 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Agreement via Anchoring
Feb 26, 2026Numerous lines of aim to control $\textit{model disagreement}$ -- the extent to which two machine learning models disagree in their predictions. We adopt a simple and standard notion of model disagreement in real-valued prediction problems, namely the expected squared difference in predictions between two models trained on independent samples, without any coordination of the training processes. We would like to be able to drive disagreement to zero with some natural parameter(s) of the training procedure using analyses that can be applied to existing training methodologies. We develop a simple general technique for proving bounds on independent model disagreement based on $\textit{anchoring}$ to the average of two models within the analysis. We then apply this technique to prove disagreement bounds for four commonly used machine learning algorithms: (1) stacked aggregation over an arbitrary model class (where disagreement is driven to 0 with the number of models $k$ being stacked) (2) gradient boosting (where disagreement is driven to 0 with the number of iterations $k$) (3) neural network training with architecture search (where disagreement is driven to 0 with the size $n$ of the architecture being optimized over) and (4) regression tree training over all regression trees of fixed depth (where disagreement is driven to 0 with the depth $d$ of the tree architecture). For clarity, we work out our initial bounds in the setting of one-dimensional regression with squared error loss -- but then show that all of our results generalize to multi-dimensional regression with any strongly convex loss.
Computationally Efficient Replicable Learning of Parities
Feb 10, 2026We study the computational relationship between replicability (Impagliazzo et al. [STOC `22], Ghazi et al. [NeurIPS `21]) and other stability notions. Specifically, we focus on replicable PAC learning and its connections to differential privacy (Dwork et al. [TCC 2006]) and to the statistical query (SQ) model (Kearns [JACM `98]). Statistically, it was known that differentially private learning and replicable learning are equivalent and strictly more powerful than SQ-learning. Yet, computationally, all previously known efficient (i.e., polynomial-time) replicable learning algorithms were confined to SQ-learnable tasks or restricted distributions, in contrast to differentially private learning. Our main contribution is the first computationally efficient replicable algorithm for realizable learning of parities over arbitrary distributions, a task that is known to be hard in the SQ-model, but possible under differential privacy. This result provides the first evidence that efficient replicable learning over general distributions strictly extends efficient SQ-learning, and is closer in power to efficient differentially private learning, despite computational separations between replicability and privacy. Our main building block is a new, efficient, and replicable algorithm that, given a set of vectors, outputs a subspace of their linear span that covers most of them.
Replicable Reinforcement Learning with Linear Function Approximation
Sep 10, 2025Replication of experimental results has been a challenge faced by many scientific disciplines, including the field of machine learning. Recent work on the theory of machine learning has formalized replicability as the demand that an algorithm produce identical outcomes when executed twice on different samples from the same distribution. Provably replicable algorithms are especially interesting for reinforcement learning (RL), where algorithms are known to be unstable in practice. While replicable algorithms exist for tabular RL settings, extending these guarantees to more practical function approximation settings has remained an open problem. In this work, we make progress by developing replicable methods for linear function approximation in RL. We first introduce two efficient algorithms for replicable random design regression and uncentered covariance estimation, each of independent interest. We then leverage these tools to provide the first provably efficient replicable RL algorithms for linear Markov decision processes in both the generative model and episodic settings. Finally, we evaluate our algorithms experimentally and show how they can inspire more consistent neural policies.
Sensitivity of Stability: Theoretical & Empirical Analysis of Replicability for Adaptive Data Selection in Transfer Learning
Aug 06, 2025The widespread adoption of transfer learning has revolutionized machine learning by enabling efficient adaptation of pre-trained models to new domains. However, the reliability of these adaptations remains poorly understood, particularly when using adaptive data selection strategies that dynamically prioritize training examples. We present a comprehensive theoretical and empirical analysis of replicability in transfer learning, introducing a mathematical framework that quantifies the fundamental trade-off between adaptation effectiveness and result consistency. Our key contribution is the formalization of selection sensitivity ($\Delta_Q$), a measure that captures how adaptive selection strategies respond to perturbations in training data. We prove that replicability failure probability: the likelihood that two independent training runs produce models differing in performance by more than a threshold, increases quadratically with selection sensitivity while decreasing exponentially with sample size. Through extensive experiments on the MultiNLI corpus using six adaptive selection strategies - ranging from uniform sampling to gradient-based selection - we demonstrate that this theoretical relationship holds precisely in practice. Our results reveal that highly adaptive strategies like gradient-based and curriculum learning achieve superior task performance but suffer from high replicability failure rates, while less adaptive approaches maintain failure rates below 7%. Crucially, we show that source domain pretraining provides a powerful mitigation mechanism, reducing failure rates by up to 30% while preserving performance gains. These findings establish principled guidelines for practitioners to navigate the performance-replicability trade-off and highlight the need for replicability-aware design in modern transfer learning systems.
Intersectional Fairness in Reinforcement Learning with Large State and Constraint Spaces
Feb 17, 2025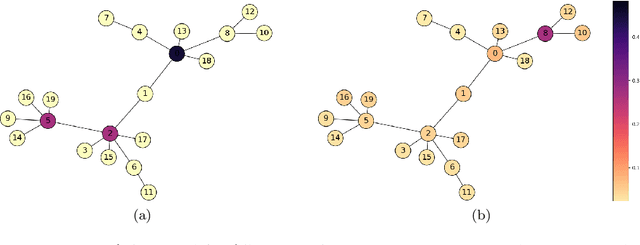


In traditional reinforcement learning (RL), the learner aims to solve a single objective optimization problem: find the policy that maximizes expected reward. However, in many real-world settings, it is important to optimize over multiple objectives simultaneously. For example, when we are interested in fairness, states might have feature annotations corresponding to multiple (intersecting) demographic groups to whom reward accrues, and our goal might be to maximize the reward of the group receiving the minimal reward. In this work, we consider a multi-objective optimization problem in which each objective is defined by a state-based reweighting of a single scalar reward function. This generalizes the problem of maximizing the reward of the minimum reward group. We provide oracle-efficient algorithms to solve these multi-objective RL problems even when the number of objectives is exponentially large-for tabular MDPs, as well as for large MDPs when the group functions have additional structure. Finally, we experimentally validate our theoretical results and demonstrate applications on a preferential attachment graph MDP.
The Cost of Replicability in Active Learning
Dec 12, 2024Active learning aims to reduce the required number of labeled data for machine learning algorithms by selectively querying the labels of initially unlabeled data points. Ensuring the replicability of results, where an algorithm consistently produces the same outcome across different runs, is essential for the reliability of machine learning models but often increases sample complexity. This report investigates the cost of replicability in active learning using the CAL algorithm, a classical disagreement-based active learning method. By integrating replicable statistical query subroutines and random thresholding techniques, we propose two versions of a replicable CAL algorithm. Our theoretical analysis demonstrates that while replicability does increase label complexity, the CAL algorithm can still achieve significant savings in label complexity even with the replicability constraint. These findings offer valuable insights into balancing efficiency and robustness in machine learning models.
Oracle-Efficient Reinforcement Learning for Max Value Ensembles
May 27, 2024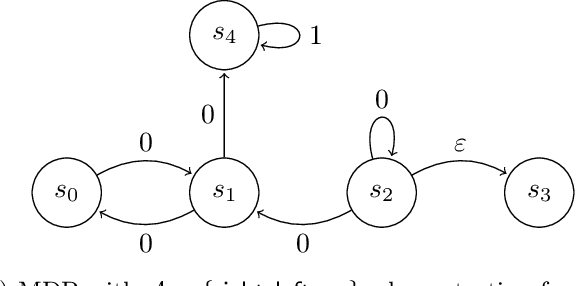
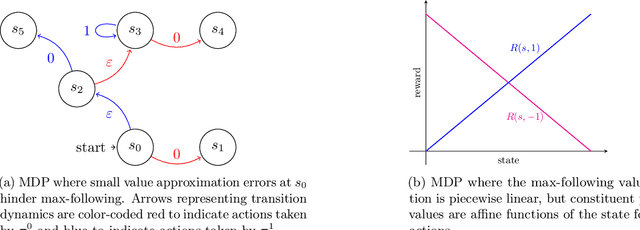
Reinforcement learning (RL) in large or infinite state spaces is notoriously challenging, both theoretically (where worst-case sample and computational complexities must scale with state space cardinality) and experimentally (where function approximation and policy gradient techniques often scale poorly and suffer from instability and high variance). One line of research attempting to address these difficulties makes the natural assumption that we are given a collection of heuristic base or $\textit{constituent}$ policies upon which we would like to improve in a scalable manner. In this work we aim to compete with the $\textit{max-following policy}$, which at each state follows the action of whichever constituent policy has the highest value. The max-following policy is always at least as good as the best constituent policy, and may be considerably better. Our main result is an efficient algorithm that learns to compete with the max-following policy, given only access to the constituent policies (but not their value functions). In contrast to prior work in similar settings, our theoretical results require only the minimal assumption of an ERM oracle for value function approximation for the constituent policies (and not the global optimal policy or the max-following policy itself) on samplable distributions. We illustrate our algorithm's experimental effectiveness and behavior on several robotic simulation testbeds.
Replicable Reinforcement Learning
May 24, 2023
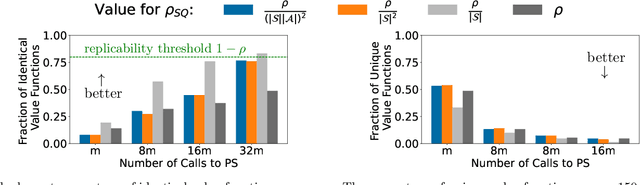
The replicability crisis in the social, behavioral, and data sciences has led to the formulation of algorithm frameworks for replicability -- i.e., a requirement that an algorithm produce identical outputs (with high probability) when run on two different samples from the same underlying distribution. While still in its infancy, provably replicable algorithms have been developed for many fundamental tasks in machine learning and statistics, including statistical query learning, the heavy hitters problem, and distribution testing. In this work we initiate the study of replicable reinforcement learning, providing a provably replicable algorithm for parallel value iteration, and a provably replicable version of R-max in the episodic setting. These are the first formal replicability results for control problems, which present different challenges for replication than batch learning settings.
Stability is Stable: Connections between Replicability, Privacy, and Adaptive Generalization
Mar 25, 2023


The notion of replicable algorithms was introduced in Impagliazzo et al. [STOC '22] to describe randomized algorithms that are stable under the resampling of their inputs. More precisely, a replicable algorithm gives the same output with high probability when its randomness is fixed and it is run on a new i.i.d. sample drawn from the same distribution. Using replicable algorithms for data analysis can facilitate the verification of published results by ensuring that the results of an analysis will be the same with high probability, even when that analysis is performed on a new data set. In this work, we establish new connections and separations between replicability and standard notions of algorithmic stability. In particular, we give sample-efficient algorithmic reductions between perfect generalization, approximate differential privacy, and replicability for a broad class of statistical problems. Conversely, we show any such equivalence must break down computationally: there exist statistical problems that are easy under differential privacy, but that cannot be solved replicably without breaking public-key cryptography. Furthermore, these results are tight: our reductions are statistically optimal, and we show that any computational separation between DP and replicability must imply the existence of one-way functions. Our statistical reductions give a new algorithmic framework for translating between notions of stability, which we instantiate to answer several open questions in replicability and privacy. This includes giving sample-efficient replicable algorithms for various PAC learning, distribution estimation, and distribution testing problems, algorithmic amplification of $\delta$ in approximate DP, conversions from item-level to user-level privacy, and the existence of private agnostic-to-realizable learning reductions under structured distributions.
Multicalibration as Boosting for Regression
Jan 31, 2023We study the connection between multicalibration and boosting for squared error regression. First we prove a useful characterization of multicalibration in terms of a ``swap regret'' like condition on squared error. Using this characterization, we give an exceedingly simple algorithm that can be analyzed both as a boosting algorithm for regression and as a multicalibration algorithm for a class H that makes use only of a standard squared error regression oracle for H. We give a weak learning assumption on H that ensures convergence to Bayes optimality without the need to make any realizability assumptions -- giving us an agnostic boosting algorithm for regression. We then show that our weak learning assumption on H is both necessary and sufficient for multicalibration with respect to H to imply Bayes optimality. We also show that if H satisfies our weak learning condition relative to another class C then multicalibration with respect to H implies multicalibration with respect to C. Finally we investigate the empirical performance of our algorithm experimentally using an open source implementation that we make available. Our code repository can be found at https://github.com/Declancharrison/Level-Set-Boosting.