 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivately Learning Decision Lists and a Differentially Private Winnow
Feb 07, 2026We give new differentially private algorithms for the classic problems of learning decision lists and large-margin halfspaces in the PAC and online models. In the PAC model, we give a computationally efficient algorithm for learning decision lists with minimal sample overhead over the best non-private algorithms. In the online model, we give a private analog of the influential Winnow algorithm for learning halfspaces with mistake bound polylogarithmic in the dimension and inverse polynomial in the margin. As an application, we describe how to privately learn decision lists in the online model, qualitatively matching state-of-the art non-private guarantees.
Private PAC Learning May be Harder than Online Learning
Feb 16, 2024
We continue the study of the computational complexity of differentially private PAC learning and how it is situated within the foundations of machine learning. A recent line of work uncovered a qualitative equivalence between the private PAC model and Littlestone's mistake-bounded model of online learning, in particular, showing that any concept class of Littlestone dimension $d$ can be privately PAC learned using $\mathrm{poly}(d)$ samples. This raises the natural question of whether there might be a generic conversion from online learners to private PAC learners that also preserves computational efficiency. We give a negative answer to this question under reasonable cryptographic assumptions (roughly, those from which it is possible to build indistinguishability obfuscation for all circuits). We exhibit a concept class that admits an online learner running in polynomial time with a polynomial mistake bound, but for which there is no computationally-efficient differentially private PAC learner. Our construction and analysis strengthens and generalizes that of Bun and Zhandry (TCC 2016-A), who established such a separation between private and non-private PAC learner.
Oracle-Efficient Differentially Private Learning with Public Data
Feb 13, 2024Due to statistical lower bounds on the learnability of many function classes under privacy constraints, there has been recent interest in leveraging public data to improve the performance of private learning algorithms. In this model, algorithms must always guarantee differential privacy with respect to the private samples while also ensuring learning guarantees when the private data distribution is sufficiently close to that of the public data. Previous work has demonstrated that when sufficient public, unlabelled data is available, private learning can be made statistically tractable, but the resulting algorithms have all been computationally inefficient. In this work, we present the first computationally efficient, algorithms to provably leverage public data to learn privately whenever a function class is learnable non-privately, where our notion of computational efficiency is with respect to the number of calls to an optimization oracle for the function class. In addition to this general result, we provide specialized algorithms with improved sample complexities in the special cases when the function class is convex or when the task is binary classification.
Not All Learnable Distribution Classes are Privately Learnable
Feb 05, 2024We give an example of a class of distributions that is learnable in total variation distance with a finite number of samples, but not learnable under $(\varepsilon, \delta)$-differential privacy. This refutes a conjecture of Ashtiani.
Stability is Stable: Connections between Replicability, Privacy, and Adaptive Generalization
Mar 25, 2023


The notion of replicable algorithms was introduced in Impagliazzo et al. [STOC '22] to describe randomized algorithms that are stable under the resampling of their inputs. More precisely, a replicable algorithm gives the same output with high probability when its randomness is fixed and it is run on a new i.i.d. sample drawn from the same distribution. Using replicable algorithms for data analysis can facilitate the verification of published results by ensuring that the results of an analysis will be the same with high probability, even when that analysis is performed on a new data set. In this work, we establish new connections and separations between replicability and standard notions of algorithmic stability. In particular, we give sample-efficient algorithmic reductions between perfect generalization, approximate differential privacy, and replicability for a broad class of statistical problems. Conversely, we show any such equivalence must break down computationally: there exist statistical problems that are easy under differential privacy, but that cannot be solved replicably without breaking public-key cryptography. Furthermore, these results are tight: our reductions are statistically optimal, and we show that any computational separation between DP and replicability must imply the existence of one-way functions. Our statistical reductions give a new algorithmic framework for translating between notions of stability, which we instantiate to answer several open questions in replicability and privacy. This includes giving sample-efficient replicable algorithms for various PAC learning, distribution estimation, and distribution testing problems, algorithmic amplification of $\delta$ in approximate DP, conversions from item-level to user-level privacy, and the existence of private agnostic-to-realizable learning reductions under structured distributions.
Strong Memory Lower Bounds for Learning Natural Models
Jun 09, 2022We give lower bounds on the amount of memory required by one-pass streaming algorithms for solving several natural learning problems. In a setting where examples lie in $\{0,1\}^d$ and the optimal classifier can be encoded using $\kappa$ bits, we show that algorithms which learn using a near-minimal number of examples, $\tilde O(\kappa)$, must use $\tilde \Omega( d\kappa)$ bits of space. Our space bounds match the dimension of the ambient space of the problem's natural parametrization, even when it is quadratic in the size of examples and the final classifier. For instance, in the setting of $d$-sparse linear classifiers over degree-2 polynomial features, for which $\kappa=\Theta(d\log d)$, our space lower bound is $\tilde\Omega(d^2)$. Our bounds degrade gracefully with the stream length $N$, generally having the form $\tilde\Omega\left(d\kappa \cdot \frac{\kappa}{N}\right)$. Bounds of the form $\Omega(d\kappa)$ were known for learning parity and other problems defined over finite fields. Bounds that apply in a narrow range of sample sizes are also known for linear regression. Ours are the first such bounds for problems of the type commonly seen in recent learning applications that apply for a large range of input sizes.
Multiclass versus Binary Differentially Private PAC Learning
Jul 22, 2021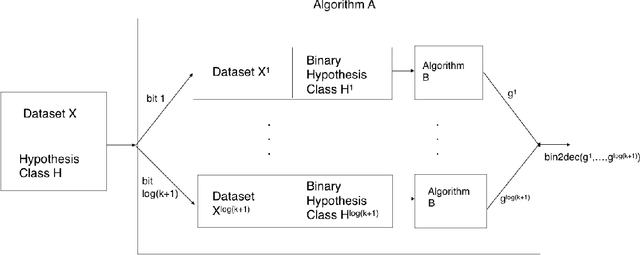
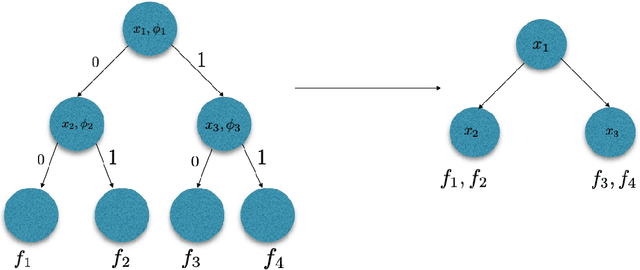
We show a generic reduction from multiclass differentially private PAC learning to binary private PAC learning. We apply this transformation to a recently proposed binary private PAC learner to obtain a private multiclass learner with sample complexity that has a polynomial dependence on the multiclass Littlestone dimension and a poly-logarithmic dependence on the number of classes. This yields an exponential improvement in the dependence on both parameters over learners from previous work. Our proof extends the notion of $\Psi$-dimension defined in work of Ben-David et al. [JCSS '95] to the online setting and explores its general properties.
Differentially Private Correlation Clustering
Feb 17, 2021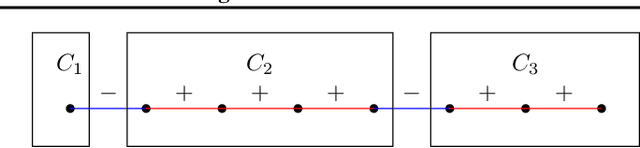
Correlation clustering is a widely used technique in unsupervised machine learning. Motivated by applications where individual privacy is a concern, we initiate the study of differentially private correlation clustering. We propose an algorithm that achieves subquadratic additive error compared to the optimal cost. In contrast, straightforward adaptations of existing non-private algorithms all lead to a trivial quadratic error. Finally, we give a lower bound showing that any pure differentially private algorithm for correlation clustering requires additive error of $\Omega(n)$.
When is Memorization of Irrelevant Training Data Necessary for High-Accuracy Learning?
Dec 11, 2020
Modern machine learning models are complex and frequently encode surprising amounts of information about individual inputs. In extreme cases, complex models appear to memorize entire input examples, including seemingly irrelevant information (social security numbers from text, for example). In this paper, we aim to understand whether this sort of memorization is necessary for accurate learning. We describe natural prediction problems in which every sufficiently accurate training algorithm must encode, in the prediction model, essentially all the information about a large subset of its training examples. This remains true even when the examples are high-dimensional and have entropy much higher than the sample size, and even when most of that information is ultimately irrelevant to the task at hand. Further, our results do not depend on the training algorithm or the class of models used for learning. Our problems are simple and fairly natural variants of the next-symbol prediction and the cluster labeling tasks. These tasks can be seen as abstractions of image- and text-related prediction problems. To establish our results, we reduce from a family of one-way communication problems for which we prove new information complexity lower bounds.
Controlling Privacy Loss in Survey Sampling (Working Paper)
Jul 24, 2020

Social science and economics research is often based on data collected in surveys. Due to time and budgetary constraints, this data is often collected using complex sampling schemes designed to increase accuracy while reducing the costs of data collection. A commonly held belief is that the sampling process affords the data subjects some additional privacy. This intuition has been formalized in the differential privacy literature for simple random sampling: a differentially private mechanism run on a simple random subsample of a population provides higher privacy guarantees than when run on the entire population. In this work we initiate the study of the privacy implications of more complicated sampling schemes including cluster sampling and stratified sampling. We find that not only do these schemes often not amplify privacy, but that they can result in privacy degradation.