 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Modeling of Disease Transmission within Human Contact Networks
Apr 08, 2026Epidemiologic studies of infectious diseases often rely on models of contact networks to capture the complex interactions that govern disease spread, and ongoing projects aim to vastly increase the scale at which such data can be collected. However, contact networks may include sensitive information, such as sexual relationships or drug use behavior. Protecting individual privacy while maintaining the scientific usefulness of the data is crucial. We propose a privacy-preserving pipeline for disease spread simulation studies based on a sensitive network that integrates differential privacy (DP) with statistical network models such as stochastic block models (SBMs) and exponential random graph models (ERGMs). Our pipeline comprises three steps: (1) compute network summary statistics using \emph{node-level} DP (which corresponds to protecting individuals' contributions); (2) fit a statistical model, like an ERGM, using these summaries, which allows generating synthetic networks reflecting the structure of the original network; and (3) simulate disease spread on the synthetic networks using an agent-based model. We evaluate the effectiveness of our approach using a simple Susceptible-Infected-Susceptible (SIS) disease model under multiple configurations. We compare both numerical results, such as simulated disease incidence and prevalence, as well as qualitative conclusions such as intervention effect size, on networks generated with and without differential privacy constraints. Our experiments are based on egocentric sexual network data from the ARTNet study (a survey about HIV-related behaviors). Our results show that the noise added for privacy is small relative to other sources of error (sampling and model misspecification). This suggests that, in principle, curators of such sensitive data can provide valuable epidemiologic insights while protecting privacy.
Observational Auditing of Label Privacy
Nov 18, 2025Differential privacy (DP) auditing is essential for evaluating privacy guarantees in machine learning systems. Existing auditing methods, however, pose a significant challenge for large-scale systems since they require modifying the training dataset -- for instance, by injecting out-of-distribution canaries or removing samples from training. Such interventions on the training data pipeline are resource-intensive and involve considerable engineering overhead. We introduce a novel observational auditing framework that leverages the inherent randomness of data distributions, enabling privacy evaluation without altering the original dataset. Our approach extends privacy auditing beyond traditional membership inference to protected attributes, with labels as a special case, addressing a key gap in existing techniques. We provide theoretical foundations for our method and perform experiments on Criteo and CIFAR-10 datasets that demonstrate its effectiveness in auditing label privacy guarantees. This work opens new avenues for practical privacy auditing in large-scale production environments.
Differentially Private Conditional Independence Testing
Jun 11, 2023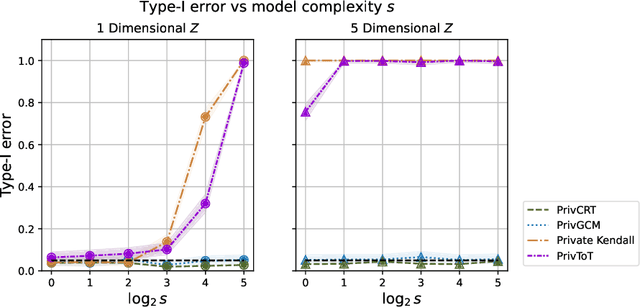
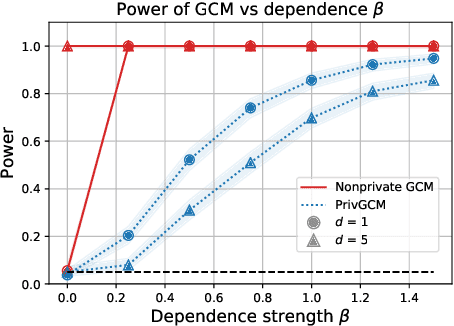
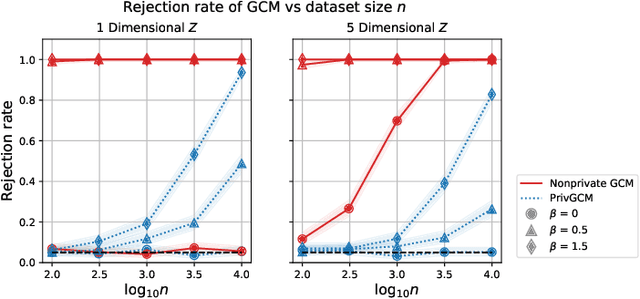
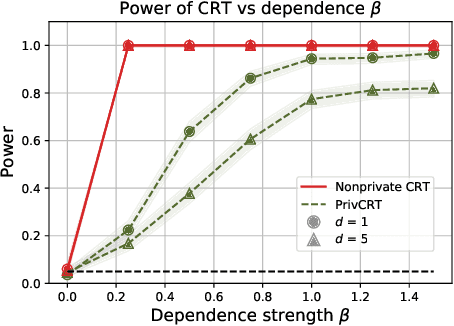
Conditional independence (CI) tests are widely used in statistical data analysis, e.g., they are the building block of many algorithms for causal graph discovery. The goal of a CI test is to accept or reject the null hypothesis that $X \perp \!\!\! \perp Y \mid Z$, where $X \in \mathbb{R}, Y \in \mathbb{R}, Z \in \mathbb{R}^d$. In this work, we investigate conditional independence testing under the constraint of differential privacy. We design two private CI testing procedures: one based on the generalized covariance measure of Shah and Peters (2020) and another based on the conditional randomization test of Cand\`es et al. (2016) (under the model-X assumption). We provide theoretical guarantees on the performance of our tests and validate them empirically. These are the first private CI tests that work for the general case when $Z$ is continuous.
Performative Prediction in a Stateful World
Nov 08, 2020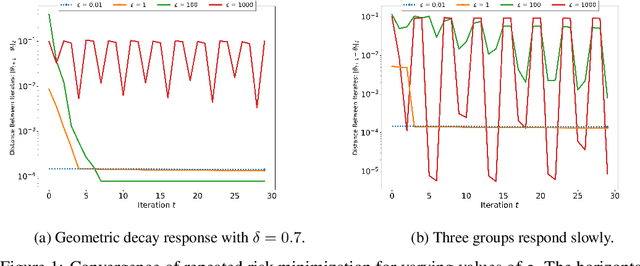
Deployed supervised machine learning models make predictions that interact with and influence the world. This phenomenon is called "performative prediction" by Perdomo et al. (2020), who investigated it in a stateless setting. We generalize their results to the case where the response of the population to the deployed classifier depends both on the classifier and the previous distribution of the population. We also demonstrate such a setting empirically, for the scenario of strategic manipulation.