 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Adaptive Machine Unlearning
Jun 08, 2021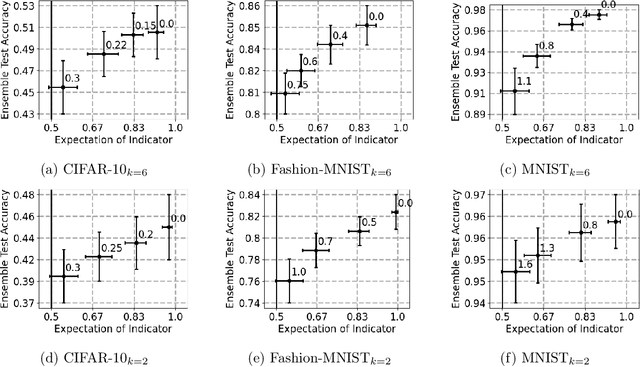
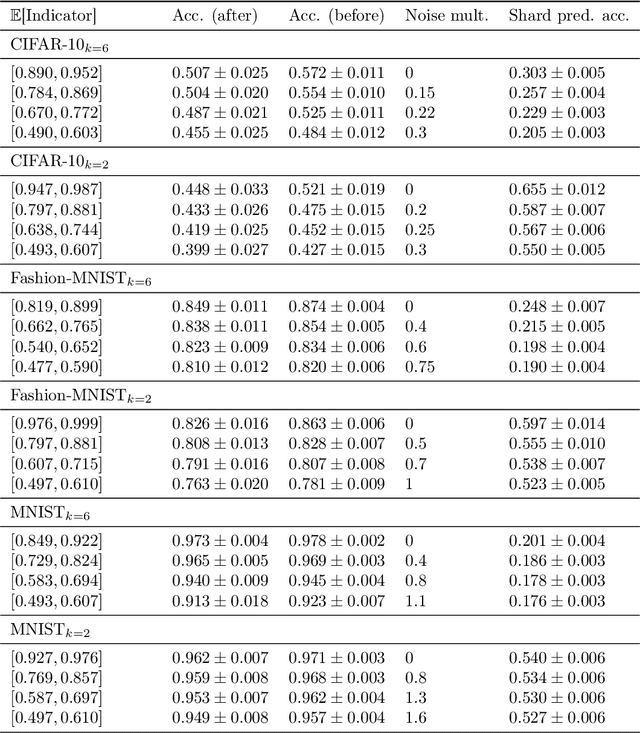
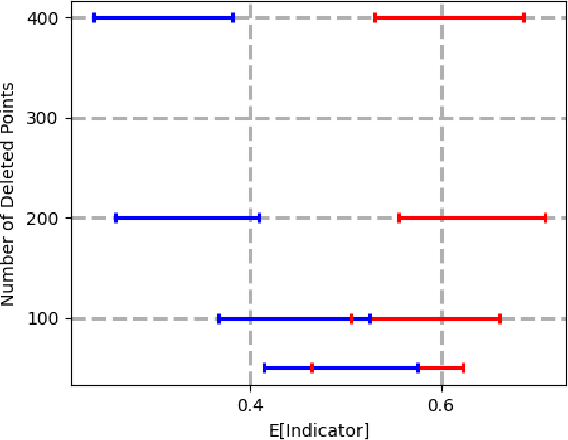
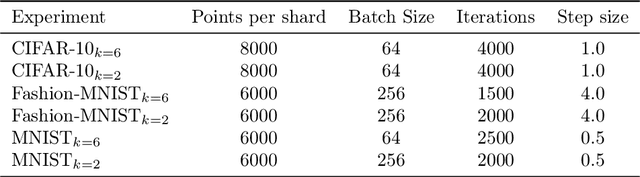
Data deletion algorithms aim to remove the influence of deleted data points from trained models at a cheaper computational cost than fully retraining those models. However, for sequences of deletions, most prior work in the non-convex setting gives valid guarantees only for sequences that are chosen independently of the models that are published. If people choose to delete their data as a function of the published models (because they don't like what the models reveal about them, for example), then the update sequence is adaptive. In this paper, we give a general reduction from deletion guarantees against adaptive sequences to deletion guarantees against non-adaptive sequences, using differential privacy and its connection to max information. Combined with ideas from prior work which give guarantees for non-adaptive deletion sequences, this leads to extremely flexible algorithms able to handle arbitrary model classes and training methodologies, giving strong provable deletion guarantees for adaptive deletion sequences. We show in theory how prior work for non-convex models fails against adaptive deletion sequences, and use this intuition to design a practical attack against the SISA algorithm of Bourtoule et al. [2021] on CIFAR-10, MNIST, Fashion-MNIST.
GABO: Graph Augmentations with Bi-level Optimization
Apr 01, 2021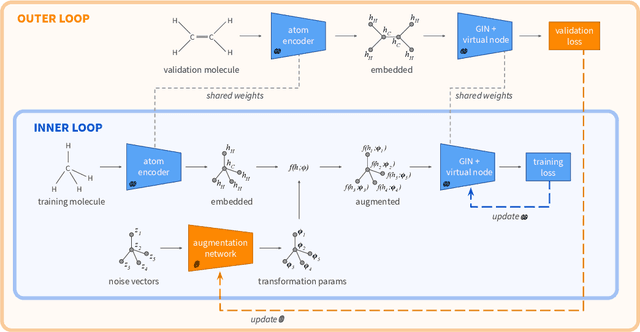
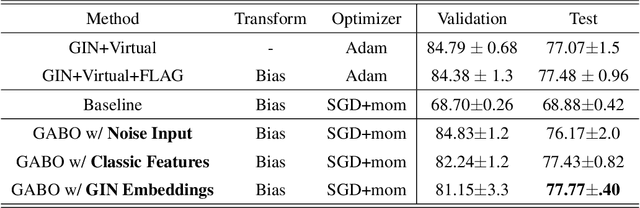
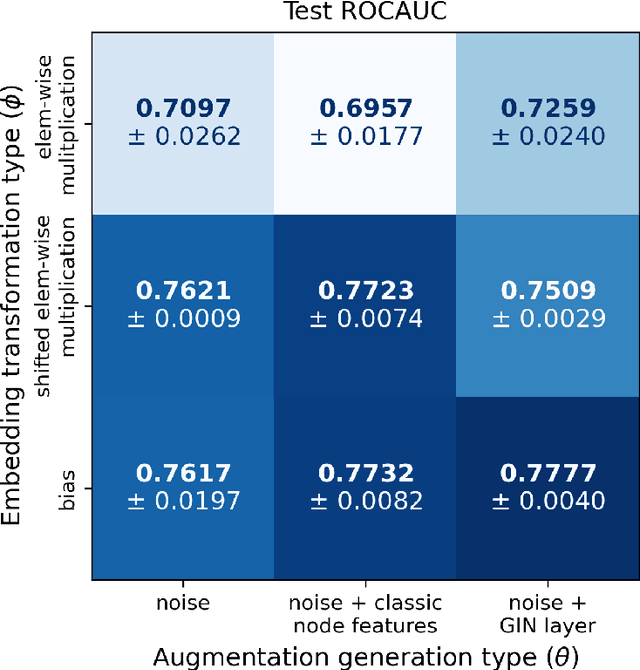
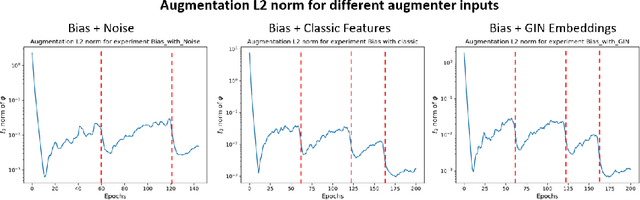
Data augmentation refers to a wide range of techniques for improving model generalization by augmenting training examples. Oftentimes such methods require domain knowledge about the dataset at hand, spawning a plethora of recent literature surrounding automated techniques for data augmentation. In this work we apply one such method, bilevel optimization, to tackle the problem of graph classification on the ogbg-molhiv dataset. Our best performing augmentation achieved a test ROCAUC score of 77.77 % with a GIN+virtual classifier, which makes it the most effective augmenter for this classifier on the leaderboard. This framework combines a GIN layer augmentation generator with a bias transformation and outperforms the same classifier augmented using the state-of-the-art FLAG augmentation.
Differentially Private Normalizing Flows for Privacy-Preserving Density Estimation
Mar 25, 2021

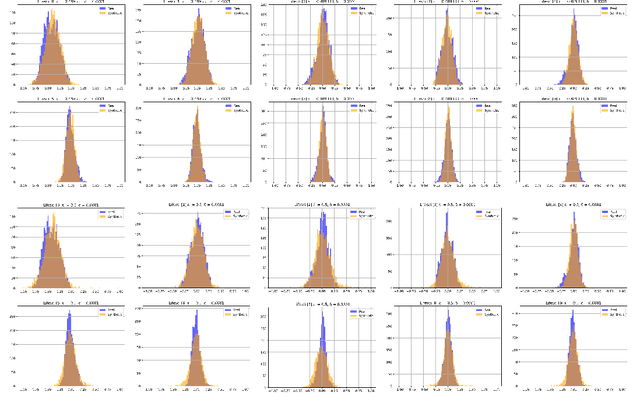

Normalizing flow models have risen as a popular solution to the problem of density estimation, enabling high-quality synthetic data generation as well as exact probability density evaluation. However, in contexts where individuals are directly associated with the training data, releasing such a model raises privacy concerns. In this work, we propose the use of normalizing flow models that provide explicit differential privacy guarantees as a novel approach to the problem of privacy-preserving density estimation. We evaluate the efficacy of our approach empirically using benchmark datasets, and we demonstrate that our method substantially outperforms previous state-of-the-art approaches. We additionally show how our algorithm can be applied to the task of differentially private anomaly detection.
Differentially Private Mixed-Type Data Generation For Unsupervised Learning
Dec 06, 2019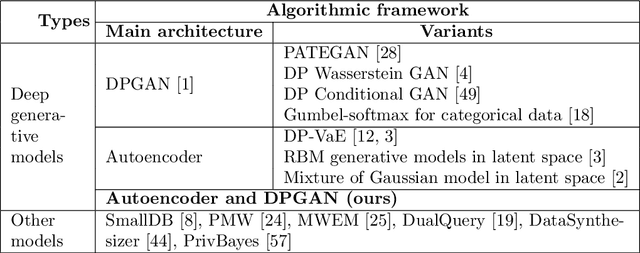
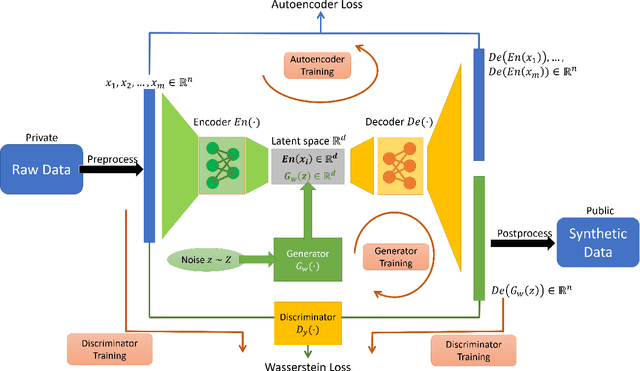
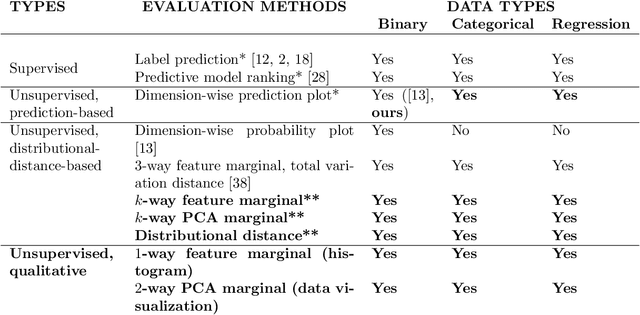

In this work we introduce the DP-auto-GAN framework for synthetic data generation, which combines the low dimensional representation of autoencoders with the flexibility of Generative Adversarial Networks (GANs). This framework can be used to take in raw sensitive data, and privately train a model for generating synthetic data that will satisfy the same statistical properties as the original data. This learned model can be used to generate arbitrary amounts of publicly available synthetic data, which can then be freely shared due to the post-processing guarantees of differential privacy. Our framework is applicable to unlabeled mixed-type data, that may include binary, categorical, and real-valued data. We implement this framework on both unlabeled binary data (MIMIC-III) and unlabeled mixed-type data (ADULT). We also introduce new metrics for evaluating the quality of synthetic mixed-type data, particularly in unsupervised settings.