 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking and Improving Information in the Service of Fairness
Paper and Code
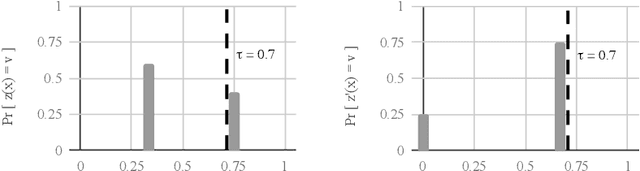
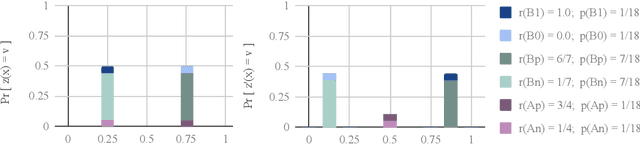
As algorithmic prediction systems have become widespread, fears that these systems may inadvertently discriminate against members of underrepresented populations have grown. With the goal of understanding fundamental principles that underpin the growing number of approaches to mitigating algorithmic discrimination, we investigate the role of information in fair prediction. A common strategy for decision-making uses a predictor to assign individuals a risk score; then, individuals are selected or rejected on the basis of this score. In this work, we formalize a framework for measuring the information content of predictors. Central to this framework is the notion of a refinement; intuitively, a refinement of a predictor $z$ increases the overall informativeness of the predictions without losing the information already contained in $z$. We show that increasing information content through refinements improves the downstream selection rules across a wide range of fairness measures (e.g. true positive rates, false positive rates, selection rates). In turn, refinements provide a simple but effective tool for reducing disparity in treatment and impact without sacrificing the utility of the predictions. Our results suggest that in many applications, the perceived "cost of fairness" results from an information disparity across populations, and thus, may be avoided with improved information.