 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Accuracy for Private Continual Cardinality Estimation in Fully Dynamic Streams via Matrix Factorization
Jan 05, 2026We study differentially-private statistics in the fully dynamic continual observation model, where many updates can arrive at each time step and updates to a stream can involve both insertions and deletions of an item. Earlier work (e.g., Jain et al., NeurIPS 2023 for counting distinct elements; Raskhodnikova & Steiner, PODS 2025 for triangle counting with edge updates) reduced the respective cardinality estimation problem to continual counting on the difference stream associated with the true function values on the input stream. In such reductions, a change in the original stream can cause many changes in the difference stream, this poses a challenge for applying private continual counting algorithms to obtain optimal error bounds. We improve the accuracy of several such reductions by studying the associated $\ell_p$-sensitivity vectors of the resulting difference streams and isolating their properties. We demonstrate that our framework gives improved bounds for counting distinct elements, estimating degree histograms, and estimating triangle counts (under a slightly relaxed privacy model), thus offering a general approach to private continual cardinality estimation in streaming settings. Our improved accuracy stems from tight analysis of known factorization mechanisms for the counting matrix in this setting; the key technical challenge is arguing that one can use state-of-the-art factorizations for sensitivity vector sets with the properties we isolate. Empirically and analytically, we demonstrate that our improved error bounds offer a substantial improvement in accuracy for cardinality estimation problems over a large range of parameters.
Instance-Optimal Private Density Estimation in the Wasserstein Distance
Jun 27, 2024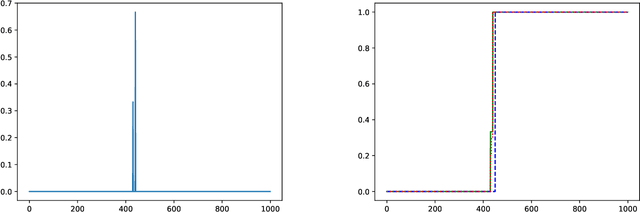
Estimating the density of a distribution from samples is a fundamental problem in statistics. In many practical settings, the Wasserstein distance is an appropriate error metric for density estimation. For example, when estimating population densities in a geographic region, a small Wasserstein distance means that the estimate is able to capture roughly where the population mass is. In this work we study differentially private density estimation in the Wasserstein distance. We design and analyze instance-optimal algorithms for this problem that can adapt to easy instances. For distributions $P$ over $\mathbb{R}$, we consider a strong notion of instance-optimality: an algorithm that uniformly achieves the instance-optimal estimation rate is competitive with an algorithm that is told that the distribution is either $P$ or $Q_P$ for some distribution $Q_P$ whose probability density function (pdf) is within a factor of 2 of the pdf of $P$. For distributions over $\mathbb{R}^2$, we use a different notion of instance optimality. We say that an algorithm is instance-optimal if it is competitive with an algorithm that is given a constant-factor multiplicative approximation of the density of the distribution. We characterize the instance-optimal estimation rates in both these settings and show that they are uniformly achievable (up to polylogarithmic factors). Our approach for $\mathbb{R}^2$ extends to arbitrary metric spaces as it goes via hierarchically separated trees. As a special case our results lead to instance-optimal private learning in TV distance for discrete distributions.
Stability is Stable: Connections between Replicability, Privacy, and Adaptive Generalization
Mar 25, 2023


The notion of replicable algorithms was introduced in Impagliazzo et al. [STOC '22] to describe randomized algorithms that are stable under the resampling of their inputs. More precisely, a replicable algorithm gives the same output with high probability when its randomness is fixed and it is run on a new i.i.d. sample drawn from the same distribution. Using replicable algorithms for data analysis can facilitate the verification of published results by ensuring that the results of an analysis will be the same with high probability, even when that analysis is performed on a new data set. In this work, we establish new connections and separations between replicability and standard notions of algorithmic stability. In particular, we give sample-efficient algorithmic reductions between perfect generalization, approximate differential privacy, and replicability for a broad class of statistical problems. Conversely, we show any such equivalence must break down computationally: there exist statistical problems that are easy under differential privacy, but that cannot be solved replicably without breaking public-key cryptography. Furthermore, these results are tight: our reductions are statistically optimal, and we show that any computational separation between DP and replicability must imply the existence of one-way functions. Our statistical reductions give a new algorithmic framework for translating between notions of stability, which we instantiate to answer several open questions in replicability and privacy. This includes giving sample-efficient replicable algorithms for various PAC learning, distribution estimation, and distribution testing problems, algorithmic amplification of $\delta$ in approximate DP, conversions from item-level to user-level privacy, and the existence of private agnostic-to-realizable learning reductions under structured distributions.
Differentially Private Sampling from Distributions
Nov 15, 2022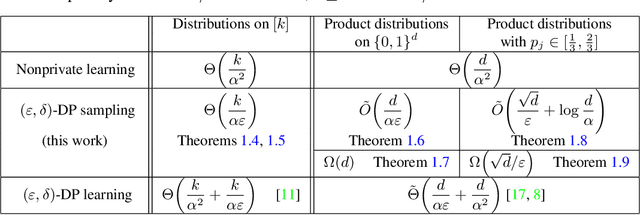
We initiate an investigation of private sampling from distributions. Given a dataset with $n$ independent observations from an unknown distribution $P$, a sampling algorithm must output a single observation from a distribution that is close in total variation distance to $P$ while satisfying differential privacy. Sampling abstracts the goal of generating small amounts of realistic-looking data. We provide tight upper and lower bounds for the dataset size needed for this task for three natural families of distributions: arbitrary distributions on $\{1,\ldots ,k\}$, arbitrary product distributions on $\{0,1\}^d$, and product distributions on $\{0,1\}^d$ with bias in each coordinate bounded away from 0 and 1. We demonstrate that, in some parameter regimes, private sampling requires asymptotically fewer observations than learning a description of $P$ nonprivately; in other regimes, however, private sampling proves to be as difficult as private learning. Notably, for some classes of distributions, the overhead in the number of observations needed for private learning compared to non-private learning is completely captured by the number of observations needed for private sampling.
Multiclass versus Binary Differentially Private PAC Learning
Jul 22, 2021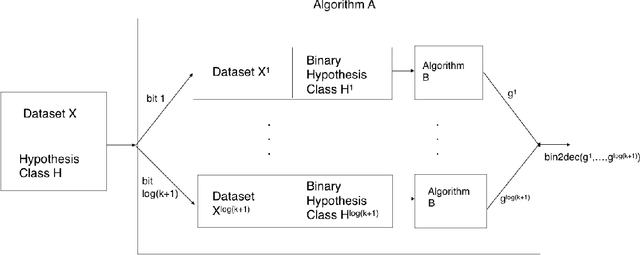
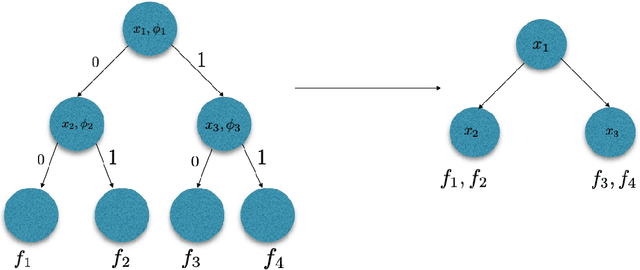
We show a generic reduction from multiclass differentially private PAC learning to binary private PAC learning. We apply this transformation to a recently proposed binary private PAC learner to obtain a private multiclass learner with sample complexity that has a polynomial dependence on the multiclass Littlestone dimension and a poly-logarithmic dependence on the number of classes. This yields an exponential improvement in the dependence on both parameters over learners from previous work. Our proof extends the notion of $\Psi$-dimension defined in work of Ben-David et al. [JCSS '95] to the online setting and explores its general properties.