 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubliminal Effects in Your Data: A General Mechanism via Log-Linearity
Feb 04, 2026Training modern large language models (LLMs) has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.
On the Injective Norm of Sums of Random Tensors and the Moments of Gaussian Chaoses
Mar 13, 2025We prove an upper bound on the expected $\ell_p$ injective norm of sums of subgaussian random tensors. Our proof is simple and does not rely on any explicit geometric or chaining arguments. Instead, it follows from a simple application of the PAC-Bayesian lemma, a tool that has proven effective at controlling the suprema of certain ``smooth'' empirical processes in recent years. Our bound strictly improves a very recent result of Bandeira, Gopi, Jiang, Lucca, and Rothvoss. In the Euclidean case ($p=2$), our bound sharpens a result of Lata{\l}a that was central to proving his estimates on the moments of Gaussian chaoses. As a consequence, we obtain an elementary proof of this fundamental result.
Majority-of-Three: The Simplest Optimal Learner?
Mar 12, 2024Developing an optimal PAC learning algorithm in the realizable setting, where empirical risk minimization (ERM) is suboptimal, was a major open problem in learning theory for decades. The problem was finally resolved by Hanneke a few years ago. Unfortunately, Hanneke's algorithm is quite complex as it returns the majority vote of many ERM classifiers that are trained on carefully selected subsets of the data. It is thus a natural goal to determine the simplest algorithm that is optimal. In this work we study the arguably simplest algorithm that could be optimal: returning the majority vote of three ERM classifiers. We show that this algorithm achieves the optimal in-expectation bound on its error which is provably unattainable by a single ERM classifier. Furthermore, we prove a near-optimal high-probability bound on this algorithm's error. We conjecture that a better analysis will prove that this algorithm is in fact optimal in the high-probability regime.
Optimal PAC Bounds Without Uniform Convergence
Apr 18, 2023In statistical learning theory, determining the sample complexity of realizable binary classification for VC classes was a long-standing open problem. The results of Simon and Hanneke established sharp upper bounds in this setting. However, the reliance of their argument on the uniform convergence principle limits its applicability to more general learning settings such as multiclass classification. In this paper, we address this issue by providing optimal high probability risk bounds through a framework that surpasses the limitations of uniform convergence arguments. Our framework converts the leave-one-out error of permutation invariant predictors into high probability risk bounds. As an application, by adapting the one-inclusion graph algorithm of Haussler, Littlestone, and Warmuth, we propose an algorithm that achieves an optimal PAC bound for binary classification. Specifically, our result shows that certain aggregations of one-inclusion graph algorithms are optimal, addressing a variant of a classic question posed by Warmuth. We further instantiate our framework in three settings where uniform convergence is provably suboptimal. For multiclass classification, we prove an optimal risk bound that scales with the one-inclusion hypergraph density of the class, addressing the suboptimality of the analysis of Daniely and Shalev-Shwartz. For partial hypothesis classification, we determine the optimal sample complexity bound, resolving a question posed by Alon, Hanneke, Holzman, and Moran. For realizable bounded regression with absolute loss, we derive an optimal risk bound that relies on a modified version of the scale-sensitive dimension, refining the results of Bartlett and Long. Our rates surpass standard uniform convergence-based results due to the smaller complexity measure in our risk bound.
The One-Inclusion Graph Algorithm is not Always Optimal
Dec 19, 2022The one-inclusion graph algorithm of Haussler, Littlestone, and Warmuth achieves an optimal in-expectation risk bound in the standard PAC classification setup. In one of the first COLT open problems, Warmuth conjectured that this prediction strategy always implies an optimal high probability bound on the risk, and hence is also an optimal PAC algorithm. We refute this conjecture in the strongest sense: for any practically interesting Vapnik-Chervonenkis class, we provide an in-expectation optimal one-inclusion graph algorithm whose high probability risk bound cannot go beyond that implied by Markov's inequality. Our construction of these poorly performing one-inclusion graph algorithms uses Varshamov-Tenengolts error correcting codes. Our negative result has several implications. First, it shows that the same poor high-probability performance is inherited by several recent prediction strategies based on generalizations of the one-inclusion graph algorithm. Second, our analysis shows yet another statistical problem that enjoys an estimator that is provably optimal in expectation via a leave-one-out argument, but fails in the high-probability regime. This discrepancy occurs despite the boundedness of the binary loss for which arguments based on concentration inequalities often provide sharp high probability risk bounds.
Privately Learning Mixtures of Axis-Aligned Gaussians
Jun 03, 2021We consider the problem of learning mixtures of Gaussians under the constraint of approximate differential privacy. We prove that $\widetilde{O}(k^2 d \log^{3/2}(1/\delta) / \alpha^2 \varepsilon)$ samples are sufficient to learn a mixture of $k$ axis-aligned Gaussians in $\mathbb{R}^d$ to within total variation distance $\alpha$ while satisfying $(\varepsilon, \delta)$-differential privacy. This is the first result for privately learning mixtures of unbounded axis-aligned (or even unbounded univariate) Gaussians. If the covariance matrices of each of the Gaussians is the identity matrix, we show that $\widetilde{O}(kd/\alpha^2 + kd \log(1/\delta) / \alpha \varepsilon)$ samples are sufficient. Recently, the "local covering" technique of Bun, Kamath, Steinke, and Wu has been successfully used for privately learning high-dimensional Gaussians with a known covariance matrix and extended to privately learning general high-dimensional Gaussians by Aden-Ali, Ashtiani, and Kamath. Given these positive results, this approach has been proposed as a promising direction for privately learning mixtures of Gaussians. Unfortunately, we show that this is not possible. We design a new technique for privately learning mixture distributions. A class of distributions $\mathcal{F}$ is said to be list-decodable if there is an algorithm that, given "heavily corrupted" samples from $f\in \mathcal{F}$, outputs a list of distributions, $\widehat{\mathcal{F}}$, such that one of the distributions in $\widehat{\mathcal{F}}$ approximates $f$. We show that if $\mathcal{F}$ is privately list-decodable, then we can privately learn mixtures of distributions in $\mathcal{F}$. Finally, we show axis-aligned Gaussian distributions are privately list-decodable, thereby proving mixtures of such distributions are privately learnable.
On the Sample Complexity of Privately Learning Unbounded High-Dimensional Gaussians
Oct 19, 2020We provide sample complexity upper bounds for agnostically learning multivariate Gaussians under the constraint of approximate differential privacy. These are the first finite sample upper bounds for general Gaussians which do not impose restrictions on the parameters of the distribution. Our bounds are near-optimal in the case when the covariance is known to be the identity, and conjectured to be near-optimal in the general case. From a technical standpoint, we provide analytic tools for arguing the existence of global "locally small" covers from local covers of the space. These are exploited using modifications of recent techniques for differentially private hypothesis selection. Our techniques may prove useful for privately learning other distribution classes which do not possess a finite cover.
On the Sample Complexity of Learning Sum-Product Networks
Dec 05, 2019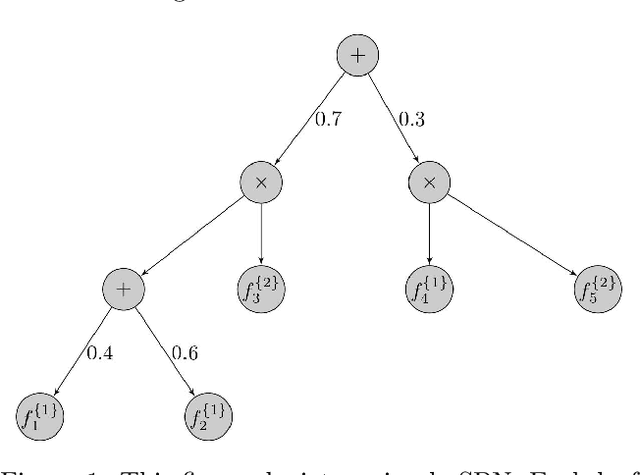
Sum-Product Networks (SPNs) can be regarded as a form of deep graphical models that compactly represent deeply factored and mixed distributions. An SPN is a rooted directed acyclic graph (DAG) consisting of a set of leaves (corresponding to base distributions), a set of sum nodes (which represent mixtures of their children distributions) and a set of product nodes (representing the products of its children distributions). In this work, we initiate the study of the sample complexity of PAC-learning the set of distributions that correspond to SPNs. We show that the sample complexity of learning tree structured SPNs with the usual type of leaves (i.e., Gaussian or discrete) grows at most linearly (up to logarithmic factors) with the number of parameters of the SPN. More specifically, we show that the class of distributions that corresponds to tree structured Gaussian SPNs with $k$ mixing weights and $e$ ($d$-dimensional Gaussian) leaves can be learned within Total Variation error $\epsilon$ using at most $\widetilde{O}(\frac{ed^2+k}{\epsilon^2})$ samples. A similar result holds for tree structured SPNs with discrete leaves. We obtain the upper bounds based on the recently proposed notion of distribution compression schemes. More specifically, we show that if a (base) class of distributions $\mathcal{F}$ admits an "efficient" compression, then the class of tree structured SPNs with leaves from $\mathcal{F}$ also admits an efficient compression.