 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Online and Private Learnability under Distributional Constraints via Generalized Smoothness
Feb 24, 2026Understanding minimal assumptions that enable learning and generalization is perhaps the central question of learning theory. Several celebrated results in statistical learning theory, such as the VC theorem and Littlestone's characterization of online learnability, establish conditions on the hypothesis class that allow for learning under independent data and adversarial data, respectively. Building upon recent work bridging these extremes, we study sequential decision making under distributional adversaries that can adaptively choose data-generating distributions from a fixed family $U$ and ask when such problems are learnable with sample complexity that behaves like the favorable independent case. We provide a near complete characterization of families $U$ that admit learnability in terms of a notion known as generalized smoothness i.e. a distribution family admits VC-dimension-dependent regret bounds for every finite-VC hypothesis class if and only if it is generalized smooth. Further, we give universal algorithms that achieve low regret under any generalized smooth adversary without explicit knowledge of $U$. Finally, when $U$ is known, we provide refined bounds in terms of a combinatorial parameter, the fragmentation number, that captures how many disjoint regions can carry nontrivial mass under $U$. These results provide a nearly complete understanding of learnability under distributional adversaries. In addition, building upon the surprising connection between online learning and differential privacy, we show that the generalized smoothness also characterizes private learnability under distributional constraints.
Is Multi-Distribution Learning as Easy as PAC Learning: Sharp Rates with Bounded Label Noise
Feb 24, 2026Towards understanding the statistical complexity of learning from heterogeneous sources, we study the problem of multi-distribution learning. Given $k$ data sources, the goal is to output a classifier for each source by exploiting shared structure to reduce sample complexity. We focus on the bounded label noise setting to determine whether the fast $1/ε$ rates achievable in single-task learning extend to this regime with minimal dependence on $k$. Surprisingly, we show that this is not the case. We demonstrate that learning across $k$ distributions inherently incurs slow rates scaling with $k/ε^2$, even under constant noise levels, unless each distribution is learned separately. A key technical contribution is a structured hypothesis-testing framework that captures the statistical cost of certifying near-optimality under bounded noise-a cost we show is unavoidable in the multi-distribution setting. Finally, we prove that when competing with the stronger benchmark of each distribution's optimal Bayes error, the sample complexity incurs a \textit{multiplicative} penalty in $k$. This establishes a \textit{statistical} separation between random classification noise and Massart noise, highlighting a fundamental barrier unique to learning from multiple sources.
Subliminal Effects in Your Data: A General Mechanism via Log-Linearity
Feb 04, 2026Training modern large language models (LLMs) has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.
Learning with Monotone Adversarial Corruptions
Jan 05, 2026We study the extent to which standard machine learning algorithms rely on exchangeability and independence of data by introducing a monotone adversarial corruption model. In this model, an adversary, upon looking at a "clean" i.i.d. dataset, inserts additional "corrupted" points of their choice into the dataset. These added points are constrained to be monotone corruptions, in that they get labeled according to the ground-truth target function. Perhaps surprisingly, we demonstrate that in this setting, all known optimal learning algorithms for binary classification can be made to achieve suboptimal expected error on a new independent test point drawn from the same distribution as the clean dataset. On the other hand, we show that uniform convergence-based algorithms do not degrade in their guarantees. Our results showcase how optimal learning algorithms break down in the face of seemingly helpful monotone corruptions, exposing their overreliance on exchangeability.
Provably Learning from Modern Language Models via Low Logit Rank
Dec 10, 2025While modern language models and their inner workings are incredibly complex, recent work (Golowich, Liu & Shetty; 2025) has proposed a simple and potentially tractable abstraction for them through the observation that empirically, these language models all seem to have approximately low logit rank. Roughly, this means that a matrix formed by the model's log probabilities of various tokens conditioned on certain sequences of tokens is well approximated by a low rank matrix. In this paper, our focus is on understanding how this structure can be exploited algorithmically for obtaining provable learning guarantees. Since low logit rank models can encode hard-to-learn distributions such as noisy parities, we study a query learning model with logit queries that reflects the access model for common APIs. Our main result is an efficient algorithm for learning any approximately low logit rank model from queries. We emphasize that our structural assumption closely reflects the behavior that is empirically observed in modern language models. Thus, our result gives what we believe is the first end-to-end learning guarantee for a generative model that plausibly captures modern language models.
The Space Complexity of Learning-Unlearning Algorithms
Jun 16, 2025We study the memory complexity of machine unlearning algorithms that provide strong data deletion guarantees to the users. Formally, consider an algorithm for a particular learning task that initially receives a training dataset. Then, after learning, it receives data deletion requests from a subset of users (of arbitrary size), and the goal of unlearning is to perform the task as if the learner never received the data of deleted users. In this paper, we ask how many bits of storage are needed to be able to delete certain training samples at a later time. We focus on the task of realizability testing, where the goal is to check whether the remaining training samples are realizable within a given hypothesis class \(\mathcal{H}\). Toward that end, we first provide a negative result showing that the VC dimension is not a characterization of the space complexity of unlearning. In particular, we provide a hypothesis class with constant VC dimension (and Littlestone dimension), but for which any unlearning algorithm for realizability testing needs to store \(\Omega(n)\)-bits, where \(n\) denotes the size of the initial training dataset. In fact, we provide a stronger separation by showing that for any hypothesis class \(\mathcal{H}\), the amount of information that the learner needs to store, so as to perform unlearning later, is lower bounded by the \textit{eluder dimension} of \(\mathcal{H}\), a combinatorial notion always larger than the VC dimension. We complement the lower bound with an upper bound in terms of the star number of the underlying hypothesis class, albeit in a stronger ticketed-memory model proposed by Ghazi et al. (2023). Since the star number for a hypothesis class is never larger than its Eluder dimension, our work highlights a fundamental separation between central and ticketed memory models for machine unlearning.
Beyond Worst-Case Online Classification: VC-Based Regret Bounds for Relaxed Benchmarks
Apr 14, 2025We revisit online binary classification by shifting the focus from competing with the best-in-class binary loss to competing against relaxed benchmarks that capture smoothed notions of optimality. Instead of measuring regret relative to the exact minimal binary error -- a standard approach that leads to worst-case bounds tied to the Littlestone dimension -- we consider comparing with predictors that are robust to small input perturbations, perform well under Gaussian smoothing, or maintain a prescribed output margin. Previous examples of this were primarily limited to the hinge loss. Our algorithms achieve regret guarantees that depend only on the VC dimension and the complexity of the instance space (e.g., metric entropy), and notably, they incur only an $O(\log(1/\gamma))$ dependence on the generalized margin $\gamma$. This stands in contrast to most existing regret bounds, which typically exhibit a polynomial dependence on $1/\gamma$. We complement this with matching lower bounds. Our analysis connects recent ideas from adversarial robustness and smoothed online learning.
Low-Rank Thinning
Feb 17, 2025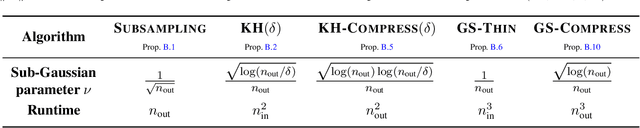

The goal in thinning is to summarize a dataset using a small set of representative points. Remarkably, sub-Gaussian thinning algorithms like Kernel Halving and Compress can match the quality of uniform subsampling while substantially reducing the number of summary points. However, existing guarantees cover only a restricted range of distributions and kernel-based quality measures and suffer from pessimistic dimension dependence. To address these deficiencies, we introduce a new low-rank analysis of sub-Gaussian thinning that applies to any distribution and any kernel, guaranteeing high-quality compression whenever the kernel or data matrix is approximately low-rank. To demonstrate the broad applicability of the techniques, we design practical sub-Gaussian thinning approaches that improve upon the best known guarantees for approximating attention in transformers, accelerating stochastic gradient training through reordering, and distinguishing distributions in near-linear time.
Tolerant Algorithms for Learning with Arbitrary Covariate Shift
Jun 04, 2024


We study the problem of learning under arbitrary distribution shift, where the learner is trained on a labeled set from one distribution but evaluated on a different, potentially adversarially generated test distribution. We focus on two frameworks: PQ learning [Goldwasser, A. Kalai, Y. Kalai, Montasser NeurIPS 2020], allowing abstention on adversarially generated parts of the test distribution, and TDS learning [Klivans, Stavropoulos, Vasilyan COLT 2024], permitting abstention on the entire test distribution if distribution shift is detected. All prior known algorithms either rely on learning primitives that are computationally hard even for simple function classes, or end up abstaining entirely even in the presence of a tiny amount of distribution shift. We address both these challenges for natural function classes, including intersections of halfspaces and decision trees, and standard training distributions, including Gaussians. For PQ learning, we give efficient learning algorithms, while for TDS learning, our algorithms can tolerate moderate amounts of distribution shift. At the core of our approach is an improved analysis of spectral outlier-removal techniques from learning with nasty noise. Our analysis can (1) handle arbitrarily large fraction of outliers, which is crucial for handling arbitrary distribution shifts, and (2) obtain stronger bounds on polynomial moments of the distribution after outlier removal, yielding new insights into polynomial regression under distribution shifts. Lastly, our techniques lead to novel results for tolerant testable learning [Rubinfeld and Vasilyan STOC 2023], and learning with nasty noise.
On the Performance of Empirical Risk Minimization with Smoothed Data
Feb 22, 2024In order to circumvent statistical and computational hardness results in sequential decision-making, recent work has considered smoothed online learning, where the distribution of data at each time is assumed to have bounded likeliehood ratio with respect to a base measure when conditioned on the history. While previous works have demonstrated the benefits of smoothness, they have either assumed that the base measure is known to the learner or have presented computationally inefficient algorithms applying only in special cases. This work investigates the more general setting where the base measure is \emph{unknown} to the learner, focusing in particular on the performance of Empirical Risk Minimization (ERM) with square loss when the data are well-specified and smooth. We show that in this setting, ERM is able to achieve sublinear error whenever a class is learnable with iid data; in particular, ERM achieves error scaling as $\tilde O( \sqrt{\mathrm{comp}(\mathcal F)\cdot T} )$, where $\mathrm{comp}(\mathcal F)$ is the statistical complexity of learning $\mathcal F$ with iid data. In so doing, we prove a novel norm comparison bound for smoothed data that comprises the first sharp norm comparison for dependent data applying to arbitrary, nonlinear function classes. We complement these results with a lower bound indicating that our analysis of ERM is essentially tight, establishing a separation in the performance of ERM between smoothed and iid data.