 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$β$-calibration of Language Model Confidence Scores for Generative QA
Oct 09, 2024


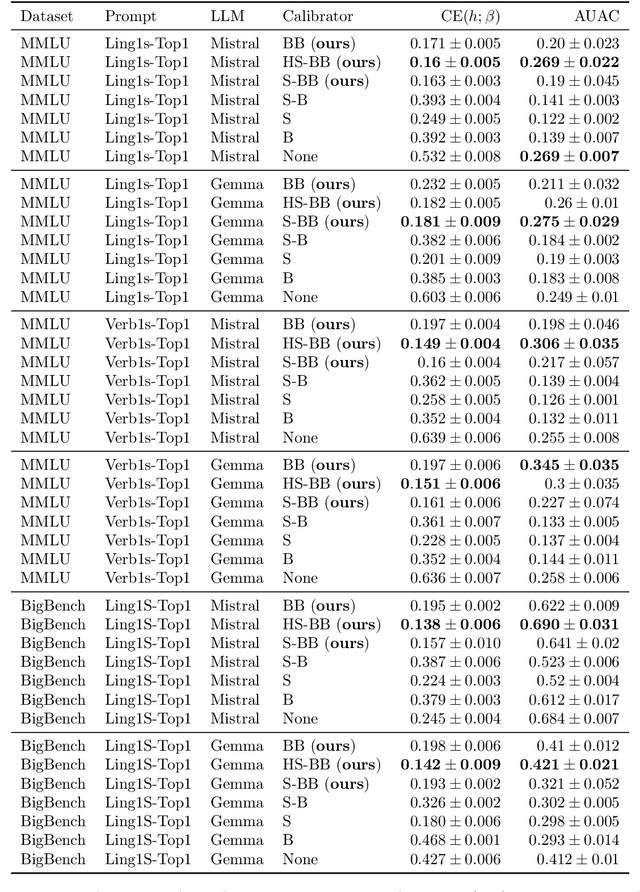
To use generative question-and-answering (QA) systems for decision-making and in any critical application, these systems need to provide well-calibrated confidence scores that reflect the correctness of their answers. Existing calibration methods aim to ensure that the confidence score is on average indicative of the likelihood that the answer is correct. We argue, however, that this standard (average-case) notion of calibration is difficult to interpret for decision-making in generative QA. To address this, we generalize the standard notion of average calibration and introduce $\beta$-calibration, which ensures calibration holds across different question-and-answer groups. We then propose discretized posthoc calibration schemes for achieving $\beta$-calibration.
Estimating Joint interventional distributions from marginal interventional data
Sep 03, 2024In this paper we show how to exploit interventional data to acquire the joint conditional distribution of all the variables using the Maximum Entropy principle. To this end, we extend the Causal Maximum Entropy method to make use of interventional data in addition to observational data. Using Lagrange duality, we prove that the solution to the Causal Maximum Entropy problem with interventional constraints lies in the exponential family, as in the Maximum Entropy solution. Our method allows us to perform two tasks of interest when marginal interventional distributions are provided for any subset of the variables. First, we show how to perform causal feature selection from a mixture of observational and single-variable interventional data, and, second, how to infer joint interventional distributions. For the former task, we show on synthetically generated data, that our proposed method outperforms the state-of-the-art method on merging datasets, and yields comparable results to the KCI-test which requires access to joint observations of all variables.
Causal Information Splitting: Engineering Proxy Features for Robustness to Distribution Shifts
May 10, 2023
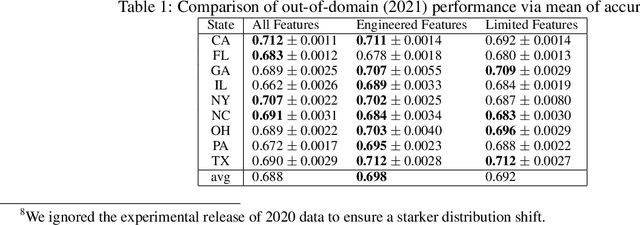
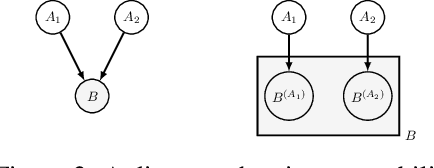
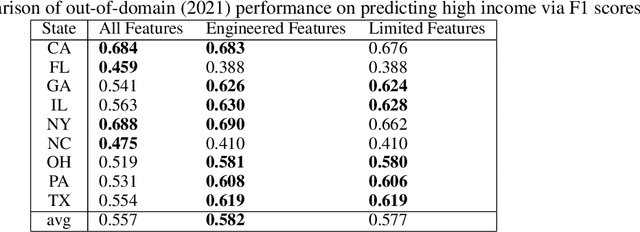
Statistical prediction models are often trained on data that is drawn from different probability distributions than their eventual use cases. One approach to proactively prepare for these shifts harnesses the intuition that causal mechanisms should remain invariant between environments. Here we focus on a challenging setting in which the causal and anticausal variables of the target are unobserved. Leaning on information theory, we develop feature selection and engineering techniques for the observed downstream variables that act as proxies. We identify proxies that help to build stable models and moreover utilize auxiliary training tasks to extract stability-enhancing information from proxies. We demonstrate the effectiveness of our techniques on synthetic and real data.