 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning with Limited Information in the Sliding Window Model
Jan 07, 2026Motivated by recent work on the experts problem in the streaming model, we consider the experts problem in the sliding window model. The sliding window model is a well-studied model that captures applications such as traffic monitoring, epidemic tracking, and automated trading, where recent information is more valuable than older data. Formally, we have $n$ experts, $T$ days, the ability to query the predictions of $q$ experts on each day, a limited amount of memory, and should achieve the (near-)optimal regret $\sqrt{nW}\text{polylog}(nT)$ regret over any window of the last $W$ days. While it is impossible to achieve such regret with $1$ query, we show that with $2$ queries we can achieve such regret and with only $\text{polylog}(nT)$ bits of memory. Not only are our algorithms optimal for sliding windows, but we also show for every interval $\mathcal{I}$ of days that we achieve $\sqrt{n|\mathcal{I}|}\text{polylog}(nT)$ regret with $2$ queries and only $\text{polylog}(nT)$ bits of memory, providing an exponential improvement on the memory of previous interval regret algorithms. Building upon these techniques, we address the bandit problem in data streams, where $q=1$, achieving $n T^{2/3}\text{polylog}(T)$ regret with $\text{polylog}(nT)$ memory, which is the first sublinear regret in the streaming model in the bandit setting with polylogarithmic memory; this can be further improved to the optimal $\mathcal{O}(\sqrt{nT})$ regret if the best expert's losses are in a random order.
The Space Complexity of Learning-Unlearning Algorithms
Jun 16, 2025We study the memory complexity of machine unlearning algorithms that provide strong data deletion guarantees to the users. Formally, consider an algorithm for a particular learning task that initially receives a training dataset. Then, after learning, it receives data deletion requests from a subset of users (of arbitrary size), and the goal of unlearning is to perform the task as if the learner never received the data of deleted users. In this paper, we ask how many bits of storage are needed to be able to delete certain training samples at a later time. We focus on the task of realizability testing, where the goal is to check whether the remaining training samples are realizable within a given hypothesis class \(\mathcal{H}\). Toward that end, we first provide a negative result showing that the VC dimension is not a characterization of the space complexity of unlearning. In particular, we provide a hypothesis class with constant VC dimension (and Littlestone dimension), but for which any unlearning algorithm for realizability testing needs to store \(\Omega(n)\)-bits, where \(n\) denotes the size of the initial training dataset. In fact, we provide a stronger separation by showing that for any hypothesis class \(\mathcal{H}\), the amount of information that the learner needs to store, so as to perform unlearning later, is lower bounded by the \textit{eluder dimension} of \(\mathcal{H}\), a combinatorial notion always larger than the VC dimension. We complement the lower bound with an upper bound in terms of the star number of the underlying hypothesis class, albeit in a stronger ticketed-memory model proposed by Ghazi et al. (2023). Since the star number for a hypothesis class is never larger than its Eluder dimension, our work highlights a fundamental separation between central and ticketed memory models for machine unlearning.
Oracle Efficient Online Multicalibration and Omniprediction
Jul 18, 2023A recent line of work has shown a surprising connection between multicalibration, a multi-group fairness notion, and omniprediction, a learning paradigm that provides simultaneous loss minimization guarantees for a large family of loss functions. Prior work studies omniprediction in the batch setting. We initiate the study of omniprediction in the online adversarial setting. Although there exist algorithms for obtaining notions of multicalibration in the online adversarial setting, unlike batch algorithms, they work only for small finite classes of benchmark functions $F$, because they require enumerating every function $f \in F$ at every round. In contrast, omniprediction is most interesting for learning theoretic hypothesis classes $F$, which are generally continuously large. We develop a new online multicalibration algorithm that is well defined for infinite benchmark classes $F$, and is oracle efficient (i.e. for any class $F$, the algorithm has the form of an efficient reduction to a no-regret learning algorithm for $F$). The result is the first efficient online omnipredictor -- an oracle efficient prediction algorithm that can be used to simultaneously obtain no regret guarantees to all Lipschitz convex loss functions. For the class $F$ of linear functions, we show how to make our algorithm efficient in the worst case. Also, we show upper and lower bounds on the extent to which our rates can be improved: our oracle efficient algorithm actually promises a stronger guarantee called swap-omniprediction, and we prove a lower bound showing that obtaining $O(\sqrt{T})$ bounds for swap-omniprediction is impossible in the online setting. On the other hand, we give a (non-oracle efficient) algorithm which can obtain the optimal $O(\sqrt{T})$ omniprediction bounds without going through multicalibration, giving an information theoretic separation between these two solution concepts.
Memory-Sample Lower Bounds for Learning Parity with Noise
Jul 05, 2021In this work, we show, for the well-studied problem of learning parity under noise, where a learner tries to learn $x=(x_1,\ldots,x_n) \in \{0,1\}^n$ from a stream of random linear equations over $\mathrm{F}_2$ that are correct with probability $\frac{1}{2}+\varepsilon$ and flipped with probability $\frac{1}{2}-\varepsilon$, that any learning algorithm requires either a memory of size $\Omega(n^2/\varepsilon)$ or an exponential number of samples. In fact, we study memory-sample lower bounds for a large class of learning problems, as characterized by [GRT'18], when the samples are noisy. A matrix $M: A \times X \rightarrow \{-1,1\}$ corresponds to the following learning problem with error parameter $\varepsilon$: an unknown element $x \in X$ is chosen uniformly at random. A learner tries to learn $x$ from a stream of samples, $(a_1, b_1), (a_2, b_2) \ldots$, where for every $i$, $a_i \in A$ is chosen uniformly at random and $b_i = M(a_i,x)$ with probability $1/2+\varepsilon$ and $b_i = -M(a_i,x)$ with probability $1/2-\varepsilon$ ($0<\varepsilon< \frac{1}{2}$). Assume that $k,\ell, r$ are such that any submatrix of $M$ of at least $2^{-k} \cdot |A|$ rows and at least $2^{-\ell} \cdot |X|$ columns, has a bias of at most $2^{-r}$. We show that any learning algorithm for the learning problem corresponding to $M$, with error, requires either a memory of size at least $\Omega\left(\frac{k \cdot \ell}{\varepsilon} \right)$, or at least $2^{\Omega(r)}$ samples. In particular, this shows that for a large class of learning problems, same as those in [GRT'18], any learning algorithm requires either a memory of size at least $\Omega\left(\frac{(\log |X|) \cdot (\log |A|)}{\varepsilon}\right)$ or an exponential number of noisy samples. Our proof is based on adapting the arguments in [Raz'17,GRT'18] to the noisy case.
The Role of Randomness and Noise in Strategic Classification
May 17, 2020We investigate the problem of designing optimal classifiers in the strategic classification setting, where the classification is part of a game in which players can modify their features to attain a favorable classification outcome (while incurring some cost). Previously, the problem has been considered from a learning-theoretic perspective and from the algorithmic fairness perspective. Our main contributions include 1. Showing that if the objective is to maximize the efficiency of the classification process (defined as the accuracy of the outcome minus the sunk cost of the qualified players manipulating their features to gain a better outcome), then using randomized classifiers (that is, ones where the probability of a given feature vector to be accepted by the classifier is strictly between 0 and 1) is necessary. 2. Showing that in many natural cases, the imposed optimal solution (in terms of efficiency) has the structure where players never change their feature vectors (the randomized classifier is structured in a way, such that the gain in the probability of being classified as a 1 does not justify the expense of changing one's features). 3. Observing that the randomized classification is not a stable best-response from the classifier's viewpoint, and that the classifier doesn't benefit from randomized classifiers without creating instability in the system. 4. Showing that in some cases, a noisier signal leads to better equilibria outcomes -- improving both accuracy and fairness when more than one subpopulation with different feature adjustment costs are involved. This is interesting from a policy perspective, since it is hard to force institutions to stick to a particular randomized classification strategy (especially in a context of a market with multiple classifiers), but it is possible to alter the information environment to make the feature signals inherently noisier.
Tracking and Improving Information in the Service of Fairness
Apr 22, 2019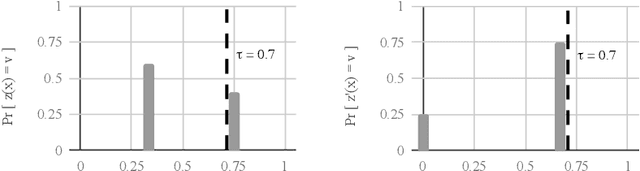
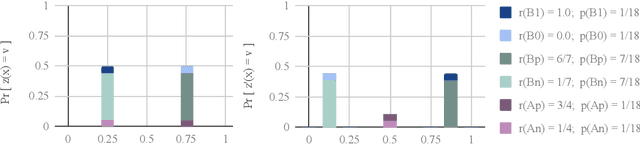
As algorithmic prediction systems have become widespread, fears that these systems may inadvertently discriminate against members of underrepresented populations have grown. With the goal of understanding fundamental principles that underpin the growing number of approaches to mitigating algorithmic discrimination, we investigate the role of information in fair prediction. A common strategy for decision-making uses a predictor to assign individuals a risk score; then, individuals are selected or rejected on the basis of this score. In this work, we formalize a framework for measuring the information content of predictors. Central to this framework is the notion of a refinement; intuitively, a refinement of a predictor $z$ increases the overall informativeness of the predictions without losing the information already contained in $z$. We show that increasing information content through refinements improves the downstream selection rules across a wide range of fairness measures (e.g. true positive rates, false positive rates, selection rates). In turn, refinements provide a simple but effective tool for reducing disparity in treatment and impact without sacrificing the utility of the predictions. Our results suggest that in many applications, the perceived "cost of fairness" results from an information disparity across populations, and thus, may be avoided with improved information.
Extractor-Based Time-Space Lower Bounds for Learning
Aug 08, 2017A matrix $M: A \times X \rightarrow \{-1,1\}$ corresponds to the following learning problem: An unknown element $x \in X$ is chosen uniformly at random. A learner tries to learn $x$ from a stream of samples, $(a_1, b_1), (a_2, b_2) \ldots$, where for every $i$, $a_i \in A$ is chosen uniformly at random and $b_i = M(a_i,x)$. Assume that $k,\ell, r$ are such that any submatrix of $M$ of at least $2^{-k} \cdot |A|$ rows and at least $2^{-\ell} \cdot |X|$ columns, has a bias of at most $2^{-r}$. We show that any learning algorithm for the learning problem corresponding to $M$ requires either a memory of size at least $\Omega\left(k \cdot \ell \right)$, or at least $2^{\Omega(r)}$ samples. The result holds even if the learner has an exponentially small success probability (of $2^{-\Omega(r)}$). In particular, this shows that for a large class of learning problems, any learning algorithm requires either a memory of size at least $\Omega\left((\log |X|) \cdot (\log |A|)\right)$ or an exponential number of samples, achieving a tight $\Omega\left((\log |X|) \cdot (\log |A|)\right)$ lower bound on the size of the memory, rather than a bound of $\Omega\left(\min\left\{(\log |X|)^2,(\log |A|)^2\right\}\right)$ obtained in previous works [R17,MM17b]. Moreover, our result implies all previous memory-samples lower bounds, as well as a number of new applications. Our proof builds on [R17] that gave a general technique for proving memory-samples lower bounds.