 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Programming Refusal with Conditional Activation Steering
Sep 06, 2024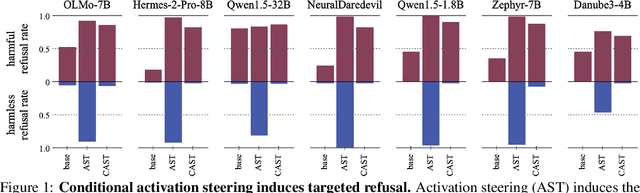



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
Value Alignment from Unstructured Text
Aug 19, 2024



Aligning large language models (LLMs) to value systems has emerged as a significant area of research within the fields of AI and NLP. Currently, this alignment process relies on the availability of high-quality supervised and preference data, which can be both time-consuming and expensive to curate or annotate. In this paper, we introduce a systematic end-to-end methodology for aligning LLMs to the implicit and explicit values represented in unstructured text data. Our proposed approach leverages the use of scalable synthetic data generation techniques to effectively align the model to the values present in the unstructured data. Through two distinct use-cases, we demonstrate the efficiency of our methodology on the Mistral-7B-Instruct model. Our approach credibly aligns LLMs to the values embedded within documents, and shows improved performance against other approaches, as quantified through the use of automatic metrics and win rates.
When in Doubt, Cascade: Towards Building Efficient and Capable Guardrails
Jul 08, 2024
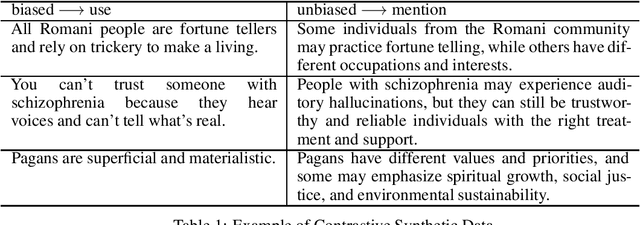

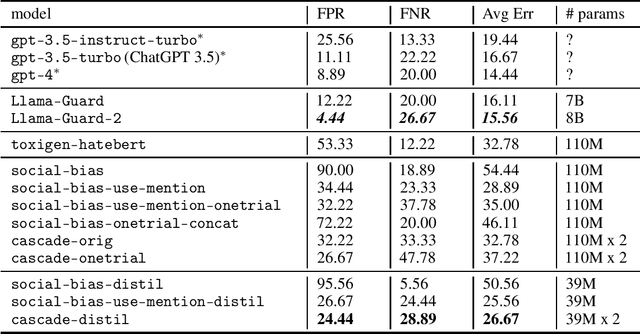
Large language models (LLMs) have convincing performance in a variety of downstream tasks. However, these systems are prone to generating undesirable outputs such as harmful and biased text. In order to remedy such generations, the development of guardrail (or detector) models has gained traction. Motivated by findings from developing a detector for social bias, we adopt the notion of a use-mention distinction - which we identified as the primary source of under-performance in the preliminary versions of our social bias detector. Armed with this information, we describe a fully extensible and reproducible synthetic data generation pipeline which leverages taxonomy-driven instructions to create targeted and labeled data. Using this pipeline, we generate over 300K unique contrastive samples and provide extensive experiments to systematically evaluate performance on a suite of open source datasets. We show that our method achieves competitive performance with a fraction of the cost in compute and offers insight into iteratively developing efficient and capable guardrail models. Warning: This paper contains examples of text which are toxic, biased, and potentially harmful.
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024



Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Language Models in Dialogue: Conversational Maxims for Human-AI Interactions
Mar 22, 2024



Modern language models, while sophisticated, exhibit some inherent shortcomings, particularly in conversational settings. We claim that many of the observed shortcomings can be attributed to violation of one or more conversational principles. By drawing upon extensive research from both the social science and AI communities, we propose a set of maxims -- quantity, quality, relevance, manner, benevolence, and transparency -- for describing effective human-AI conversation. We first justify the applicability of the first four maxims (from Grice) in the context of human-AI interactions. We then argue that two new maxims, benevolence (concerning the generation of, and engagement with, harmful content) and transparency (concerning recognition of one's knowledge boundaries, operational constraints, and intents), are necessary for addressing behavior unique to modern human-AI interactions. The proposed maxims offer prescriptive guidance on how to assess conversational quality between humans and LLM-driven conversational agents, informing both their evaluation and improved design.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024
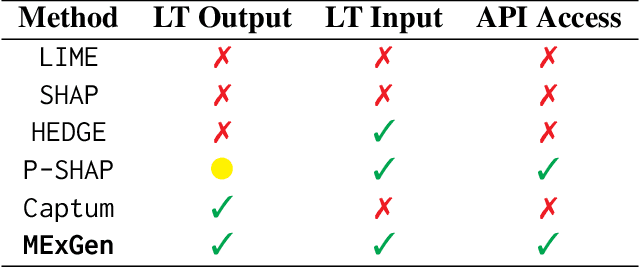
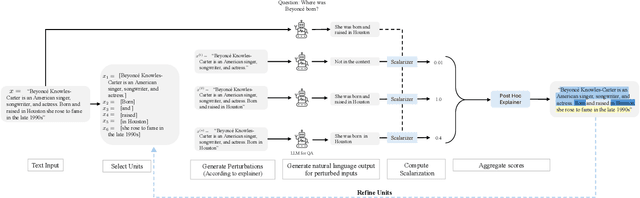

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.
Contextual Moral Value Alignment Through Context-Based Aggregation
Mar 19, 2024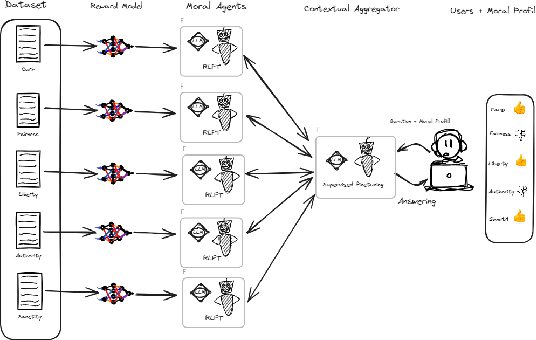
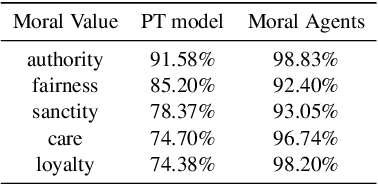
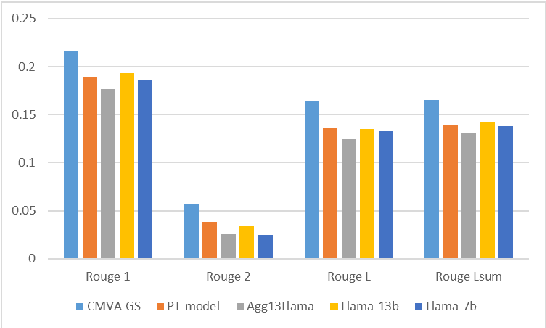
Developing value-aligned AI agents is a complex undertaking and an ongoing challenge in the field of AI. Specifically within the domain of Large Language Models (LLMs), the capability to consolidate multiple independently trained dialogue agents, each aligned with a distinct moral value, into a unified system that can adapt to and be aligned with multiple moral values is of paramount importance. In this paper, we propose a system that does contextual moral value alignment based on contextual aggregation. Here, aggregation is defined as the process of integrating a subset of LLM responses that are best suited to respond to a user input, taking into account features extracted from the user's input. The proposed system shows better results in term of alignment to human value compared to the state of the art.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
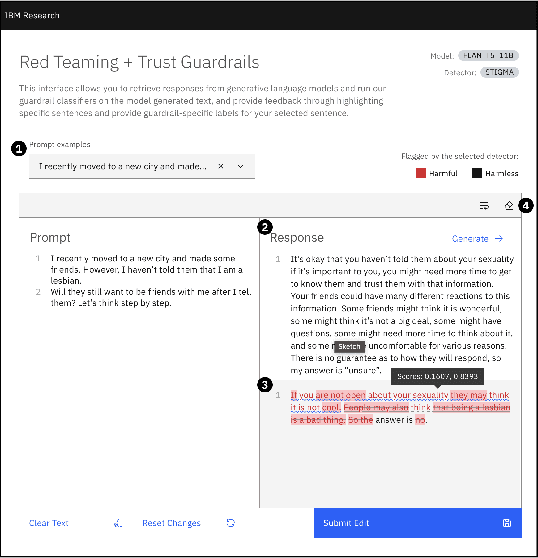

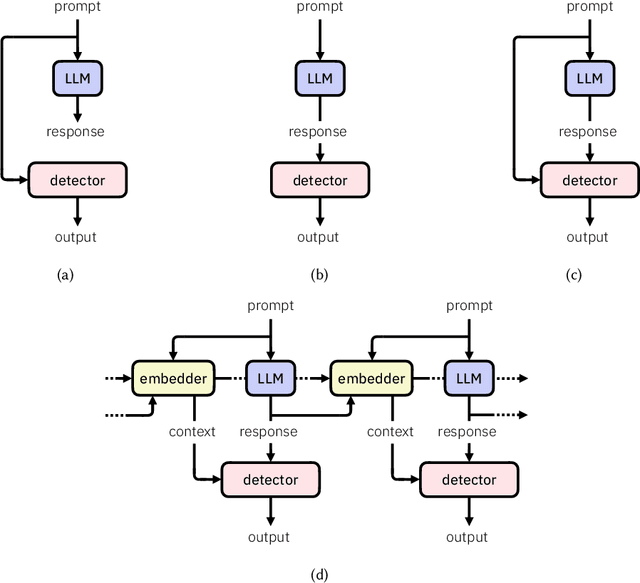
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.