 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Sampling from Distributions
Nov 15, 2022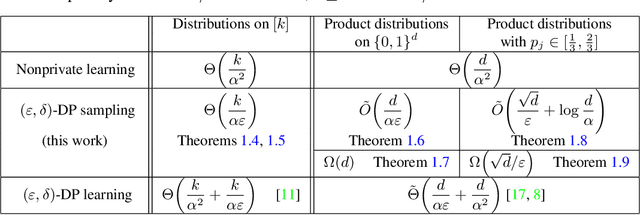
We initiate an investigation of private sampling from distributions. Given a dataset with $n$ independent observations from an unknown distribution $P$, a sampling algorithm must output a single observation from a distribution that is close in total variation distance to $P$ while satisfying differential privacy. Sampling abstracts the goal of generating small amounts of realistic-looking data. We provide tight upper and lower bounds for the dataset size needed for this task for three natural families of distributions: arbitrary distributions on $\{1,\ldots ,k\}$, arbitrary product distributions on $\{0,1\}^d$, and product distributions on $\{0,1\}^d$ with bias in each coordinate bounded away from 0 and 1. We demonstrate that, in some parameter regimes, private sampling requires asymptotically fewer observations than learning a description of $P$ nonprivately; in other regimes, however, private sampling proves to be as difficult as private learning. Notably, for some classes of distributions, the overhead in the number of observations needed for private learning compared to non-private learning is completely captured by the number of observations needed for private sampling.
Learning pseudo-Boolean k-DNF and Submodular Functions
Aug 10, 2012We prove that any submodular function f: {0,1}^n -> {0,1,...,k} can be represented as a pseudo-Boolean 2k-DNF formula. Pseudo-Boolean DNFs are a natural generalization of DNF representation for functions with integer range. Each term in such a formula has an associated integral constant. We show that an analog of Hastad's switching lemma holds for pseudo-Boolean k-DNFs if all constants associated with the terms of the formula are bounded. This allows us to generalize Mansour's PAC-learning algorithm for k-DNFs to pseudo-Boolean k-DNFs, and hence gives a PAC-learning algorithm with membership queries under the uniform distribution for submodular functions of the form f:{0,1}^n -> {0,1,...,k}. Our algorithm runs in time polynomial in n, k^{O(k \log k / \epsilon)}, 1/\epsilon and log(1/\delta) and works even in the agnostic setting. The line of previous work on learning submodular functions [Balcan, Harvey (STOC '11), Gupta, Hardt, Roth, Ullman (STOC '11), Cheraghchi, Klivans, Kothari, Lee (SODA '12)] implies only n^{O(k)} query complexity for learning submodular functions in this setting, for fixed epsilon and delta. Our learning algorithm implies a property tester for submodularity of functions f:{0,1}^n -> {0, ..., k} with query complexity polynomial in n for k=O((\log n/ \loglog n)^{1/2}) and constant proximity parameter \epsilon.
What Can We Learn Privately?
Feb 19, 2010
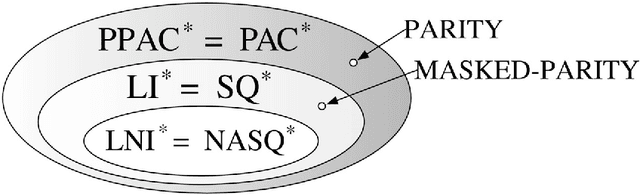
Learning problems form an important category of computational tasks that generalizes many of the computations researchers apply to large real-life data sets. We ask: what concept classes can be learned privately, namely, by an algorithm whose output does not depend too heavily on any one input or specific training example? More precisely, we investigate learning algorithms that satisfy differential privacy, a notion that provides strong confidentiality guarantees in contexts where aggregate information is released about a database containing sensitive information about individuals. We demonstrate that, ignoring computational constraints, it is possible to privately agnostically learn any concept class using a sample size approximately logarithmic in the cardinality of the concept class. Therefore, almost anything learnable is learnable privately: specifically, if a concept class is learnable by a (non-private) algorithm with polynomial sample complexity and output size, then it can be learned privately using a polynomial number of samples. We also present a computationally efficient private PAC learner for the class of parity functions. Local (or randomized response) algorithms are a practical class of private algorithms that have received extensive investigation. We provide a precise characterization of local private learning algorithms. We show that a concept class is learnable by a local algorithm if and only if it is learnable in the statistical query (SQ) model. Finally, we present a separation between the power of interactive and noninteractive local learning algorithms.
* 35 pages, 2 figures