 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient privacy loss accounting for subsampling and random allocation
Feb 19, 2026We consider the privacy amplification properties of a sampling scheme in which a user's data is used in $k$ steps chosen randomly and uniformly from a sequence (or set) of $t$ steps. This sampling scheme has been recently applied in the context of differentially private optimization (Chua et al., 2024a; Choquette-Choo et al., 2025) and communication-efficient high-dimensional private aggregation (Asi et al., 2025), where it was shown to have utility advantages over the standard Poisson sampling. Theoretical analyses of this sampling scheme (Feldman & Shenfeld, 2025; Dong et al., 2025) lead to bounds that are close to those of Poisson sampling, yet still have two significant shortcomings. First, in many practical settings, the resulting privacy parameters are not tight due to the approximation steps in the analysis. Second, the computed parameters are either the hockey stick or Renyi divergence, both of which introduce overheads when used in privacy loss accounting. In this work, we demonstrate that the privacy loss distribution (PLD) of random allocation applied to any differentially private algorithm can be computed efficiently. When applied to the Gaussian mechanism, our results demonstrate that the privacy-utility trade-off for random allocation is at least as good as that of Poisson subsampling. In particular, random allocation is better suited for training via DP-SGD. To support these computations, our work develops new tools for general privacy loss accounting based on a notion of PLD realization. This notion allows us to extend accurate privacy loss accounting to subsampling which previously required manual noise-mechanism-specific analysis.
Near-Optimal Private Linear Regression via Iterative Hessian Mixing
Jan 12, 2026We study differentially private ordinary least squares (DP-OLS) with bounded data. The dominant approach, adaptive sufficient-statistics perturbation (AdaSSP), adds an adaptively chosen perturbation to the sufficient statistics, namely, the matrix $X^{\top}X$ and the vector $X^{\top}Y$, and is known to achieve near-optimal accuracy and to have strong empirical performance. In contrast, methods that rely on Gaussian-sketching, which ensure differential privacy by pre-multiplying the data with a random Gaussian matrix, are widely used in federated and distributed regression, yet remain relatively uncommon for DP-OLS. In this work, we introduce the iterative Hessian mixing, a novel DP-OLS algorithm that relies on Gaussian sketches and is inspired by the iterative Hessian sketch algorithm. We provide utility analysis for the iterative Hessian mixing as well as a new analysis for the previous methods that rely on Gaussian sketches. Then, we show that our new approach circumvents the intrinsic limitations of the prior methods and provides non-trivial improvements over AdaSSP. We conclude by running an extensive set of experiments across standard benchmarks to demonstrate further that our approach consistently outperforms these prior baselines.
The Gaussian Mixing Mechanism: Renyi Differential Privacy via Gaussian Sketches
May 30, 2025Gaussian sketching, which consists of pre-multiplying the data with a random Gaussian matrix, is a widely used technique for multiple problems in data science and machine learning, with applications spanning computationally efficient optimization, coded computing, and federated learning. This operation also provides differential privacy guarantees due to its inherent randomness. In this work, we revisit this operation through the lens of Renyi Differential Privacy (RDP), providing a refined privacy analysis that yields significantly tighter bounds than prior results. We then demonstrate how this improved analysis leads to performance improvement in different linear regression settings, establishing theoretical utility guarantees. Empirically, our methods improve performance across multiple datasets and, in several cases, reduce runtime.
How Well Can Differential Privacy Be Audited in One Run?
Mar 10, 2025Recent methods for auditing the privacy of machine learning algorithms have improved computational efficiency by simultaneously intervening on multiple training examples in a single training run. Steinke et al. (2024) prove that one-run auditing indeed lower bounds the true privacy parameter of the audited algorithm, and give impressive empirical results. Their work leaves open the question of how precisely one-run auditing can uncover the true privacy parameter of an algorithm, and how that precision depends on the audited algorithm. In this work, we characterize the maximum achievable efficacy of one-run auditing and show that one-run auditing can only perfectly uncover the true privacy parameters of algorithms whose structure allows the effects of individual data elements to be isolated. Our characterization helps reveal how and when one-run auditing is still a promising technique for auditing real machine learning algorithms, despite these fundamental gaps.
Privacy amplification by random allocation
Feb 12, 2025We consider the privacy guarantees of an algorithm in which a user's data is used in $k$ steps randomly and uniformly chosen from a sequence (or set) of $t$ differentially private steps. We demonstrate that the privacy guarantees of this sampling scheme can be upper bound by the privacy guarantees of the well-studied independent (or Poisson) subsampling in which each step uses the user's data with probability $(1+ o(1))k/t $. Further, we provide two additional analysis techniques that lead to numerical improvements in some parameter regimes. The case of $k=1$ has been previously studied in the context of DP-SGD in Balle et al. (2020) and very recently in Chua et al. (2024). Privacy analysis of Balle et al. (2020) relies on privacy amplification by shuffling which leads to overly conservative bounds. Privacy analysis of Chua et al. (2024a) relies on Monte Carlo simulations that are computationally prohibitive in many practical scenarios and have additional inherent limitations.
Generalization in the Face of Adaptivity: A Bayesian Perspective
Jun 20, 2021
Repeated use of a data sample via adaptively chosen queries can rapidly lead to overfitting, wherein the issued queries yield answers on the sample that differ wildly from the values of those queries on the underlying data distribution. Differential privacy provides a tool to ensure generalization despite adaptively-chosen queries, but its worst-case nature means that it cannot, for example, yield improved results for low-variance queries. In this paper, we give a simple new characterization that illuminates the core problem of adaptive data analysis. We show explicitly that the harms of adaptivity come from the covariance between the behavior of future queries and a Bayes factor-based measure of how much information about the data sample was encoded in the responses given to past queries. We leverage this intuition to introduce a new stability notion; we then use it to prove new generalization results for the most basic noise-addition mechanisms (Laplace and Gaussian noise addition), with guarantees that scale with the variance of the queries rather than the square of their range. Our characterization opens the door to new insights and new algorithms for the fundamental problem of achieving generalization in adaptive data analysis.
A New Analysis of Differential Privacy's Generalization Guarantees
Sep 09, 2019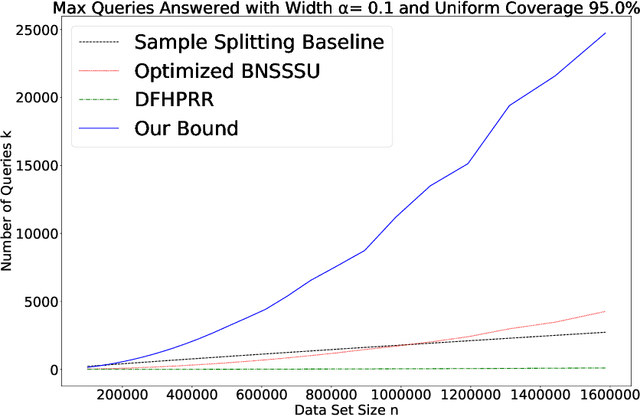
We give a new proof of the "transfer theorem" underlying adaptive data analysis: that any mechanism for answering adaptively chosen statistical queries that is differentially private and sample-accurate is also accurate out-of-sample. Our new proof is elementary and gives structural insights that we expect will be useful elsewhere. We show: 1) that differential privacy ensures that the expectation of any query on the posterior distribution on datasets induced by the transcript of the interaction is close to its true value on the data distribution, and 2) sample accuracy on its own ensures that any query answer produced by the mechanism is close to its posterior expectation with high probability. This second claim follows from a thought experiment in which we imagine that the dataset is resampled from the posterior distribution after the mechanism has committed to its answers. The transfer theorem then follows by summing these two bounds, and in particular, avoids the "monitor argument" used to derive high probability bounds in prior work. An upshot of our new proof technique is that the concrete bounds we obtain are substantially better than the best previously known bounds, even though the improvements are in the constants, rather than the asymptotics (which are known to be tight). As we show, our new bounds outperform the naive "sample-splitting" baseline at dramatically smaller dataset sizes compared to the previous state of the art, bringing techniques from this literature closer to practicality.
A necessary and sufficient stability notion for adaptive generalization
Jun 03, 2019We introduce a new notion of the stability of computations, which holds under post-processing and adaptive composition, and show that the notion is both necessary and sufficient to ensure generalization in the face of adaptivity, for any computations that respond to bounded-sensitivity linear queries while providing accuracy with respect to the data sample set. The stability notion is based on quantifying the effect of observing a computation's outputs on the posterior over the data sample elements. We show a separation between this stability notion and previously studied notions.