 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentive-Aware Synthetic Control: Accurate Counterfactual Estimation via Incentivized Exploration
Dec 26, 2023
We consider a panel data setting in which one observes measurements of units over time, under different interventions. Our focus is on the canonical family of synthetic control methods (SCMs) which, after a pre-intervention time period when all units are under control, estimate counterfactual outcomes for test units in the post-intervention time period under control by using data from donor units who have remained under control for the entire post-intervention period. In order for the counterfactual estimate produced by synthetic control for a test unit to be accurate, there must be sufficient overlap between the outcomes of the donor units and the outcomes of the test unit. As a result, a canonical assumption in the literature on SCMs is that the outcomes for the test units lie within either the convex hull or the linear span of the outcomes for the donor units. However despite their ubiquity, such overlap assumptions may not always hold, as is the case when, e.g., units select their own interventions and different subpopulations of units prefer different interventions a priori. We shed light on this typically overlooked assumption, and we address this issue by incentivizing units with different preferences to take interventions they would not normally consider. Specifically, we provide a SCM for incentivizing exploration in panel data settings which provides incentive-compatible intervention recommendations to units by leveraging tools from information design and online learning. Using our algorithm, we show how to obtain valid counterfactual estimates using SCMs without the need for an explicit overlap assumption on the unit outcomes.
Incentivizing Compliance with Algorithmic Instruments
Jul 28, 2021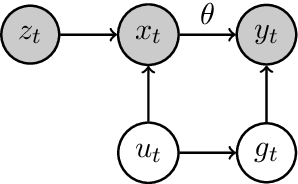

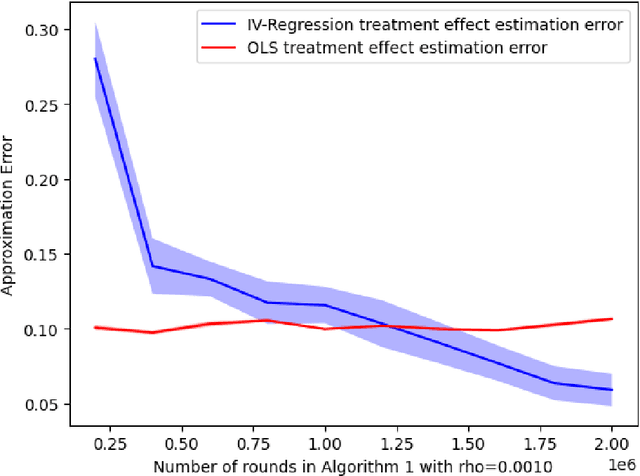
Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history -- the interactions between the planner and the previous agents -- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
Strategic Instrumental Variable Regression: Recovering Causal Relationships From Strategic Responses
Jul 12, 2021


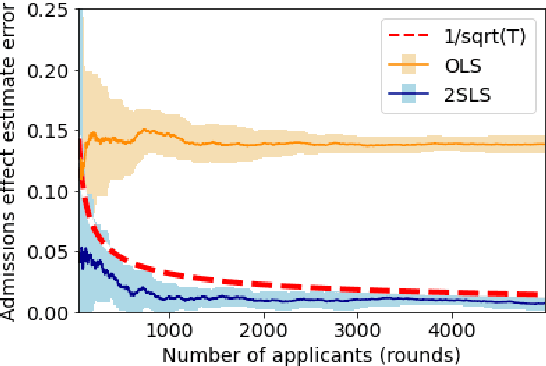
Machine Learning algorithms often prompt individuals to strategically modify their observable attributes to receive more favorable predictions. As a result, the distribution the predictive model is trained on may differ from the one it operates on in deployment. While such distribution shifts, in general, hinder accurate predictions, our work identifies a unique opportunity associated with shifts due to strategic responses: We show that we can use strategic responses effectively to recover causal relationships between the observable features and outcomes we wish to predict. More specifically, we study a game-theoretic model in which a principal deploys a sequence of models to predict an outcome of interest (e.g., college GPA) for a sequence of strategic agents (e.g., college applicants). In response, strategic agents invest efforts and modify their features for better predictions. In such settings, unobserved confounding variables can influence both an agent's observable features (e.g., high school records) and outcomes. Therefore, standard regression methods generally produce biased estimators. In order to address this issue, our work establishes a novel connection between strategic responses to machine learning models and instrumental variable (IV) regression, by observing that the sequence of deployed models can be viewed as an instrument that affects agents' observable features but does not directly influence their outcomes. Therefore, two-stage least squares (2SLS) regression can recover the causal relationships between observable features and outcomes. Beyond causal recovery, we can build on our 2SLS method to address two additional relevant optimization objectives: agent outcome maximization and predictive risk minimization. Finally, our numerical simulations on semi-synthetic data show that our methods significantly outperform OLS regression in causal relationship estimation.