 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Augmented Algorithms for MTS with Bandit Access to Multiple Predictors
Jun 05, 2025We consider the following problem: We are given $\ell$ heuristics for Metrical Task Systems (MTS), where each might be tailored to a different type of input instances. While processing an input instance received online, we are allowed to query the action of only one of the heuristics at each time step. Our goal is to achieve performance comparable to the best of the given heuristics. The main difficulty of our setting comes from the fact that the cost paid by a heuristic at time $t$ cannot be estimated unless the same heuristic was also queried at time $t-1$. This is related to Bandit Learning against memory bounded adversaries (Arora et al., 2012). We show how to achieve regret of $O(\text{OPT}^{2/3})$ and prove a tight lower bound based on the construction of Dekel et al. (2013).
Approximation Algorithms for Combinatorial Optimization with Predictions
Nov 25, 2024

We initiate a systematic study of utilizing predictions to improve over approximation guarantees of classic algorithms, without increasing the running time. We propose a systematic method for a wide class of optimization problems that ask to select a feasible subset of input items of minimal (or maximal) total weight. This gives simple (near-)linear time algorithms for, e.g., Vertex Cover, Steiner Tree, Min-Weight Perfect Matching, Knapsack, and Clique. Our algorithms produce optimal solutions when provided with perfect predictions and their approximation ratios smoothly degrade with increasing prediction error. With small enough prediction error we achieve approximation guarantees that are beyond reach without predictions in the given time bounds, as exemplified by the NP-hardness and APX-hardness of many of the above problems. Although we show our approach to be optimal for this class of problems as a whole, there is a potential for exploiting specific structural properties of individual problems to obtain improved bounds; we demonstrate this on the Steiner Tree problem. We conclude with an empirical evaluation of our approach.
Mixing predictions for online metric algorithms
Apr 04, 2023A major technique in learning-augmented online algorithms is combining multiple algorithms or predictors. Since the performance of each predictor may vary over time, it is desirable to use not the single best predictor as a benchmark, but rather a dynamic combination which follows different predictors at different times. We design algorithms that combine predictions and are competitive against such dynamic combinations for a wide class of online problems, namely, metrical task systems. Against the best (in hindsight) unconstrained combination of $\ell$ predictors, we obtain a competitive ratio of $O(\ell^2)$, and show that this is best possible. However, for a benchmark with slightly constrained number of switches between different predictors, we can get a $(1+\epsilon)$-competitive algorithm. Moreover, our algorithms can be adapted to access predictors in a bandit-like fashion, querying only one predictor at a time. An unexpected implication of one of our lower bounds is a new structural insight about covering formulations for the $k$-server problem.
Paging with Succinct Predictions
Oct 06, 2022Paging is a prototypical problem in the area of online algorithms. It has also played a central role in the development of learning-augmented algorithms -- a recent line of research that aims to ameliorate the shortcomings of classical worst-case analysis by giving algorithms access to predictions. Such predictions can typically be generated using a machine learning approach, but they are inherently imperfect. Previous work on learning-augmented paging has investigated predictions on (i) when the current page will be requested again (reoccurrence predictions), (ii) the current state of the cache in an optimal algorithm (state predictions), (iii) all requests until the current page gets requested again, and (iv) the relative order in which pages are requested. We study learning-augmented paging from the new perspective of requiring the least possible amount of predicted information. More specifically, the predictions obtained alongside each page request are limited to one bit only. We consider two natural such setups: (i) discard predictions, in which the predicted bit denotes whether or not it is ``safe'' to evict this page, and (ii) phase predictions, where the bit denotes whether the current page will be requested in the next phase (for an appropriate partitioning of the input into phases). We develop algorithms for each of the two setups that satisfy all three desirable properties of learning-augmented algorithms -- that is, they are consistent, robust and smooth -- despite being limited to a one-bit prediction per request. We also present lower bounds establishing that our algorithms are essentially best possible.
Learning-Augmented Dynamic Power Management with Multiple States via New Ski Rental Bounds
Oct 25, 2021


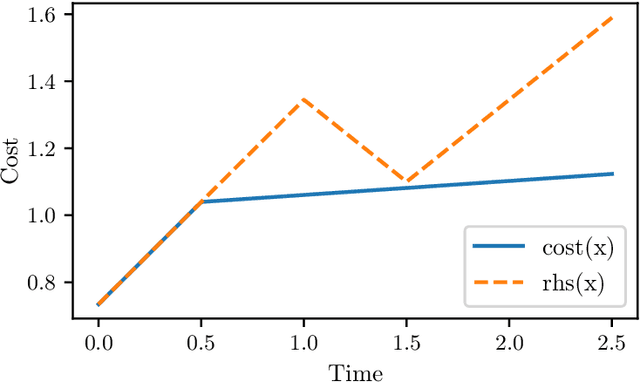
We study the online problem of minimizing power consumption in systems with multiple power-saving states. During idle periods of unknown lengths, an algorithm has to choose between power-saving states of different energy consumption and wake-up costs. We develop a learning-augmented online algorithm that makes decisions based on (potentially inaccurate) predicted lengths of the idle periods. The algorithm's performance is near-optimal when predictions are accurate and degrades gracefully with increasing prediction error, with a worst-case guarantee almost identical to the optimal classical online algorithm for the problem. A key ingredient in our approach is a new algorithm for the online ski rental problem in the learning augmented setting with tight dependence on the prediction error. We support our theoretical findings with experiments.
Differentially Private Correlation Clustering
Feb 17, 2021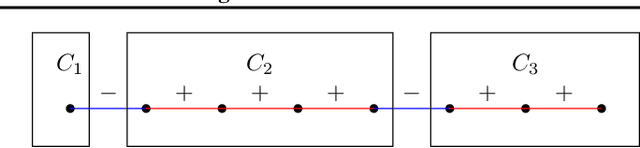
Correlation clustering is a widely used technique in unsupervised machine learning. Motivated by applications where individual privacy is a concern, we initiate the study of differentially private correlation clustering. We propose an algorithm that achieves subquadratic additive error compared to the optimal cost. In contrast, straightforward adaptations of existing non-private algorithms all lead to a trivial quadratic error. Finally, we give a lower bound showing that any pure differentially private algorithm for correlation clustering requires additive error of $\Omega(n)$.