 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContract Scheduling with Distributional and Multiple Advice
Apr 18, 2024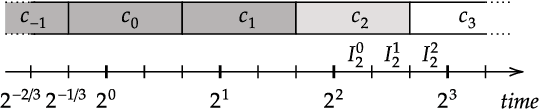


Contract scheduling is a widely studied framework for designing real-time systems with interruptible capabilities. Previous work has showed that a prediction on the interruption time can help improve the performance of contract-based systems, however it has relied on a single prediction that is provided by a deterministic oracle. In this work, we introduce and study more general and realistic learning-augmented settings in which the prediction is in the form of a probability distribution, or it is given as a set of multiple possible interruption times. For both prediction settings, we design and analyze schedules which perform optimally if the prediction is accurate, while simultaneously guaranteeing the best worst-case performance if the prediction is adversarial. We also provide evidence that the resulting system is robust to prediction errors in the distributional setting. Last, we present an experimental evaluation that confirms the theoretical findings, and illustrates the performance improvements that can be attained in practice.
Mixing predictions for online metric algorithms
Apr 04, 2023A major technique in learning-augmented online algorithms is combining multiple algorithms or predictors. Since the performance of each predictor may vary over time, it is desirable to use not the single best predictor as a benchmark, but rather a dynamic combination which follows different predictors at different times. We design algorithms that combine predictions and are competitive against such dynamic combinations for a wide class of online problems, namely, metrical task systems. Against the best (in hindsight) unconstrained combination of $\ell$ predictors, we obtain a competitive ratio of $O(\ell^2)$, and show that this is best possible. However, for a benchmark with slightly constrained number of switches between different predictors, we can get a $(1+\epsilon)$-competitive algorithm. Moreover, our algorithms can be adapted to access predictors in a bandit-like fashion, querying only one predictor at a time. An unexpected implication of one of our lower bounds is a new structural insight about covering formulations for the $k$-server problem.
Paging with Succinct Predictions
Oct 06, 2022Paging is a prototypical problem in the area of online algorithms. It has also played a central role in the development of learning-augmented algorithms -- a recent line of research that aims to ameliorate the shortcomings of classical worst-case analysis by giving algorithms access to predictions. Such predictions can typically be generated using a machine learning approach, but they are inherently imperfect. Previous work on learning-augmented paging has investigated predictions on (i) when the current page will be requested again (reoccurrence predictions), (ii) the current state of the cache in an optimal algorithm (state predictions), (iii) all requests until the current page gets requested again, and (iv) the relative order in which pages are requested. We study learning-augmented paging from the new perspective of requiring the least possible amount of predicted information. More specifically, the predictions obtained alongside each page request are limited to one bit only. We consider two natural such setups: (i) discard predictions, in which the predicted bit denotes whether or not it is ``safe'' to evict this page, and (ii) phase predictions, where the bit denotes whether the current page will be requested in the next phase (for an appropriate partitioning of the input into phases). We develop algorithms for each of the two setups that satisfy all three desirable properties of learning-augmented algorithms -- that is, they are consistent, robust and smooth -- despite being limited to a one-bit prediction per request. We also present lower bounds establishing that our algorithms are essentially best possible.
Learning-Augmented Dynamic Power Management with Multiple States via New Ski Rental Bounds
Oct 25, 2021


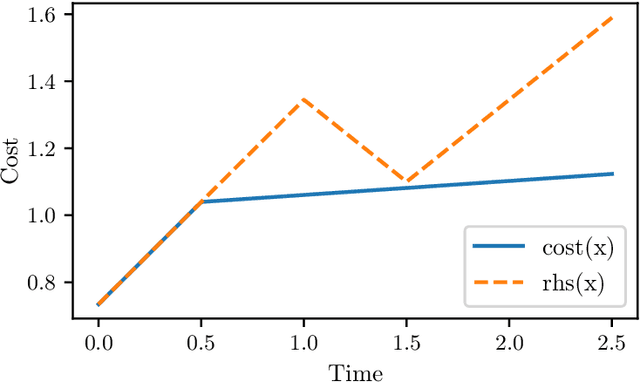
We study the online problem of minimizing power consumption in systems with multiple power-saving states. During idle periods of unknown lengths, an algorithm has to choose between power-saving states of different energy consumption and wake-up costs. We develop a learning-augmented online algorithm that makes decisions based on (potentially inaccurate) predicted lengths of the idle periods. The algorithm's performance is near-optimal when predictions are accurate and degrades gracefully with increasing prediction error, with a worst-case guarantee almost identical to the optimal classical online algorithm for the problem. A key ingredient in our approach is a new algorithm for the online ski rental problem in the learning augmented setting with tight dependence on the prediction error. We support our theoretical findings with experiments.
Double Coverage with Machine-Learned Advice
Mar 02, 2021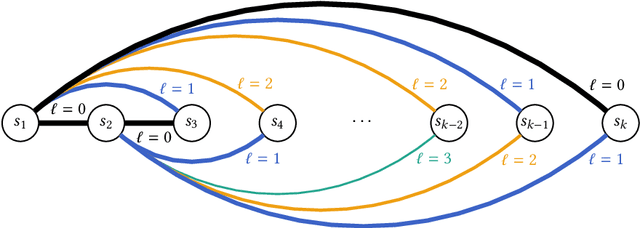
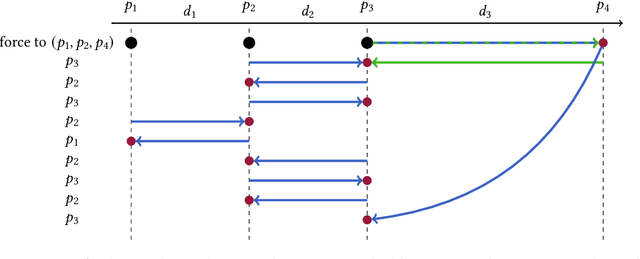
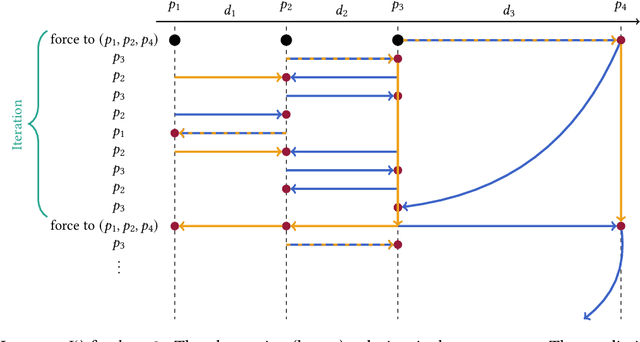
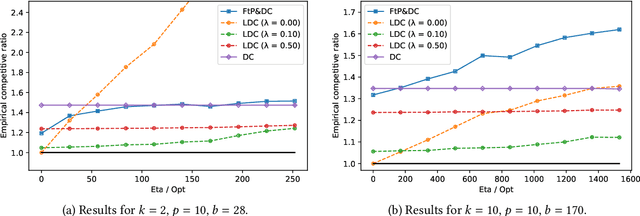
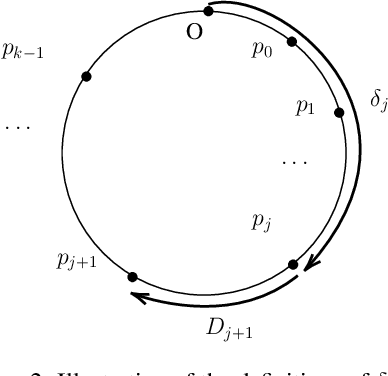
We study the fundamental online $k$-server problem in a learning-augmented setting. While in the traditional online model, an algorithm has no information about the request sequence, we assume that there is given some advice (e.g. machine-learned predictions) on an algorithm's decision. There is, however, no guarantee on the quality of the prediction and it might be far from being correct. Our main result is a learning-augmented variation of the well-known Double Coverage algorithm for k-server on the line (Chrobak et al., SIDMA 1991) in which we integrate predictions as well as our trust into their quality. We give an error-dependent competitive ratio, which is a function of a user-defined trustiness parameter, and which interpolates smoothly between an optimal consistency, the performance in case that all predictions are correct, and the best-possible robustness regardless of the prediction quality. When given good predictions, we improve upon known lower bounds for online algorithms without advice. We further show that our algorithm achieves for any k an almost optimal consistency-robustness tradeoff, within a class of deterministic algorithms respecting local and memoryless properties. Our algorithm outperforms a previously proposed (more general) learning-augmented algorithm. It is remarkable that the previous algorithm heavily exploits memory, whereas our algorithm is memoryless. Finally, we demonstrate in experiments the practicability and the superior performance of our algorithm on real-world data.