 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpress Language Modeling
Jun 09, 2026We introduce a new tool, Express, for converting a non-causal attention approximation into a causal approximation with matching approximation guarantees. When combined with the state-of-the-art Thinformer approximation, Express improves upon the best known causal attention guarantees, delivering $\log^{3/2}(n)/s$ approximation error with only $O(s)$ memory and $O(s^2 \log^2(n))$ compression overhead for a sequence of length $n$. We pair these developments with an efficient I/O-aware Triton implementation, demonstrate substantial speedups over FlashAttention 2, and use Express to overcome four resource bottlenecks in the language modeling pipeline: long-context prefill, KV cache compression, long-form memory-constrained decoding, and long-form compute-constrained decoding.
Low-Rank Thinning
Feb 17, 2025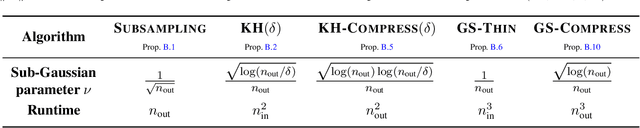
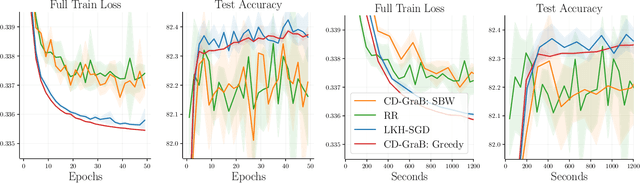

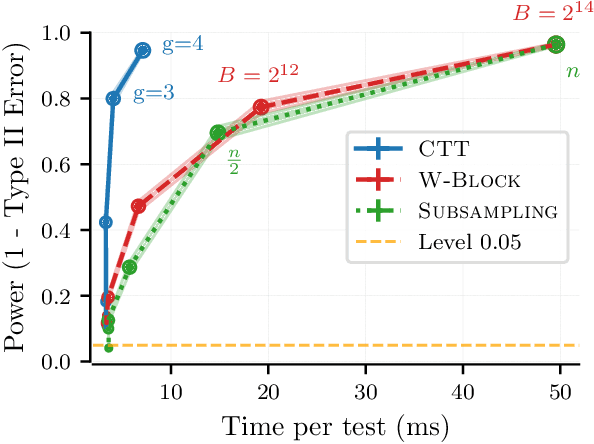
The goal in thinning is to summarize a dataset using a small set of representative points. Remarkably, sub-Gaussian thinning algorithms like Kernel Halving and Compress can match the quality of uniform subsampling while substantially reducing the number of summary points. However, existing guarantees cover only a restricted range of distributions and kernel-based quality measures and suffer from pessimistic dimension dependence. To address these deficiencies, we introduce a new low-rank analysis of sub-Gaussian thinning that applies to any distribution and any kernel, guaranteeing high-quality compression whenever the kernel or data matrix is approximately low-rank. To demonstrate the broad applicability of the techniques, we design practical sub-Gaussian thinning approaches that improve upon the best known guarantees for approximating attention in transformers, accelerating stochastic gradient training through reordering, and distinguishing distributions in near-linear time.