 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Sampling from Distributions
Paper and Code
Nov 15, 2022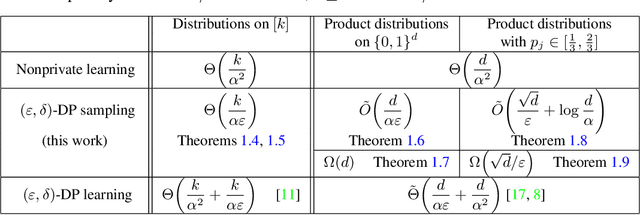
We initiate an investigation of private sampling from distributions. Given a dataset with $n$ independent observations from an unknown distribution $P$, a sampling algorithm must output a single observation from a distribution that is close in total variation distance to $P$ while satisfying differential privacy. Sampling abstracts the goal of generating small amounts of realistic-looking data. We provide tight upper and lower bounds for the dataset size needed for this task for three natural families of distributions: arbitrary distributions on $\{1,\ldots ,k\}$, arbitrary product distributions on $\{0,1\}^d$, and product distributions on $\{0,1\}^d$ with bias in each coordinate bounded away from 0 and 1. We demonstrate that, in some parameter regimes, private sampling requires asymptotically fewer observations than learning a description of $P$ nonprivately; in other regimes, however, private sampling proves to be as difficult as private learning. Notably, for some classes of distributions, the overhead in the number of observations needed for private learning compared to non-private learning is completely captured by the number of observations needed for private sampling.