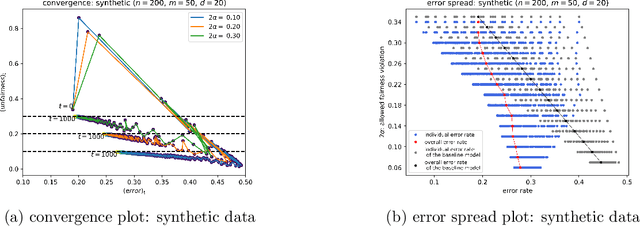
We propose a new family of fairness definitions for classification problems that combine some of the best properties of both statistical and individual notions of fairness. We posit not only a distribution over individuals, but also a distribution over (or collection of) classification tasks. We then ask that standard statistics (such as error or false positive/negative rates) be (approximately) equalized across individuals, where the rate is defined as an expectation over the classification tasks. Because we are no longer averaging over coarse groups (such as race or gender), this is a semantically meaningful individual-level constraint. Given a sample of individuals and classification problems, we design an oracle-efficient algorithm (i.e. one that is given access to any standard, fairness-free learning heuristic) for the fair empirical risk minimization task. We also show that given sufficiently many samples, the ERM solution generalizes in two directions: both to new individuals, and to new classification tasks, drawn from their corresponding distributions. Finally we implement our algorithm and empirically verify its effectiveness.