 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quantitative Characterization of Forgetting in Post-Training
Mar 12, 2026Continual post-training of generative models is widely used, yet a principled understanding of when and why forgetting occurs remains limited. We develop theoretical results under a two-mode mixture abstraction (representing old and new tasks), proposed by Chen et al. (2025) (arXiv:2510.18874), and formalize forgetting in two forms: (i) mass forgetting, where the old mixture weight collapses to zero, and (ii) old-component drift, where an already-correct old component shifts during training. For equal-covariance Gaussian modes, we prove that forward-KL objectives trained on data from the new distribution drive the old weight to zero, while reverse-KL objectives converge to the true target (thereby avoiding mass forgetting) and perturb the old mean only through overlap-gated misassignment probabilities controlled by the Bhattacharyya coefficient, yielding drift that decays exponentially with mode separation and a locally well-conditioned geometry with exponential convergence. We further quantify how replay interacts with these objectives. For forward-KL, replay must modify the training distribution to change the population optimum; for reverse-KL, replay leaves the population objective unchanged but prevents finite-batch old-mode starvation through bounded importance weighting. Finally, we analyze three recently proposed near-on-policy post-training methods, SDFT (arxiv:2601.19897), TTT-Discover (arxiv:2601.16175), and OAPL (arxiv:2602.19362), via the same lens and derive explicit conditions under which each retains old mass and exhibits overlap-controlled drift. Overall, our results show that forgetting can by precisely quantified based on the interaction between divergence direction, geometric behavioral overlap, sampling regime, and the visibility of past behavior during training.
Dependence-Aware Label Aggregation for LLM-as-a-Judge via Ising Models
Jan 29, 2026Large-scale AI evaluation increasingly relies on aggregating binary judgments from $K$ annotators, including LLMs used as judges. Most classical methods, e.g., Dawid-Skene or (weighted) majority voting, assume annotators are conditionally independent given the true label $Y\in\{0,1\}$, an assumption often violated by LLM judges due to shared data, architectures, prompts, and failure modes. Ignoring such dependencies can yield miscalibrated posteriors and even confidently incorrect predictions. We study label aggregation through a hierarchy of dependence-aware models based on Ising graphical models and latent factors. For class-dependent Ising models, the Bayes log-odds is generally quadratic in votes; for class-independent couplings, it reduces to a linear weighted vote with correlation-adjusted parameters. We present finite-$K$ examples showing that methods based on conditional independence can flip the Bayes label despite matching per-annotator marginals. We prove separation results demonstrating that these methods remain strictly suboptimal as the number of judges grows, incurring nonvanishing excess risk under latent factors. Finally, we evaluate the proposed method on three real-world datasets, demonstrating improved performance over the classical baselines.
From Guess2Graph: When and How Can Unreliable Experts Safely Boost Causal Discovery in Finite Samples?
Oct 16, 2025Causal discovery algorithms often perform poorly with limited samples. While integrating expert knowledge (including from LLMs) as constraints promises to improve performance, guarantees for existing methods require perfect predictions or uncertainty estimates, making them unreliable for practical use. We propose the Guess2Graph (G2G) framework, which uses expert guesses to guide the sequence of statistical tests rather than replacing them. This maintains statistical consistency while enabling performance improvements. We develop two instantiations of G2G: PC-Guess, which augments the PC algorithm, and gPC-Guess, a learning-augmented variant designed to better leverage high-quality expert input. Theoretically, both preserve correctness regardless of expert error, with gPC-Guess provably outperforming its non-augmented counterpart in finite samples when experts are "better than random." Empirically, both show monotonic improvement with expert accuracy, with gPC-Guess achieving significantly stronger gains.
A Classical View on Benign Overfitting: The Role of Sample Size
May 16, 2025Benign overfitting is a phenomenon in machine learning where a model perfectly fits (interpolates) the training data, including noisy examples, yet still generalizes well to unseen data. Understanding this phenomenon has attracted considerable attention in recent years. In this work, we introduce a conceptual shift, by focusing on almost benign overfitting, where models simultaneously achieve both arbitrarily small training and test errors. This behavior is characteristic of neural networks, which often achieve low (but non-zero) training error while still generalizing well. We hypothesize that this almost benign overfitting can emerge even in classical regimes, by analyzing how the interaction between sample size and model complexity enables larger models to achieve both good training fit but still approach Bayes-optimal generalization. We substantiate this hypothesis with theoretical evidence from two case studies: (i) kernel ridge regression, and (ii) least-squares regression using a two-layer fully connected ReLU neural network trained via gradient flow. In both cases, we overcome the strong assumptions often required in prior work on benign overfitting. Our results on neural networks also provide the first generalization result in this setting that does not rely on any assumptions about the underlying regression function or noise, beyond boundedness. Our analysis introduces a novel proof technique based on decomposing the excess risk into estimation and approximation errors, interpreting gradient flow as an implicit regularizer, that helps avoid uniform convergence traps. This analysis idea could be of independent interest.
$β$-calibration of Language Model Confidence Scores for Generative QA
Oct 09, 2024


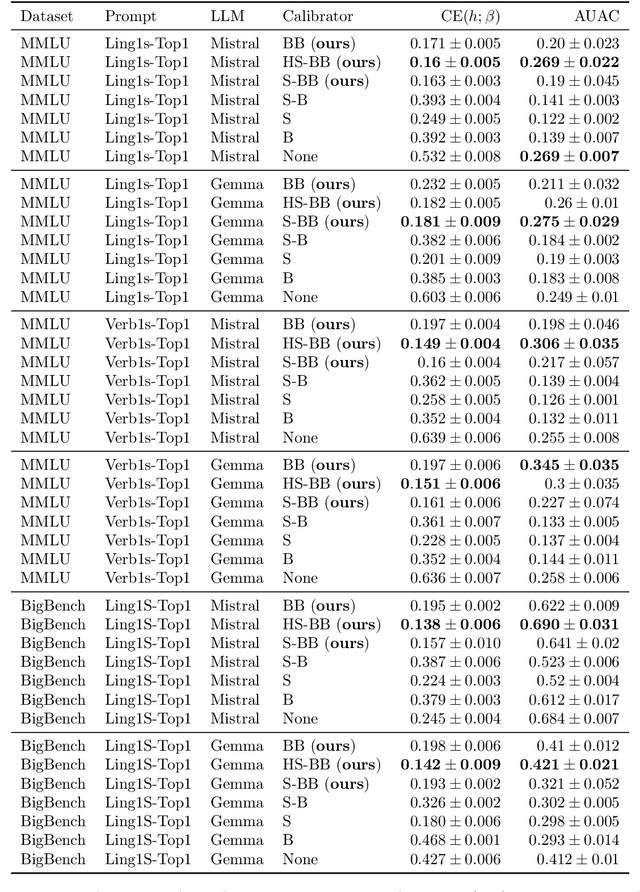
To use generative question-and-answering (QA) systems for decision-making and in any critical application, these systems need to provide well-calibrated confidence scores that reflect the correctness of their answers. Existing calibration methods aim to ensure that the confidence score is on average indicative of the likelihood that the answer is correct. We argue, however, that this standard (average-case) notion of calibration is difficult to interpret for decision-making in generative QA. To address this, we generalize the standard notion of average calibration and introduce $\beta$-calibration, which ensures calibration holds across different question-and-answer groups. We then propose discretized posthoc calibration schemes for achieving $\beta$-calibration.
Benign Overfitting for Regression with Trained Two-Layer ReLU Networks
Oct 08, 2024We study the least-square regression problem with a two-layer fully-connected neural network, with ReLU activation function, trained by gradient flow. Our first result is a generalization result, that requires no assumptions on the underlying regression function or the noise other than that they are bounded. We operate in the neural tangent kernel regime, and our generalization result is developed via a decomposition of the excess risk into estimation and approximation errors, viewing gradient flow as an implicit regularizer. This decomposition in the context of neural networks is a novel perspective of gradient descent, and helps us avoid uniform convergence traps. In this work, we also establish that under the same setting, the trained network overfits to the data. Together, these results, establishes the first result on benign overfitting for finite-width ReLU networks for arbitrary regression functions.
Differentially Private Conditional Independence Testing
Jun 11, 2023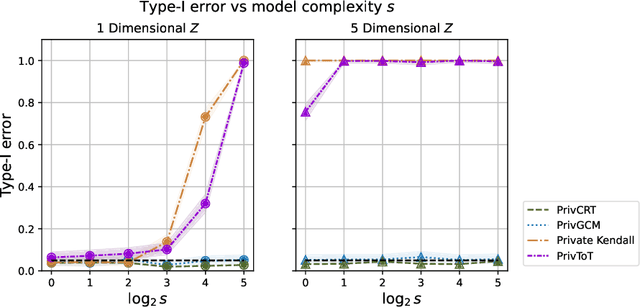
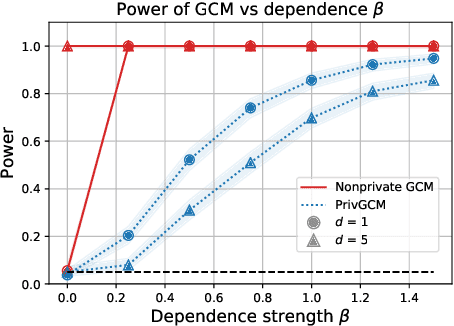
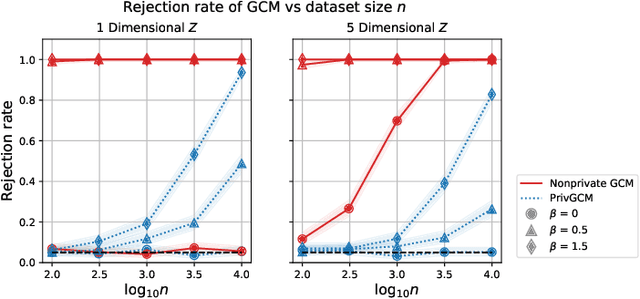
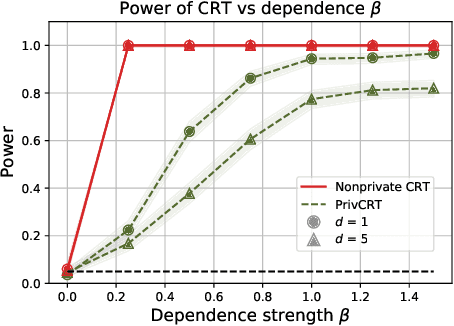
Conditional independence (CI) tests are widely used in statistical data analysis, e.g., they are the building block of many algorithms for causal graph discovery. The goal of a CI test is to accept or reject the null hypothesis that $X \perp \!\!\! \perp Y \mid Z$, where $X \in \mathbb{R}, Y \in \mathbb{R}, Z \in \mathbb{R}^d$. In this work, we investigate conditional independence testing under the constraint of differential privacy. We design two private CI testing procedures: one based on the generalized covariance measure of Shah and Peters (2020) and another based on the conditional randomization test of Cand\`es et al. (2016) (under the model-X assumption). We provide theoretical guarantees on the performance of our tests and validate them empirically. These are the first private CI tests that work for the general case when $Z$ is continuous.
Debiasing Conditional Stochastic Optimization
Apr 20, 2023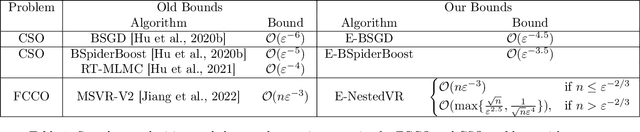
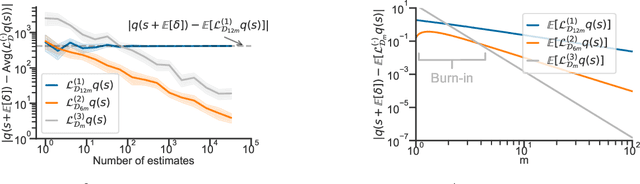
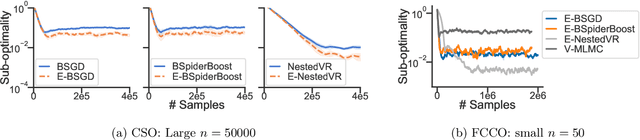
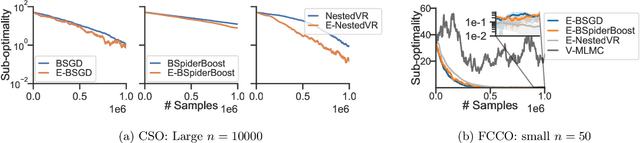
In this paper, we study the conditional stochastic optimization (CSO) problem which covers a variety of applications including portfolio selection, reinforcement learning, robust learning, causal inference, etc. The sample-averaged gradient of the CSO objective is biased due to its nested structure and therefore requires a high sample complexity to reach convergence. We introduce a general stochastic extrapolation technique that effectively reduces the bias. We show that for nonconvex smooth objectives, combining this extrapolation with variance reduction techniques can achieve a significantly better sample complexity than existing bounds. We also develop new algorithms for the finite-sum variant of CSO that also significantly improve upon existing results. Finally, we believe that our debiasing technique could be an interesting tool applicable to other stochastic optimization problems too.
Interventional and Counterfactual Inference with Diffusion Models
Feb 02, 2023



We consider the problem of answering observational, interventional, and counterfactual queries in a causally sufficient setting where only observational data and the causal graph are available. Utilizing the recent developments in diffusion models, we introduce diffusion-based causal models (DCM) to learn causal mechanisms, that generate unique latent encodings to allow for direct sampling under interventions as well as abduction for counterfactuals. We utilize DCM to model structural equations, seeing that diffusion models serve as a natural candidate here since they encode each node to a latent representation, a proxy for the exogenous noise, and offer flexible and accurate modeling to provide reliable causal statements and estimates. Our empirical evaluations demonstrate significant improvements over existing state-of-the-art methods for answering causal queries. Our theoretical results provide a methodology for analyzing the counterfactual error for general encoder/decoder models which could be of independent interest.
Thompson Sampling with Diffusion Generative Prior
Jan 12, 2023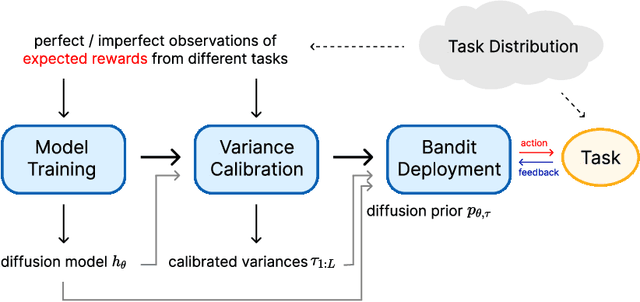
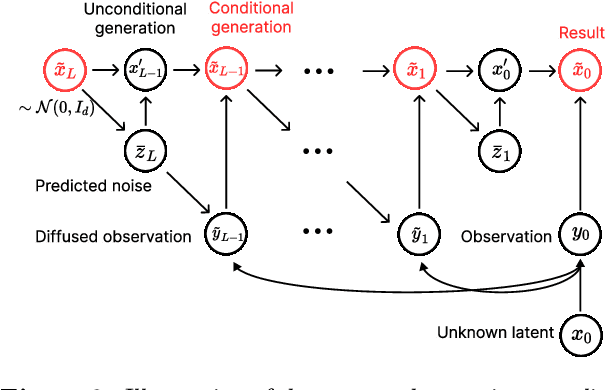
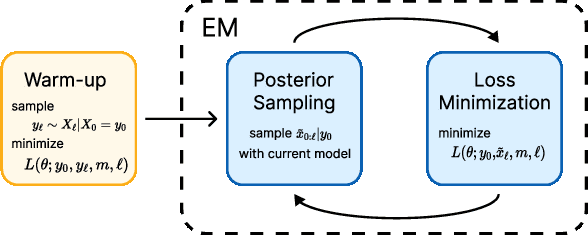
In this work, we initiate the idea of using denoising diffusion models to learn priors for online decision making problems. Our special focus is on the meta-learning for bandit framework, with the goal of learning a strategy that performs well across bandit tasks of a same class. To this end, we train a diffusion model that learns the underlying task distribution and combine Thompson sampling with the learned prior to deal with new tasks at test time. Our posterior sampling algorithm is designed to carefully balance between the learned prior and the noisy observations that come from the learner's interaction with the environment. To capture realistic bandit scenarios, we also propose a novel diffusion model training procedure that trains even from incomplete and/or noisy data, which could be of independent interest. Finally, our extensive experimental evaluations clearly demonstrate the potential of the proposed approach.