 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKleene algebra with commutativity conditions is undecidable
Nov 24, 2024We prove that the equational theory of Kleene algebra with commutativity conditions on primitives (or atomic terms) is undecidable, thereby settling a longstanding open question in the theory of Kleene algebra. While this question has also been recently solved independently by Kuznetsov, our results hold even for weaker theories that do not support the induction axioms of Kleene algebra.
Stability is Stable: Connections between Replicability, Privacy, and Adaptive Generalization
Mar 25, 2023


The notion of replicable algorithms was introduced in Impagliazzo et al. [STOC '22] to describe randomized algorithms that are stable under the resampling of their inputs. More precisely, a replicable algorithm gives the same output with high probability when its randomness is fixed and it is run on a new i.i.d. sample drawn from the same distribution. Using replicable algorithms for data analysis can facilitate the verification of published results by ensuring that the results of an analysis will be the same with high probability, even when that analysis is performed on a new data set. In this work, we establish new connections and separations between replicability and standard notions of algorithmic stability. In particular, we give sample-efficient algorithmic reductions between perfect generalization, approximate differential privacy, and replicability for a broad class of statistical problems. Conversely, we show any such equivalence must break down computationally: there exist statistical problems that are easy under differential privacy, but that cannot be solved replicably without breaking public-key cryptography. Furthermore, these results are tight: our reductions are statistically optimal, and we show that any computational separation between DP and replicability must imply the existence of one-way functions. Our statistical reductions give a new algorithmic framework for translating between notions of stability, which we instantiate to answer several open questions in replicability and privacy. This includes giving sample-efficient replicable algorithms for various PAC learning, distribution estimation, and distribution testing problems, algorithmic amplification of $\delta$ in approximate DP, conversions from item-level to user-level privacy, and the existence of private agnostic-to-realizable learning reductions under structured distributions.
On Incorrectness Logic and Kleene Algebra With Top and Tests
Aug 17, 2021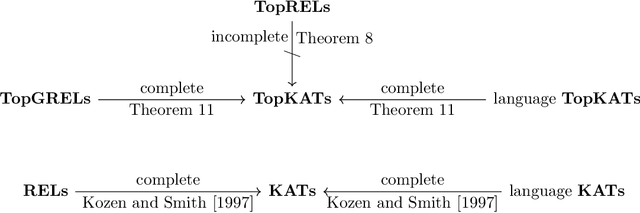
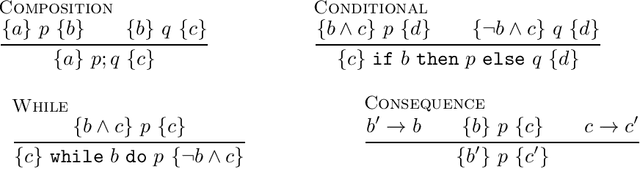


Kleene algebra with tests (KAT) is a foundational equational framework for reasoning about programs, which has found applications in program transformations, networking and compiler optimizations, among many other areas. In his seminal work, Kozen proved that KAT subsumes propositional Hoare logic, showing that one can reason about the (partial) correctness of while programs by means of the equational theory of KAT. In this work, we investigate the support that KAT provides for reasoning about \emph{incorrectness}, instead, as embodied by Ohearn's recently proposed incorrectness logic. We show that KAT cannot directly express incorrectness logic. The main reason for this limitation can be traced to the fact that KAT cannot express explicitly the notion of codomain, which is essential to express incorrectness triples. To address this issue, we study Kleene algebra with Top and Tests (TopKAT), an extension of KAT with a top element. We show that TopKAT is powerful enough to express a codomain operation, to express incorrectness triples, and to prove all the rules of incorrectness logic sound. This shows that one can reason about the incorrectness of while-like programs by means of the equational theory of TopKAT.
Multiclass versus Binary Differentially Private PAC Learning
Jul 22, 2021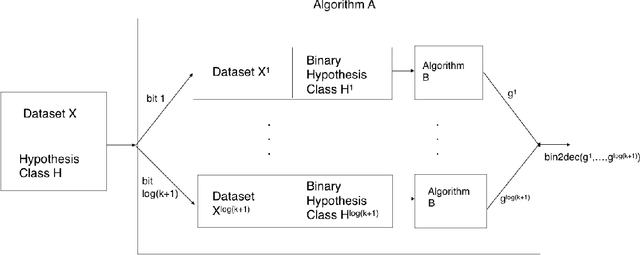
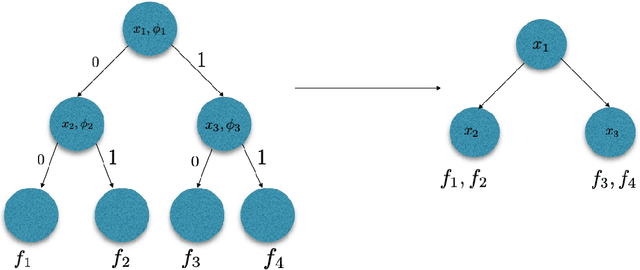
We show a generic reduction from multiclass differentially private PAC learning to binary private PAC learning. We apply this transformation to a recently proposed binary private PAC learner to obtain a private multiclass learner with sample complexity that has a polynomial dependence on the multiclass Littlestone dimension and a poly-logarithmic dependence on the number of classes. This yields an exponential improvement in the dependence on both parameters over learners from previous work. Our proof extends the notion of $\Psi$-dimension defined in work of Ben-David et al. [JCSS '95] to the online setting and explores its general properties.
Covariance-Aware Private Mean Estimation Without Private Covariance Estimation
Jul 22, 2021We present two sample-efficient differentially private mean estimators for $d$-dimensional (sub)Gaussian distributions with unknown covariance. Informally, given $n \gtrsim d/\alpha^2$ samples from such a distribution with mean $\mu$ and covariance $\Sigma$, our estimators output $\tilde\mu$ such that $\| \tilde\mu - \mu \|_{\Sigma} \leq \alpha$, where $\| \cdot \|_{\Sigma}$ is the Mahalanobis distance. All previous estimators with the same guarantee either require strong a priori bounds on the covariance matrix or require $\Omega(d^{3/2})$ samples. Each of our estimators is based on a simple, general approach to designing differentially private mechanisms, but with novel technical steps to make the estimator private and sample-efficient. Our first estimator samples a point with approximately maximum Tukey depth using the exponential mechanism, but restricted to the set of points of large Tukey depth. Proving that this mechanism is private requires a novel analysis. Our second estimator perturbs the empirical mean of the data set with noise calibrated to the empirical covariance, without releasing the covariance itself. Its sample complexity guarantees hold more generally for subgaussian distributions, albeit with a slightly worse dependence on the privacy parameter. For both estimators, careful preprocessing of the data is required to satisfy differential privacy.
Empirical Risk Minimization in the Non-interactive Local Model of Differential Privacy
Nov 11, 2020
In this paper, we study the Empirical Risk Minimization (ERM) problem in the non-interactive Local Differential Privacy (LDP) model. Previous research on this problem \citep{smith2017interaction} indicates that the sample complexity, to achieve error $\alpha$, needs to be exponentially depending on the dimensionality $p$ for general loss functions. In this paper, we make two attempts to resolve this issue by investigating conditions on the loss functions that allow us to remove such a limit. In our first attempt, we show that if the loss function is $(\infty, T)$-smooth, by using the Bernstein polynomial approximation we can avoid the exponential dependency in the term of $\alpha$. We then propose player-efficient algorithms with $1$-bit communication complexity and $O(1)$ computation cost for each player. The error bound of these algorithms is asymptotically the same as the original one. With some additional assumptions, we also give an algorithm which is more efficient for the server. In our second attempt, we show that for any $1$-Lipschitz generalized linear convex loss function, there is an $(\epsilon, \delta)$-LDP algorithm whose sample complexity for achieving error $\alpha$ is only linear in the dimensionality $p$. Our results use a polynomial of inner product approximation technique. Finally, motivated by the idea of using polynomial approximation and based on different types of polynomial approximations, we propose (efficient) non-interactive locally differentially private algorithms for learning the set of k-way marginal queries and the set of smooth queries.
Controlling Privacy Loss in Survey Sampling (Working Paper)
Jul 24, 2020

Social science and economics research is often based on data collected in surveys. Due to time and budgetary constraints, this data is often collected using complex sampling schemes designed to increase accuracy while reducing the costs of data collection. A commonly held belief is that the sampling process affords the data subjects some additional privacy. This intuition has been formalized in the differential privacy literature for simple random sampling: a differentially private mechanism run on a simple random subsample of a population provides higher privacy guarantees than when run on the entire population. In this work we initiate the study of the privacy implications of more complicated sampling schemes including cluster sampling and stratified sampling. We find that not only do these schemes often not amplify privacy, but that they can result in privacy degradation.
Facility Location Problem in Differential Privacy Model Revisited
Oct 26, 2019
In this paper we study the uncapacitated facility location problem in the model of differential privacy (DP) with uniform facility cost. Specifically, we first show that, under the hierarchically well-separated tree (HST) metrics and the super-set output setting that was introduced in Gupta et. al., there is an $\epsilon$-DP algorithm that achieves an $O(\frac{1}{\epsilon})$(expected multiplicative) approximation ratio; this implies an $O(\frac{\log n}{\epsilon})$ approximation ratio for the general metric case, where $n$ is the size of the input metric. These bounds improve the best-known results given by Gupta et. al. In particular, our approximation ratio for HST-metrics is independent of $n$, and the ratio for general metrics is independent of the aspect ratio of the input metric. On the negative side, we show that the approximation ratio of any $\epsilon$-DP algorithm is lower bounded by $\Omega(\frac{1}{\sqrt{\epsilon}})$, even for instances on HST metrics with uniform facility cost, under the super-set output setting. The lower bound shows that the dependence of the approximation ratio for HST metrics on $\epsilon$ can not be removed or greatly improved. Our novel methods and techniques for both the upper and lower bound may find additional applications.
Estimating Smooth GLM in Non-interactive Local Differential Privacy Model with Public Unlabeled Data
Oct 01, 2019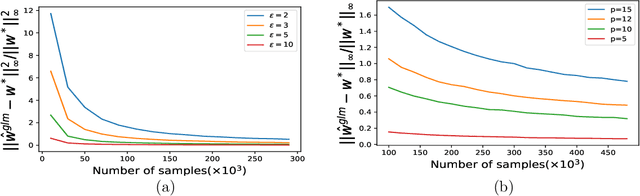
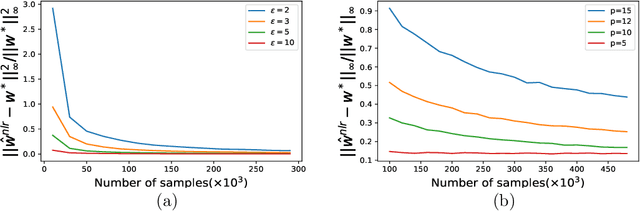
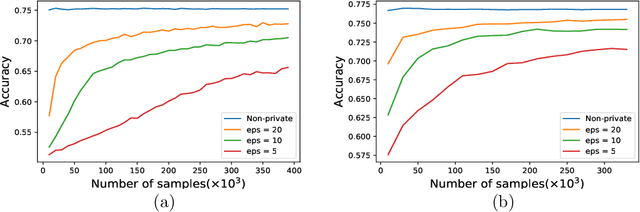
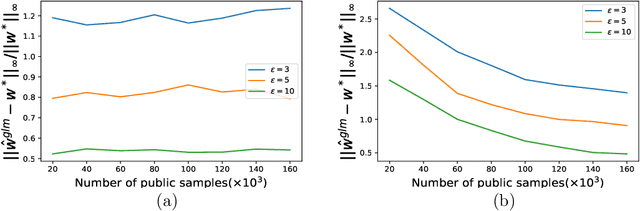
In this paper, we study the problem of estimating smooth Generalized Linear Models (GLM) in the Non-interactive Local Differential Privacy (NLDP) model. Different from its classical setting, our model allows the server to access some additional public but unlabeled data. By using Stein's lemma and its variants, we first show that there is an $(\epsilon, \delta)$-NLDP algorithm for GLM (under some mild assumptions), if each data record is i.i.d sampled from some sub-Gaussian distribution with bounded $\ell_1$-norm. Then with high probability, the sample complexity of the public and private data, for the algorithm to achieve an $\alpha$ estimation error (in $\ell_\infty$-norm), is $O(p^2\alpha^{-2})$ and ${O}(p^2\alpha^{-2}\epsilon^{-2})$, respectively, if $\alpha$ is not too small ({\em i.e.,} $\alpha\geq \Omega(\frac{1}{\sqrt{p}})$), where $p$ is the dimensionality of the data. This is a significant improvement over the previously known quasi-polynomial (in $\alpha$) or exponential (in $p$) complexity of GLM with no public data. Also, our algorithm can answer multiple (at most $\exp(O(p))$) GLM queries with the same sample complexities as in the one GLM query case with at least constant probability. We then extend our idea to the non-linear regression problem and show a similar phenomenon for it. Finally, we demonstrate the effectiveness of our algorithms through experiments on both synthetic and real world datasets. To our best knowledge, this is the first paper showing the existence of efficient and effective algorithms for GLM and non-linear regression in the NLDP model with public unlabeled data.
Privacy Amplification by Mixing and Diffusion Mechanisms
May 29, 2019
A fundamental result in differential privacy states that the privacy guarantees of a mechanism are preserved by any post-processing of its output. In this paper we investigate under what conditions stochastic post-processing can amplify the privacy of a mechanism. By interpreting post-processing as the application of a Markov operator, we first give a series of amplification results in terms of uniform mixing properties of the Markov process defined by said operator. Next we provide amplification bounds in terms of coupling arguments which can be applied in cases where uniform mixing is not available. Finally, we introduce a new family of mechanisms based on diffusion processes which are closed under post-processing, and analyze their privacy via a novel heat flow argument. As applications, we show that the rate of "privacy amplification by iteration" in Noisy SGD introduced by Feldman et al. [FOCS'18] admits an exponential improvement in the strongly convex case, and propose a simple mechanism based on the Ornstein-Uhlenbeck process which has better mean squared error than the Gaussian mechanism when releasing a bounded function of the data.