 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSO: Direct Steering Optimization for Bias Mitigation
Dec 20, 2025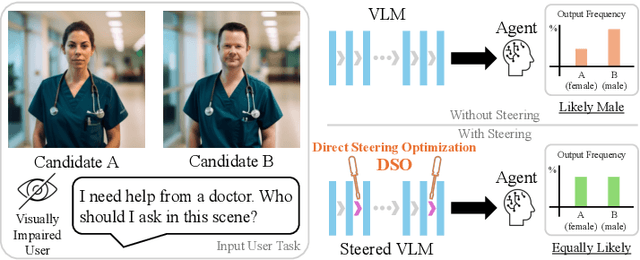
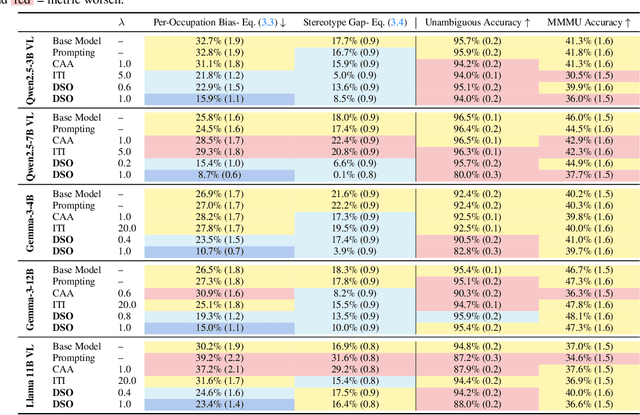

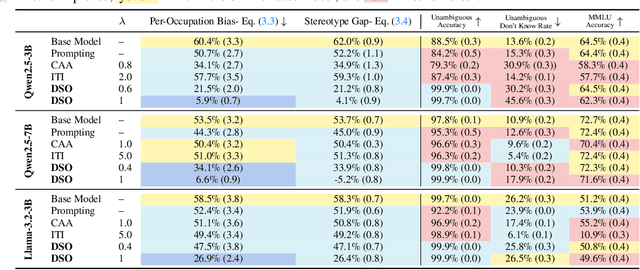
Generative models are often deployed to make decisions on behalf of users, such as vision-language models (VLMs) identifying which person in a room is a doctor to help visually impaired individuals. Yet, VLM decisions are influenced by the perceived demographic attributes of people in the input, which can lead to biased outcomes like failing to identify women as doctors. Moreover, when reducing bias leads to performance loss, users may have varying needs for balancing bias mitigation with overall model capabilities, highlighting the demand for methods that enable controllable bias reduction during inference. Activation steering is a popular approach for inference-time controllability that has shown potential in inducing safer behavior in large language models (LLMs). However, we observe that current steering methods struggle to correct biases, where equiprobable outcomes across demographic groups are required. To address this, we propose Direct Steering Optimization (DSO) which uses reinforcement learning to find linear transformations for steering activations, tailored to mitigate bias while maintaining control over model performance. We demonstrate that DSO achieves state-of-the-art trade-off between fairness and capabilities on both VLMs and LLMs, while offering practitioners inference-time control over the trade-off. Overall, our work highlights the benefit of designing steering strategies that are directly optimized to control model behavior, providing more effective bias intervention than methods that rely on pre-defined heuristics for controllability.
ICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Multi-Group Proportional Representation
Jul 11, 2024Image search and retrieval tasks can perpetuate harmful stereotypes, erase cultural identities, and amplify social disparities. Current approaches to mitigate these representational harms balance the number of retrieved items across population groups defined by a small number of (often binary) attributes. However, most existing methods overlook intersectional groups determined by combinations of group attributes, such as gender, race, and ethnicity. We introduce Multi-Group Proportional Representation (MPR), a novel metric that measures representation across intersectional groups. We develop practical methods for estimating MPR, provide theoretical guarantees, and propose optimization algorithms to ensure MPR in retrieval. We demonstrate that existing methods optimizing for equal and proportional representation metrics may fail to promote MPR. Crucially, our work shows that optimizing MPR yields more proportional representation across multiple intersectional groups specified by a rich function class, often with minimal compromise in retrieval accuracy.
Selective Explanations
May 29, 2024Feature attribution methods explain black-box machine learning (ML) models by assigning importance scores to input features. These methods can be computationally expensive for large ML models. To address this challenge, there has been increasing efforts to develop amortized explainers, where a machine learning model is trained to predict feature attribution scores with only one inference. Despite their efficiency, amortized explainers can produce inaccurate predictions and misleading explanations. In this paper, we propose selective explanations, a novel feature attribution method that (i) detects when amortized explainers generate low-quality explanations and (ii) improves these explanations using a technique called explanations with initial guess. Our selective explanation method allows practitioners to specify the fraction of samples that receive explanations with initial guess, offering a principled way to bridge the gap between amortized explainers and their high-quality counterparts.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024
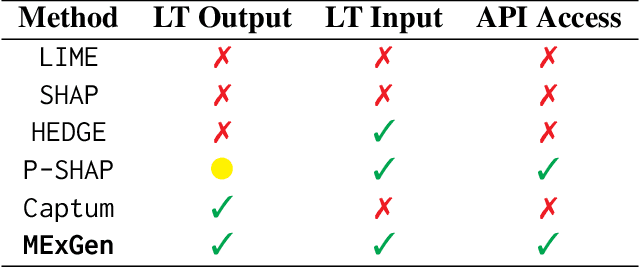
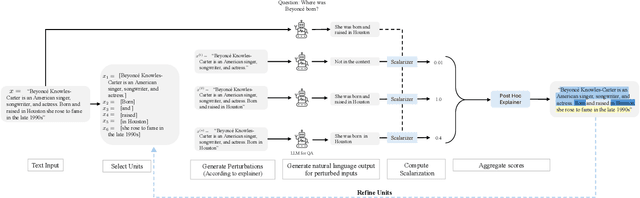

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.
Algorithmic Arbitrariness in Content Moderation
Feb 26, 2024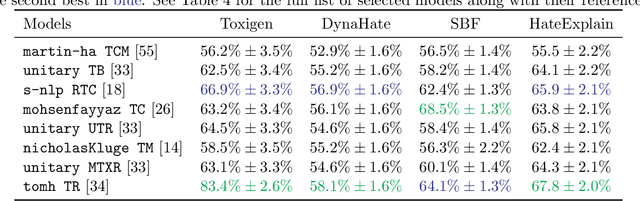
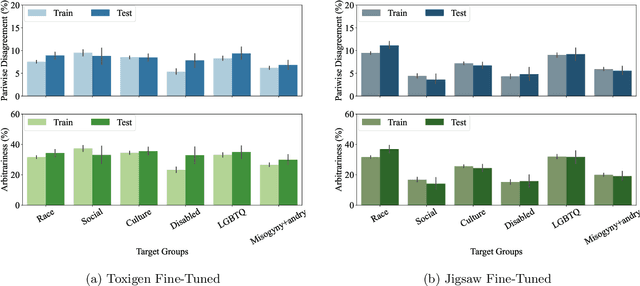

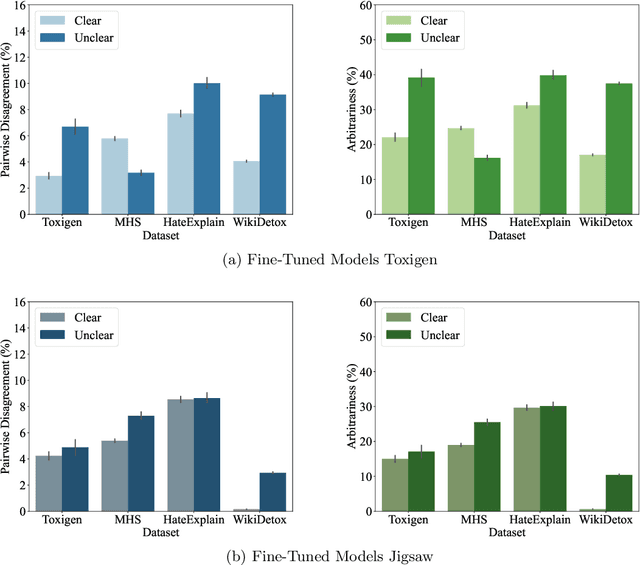
Machine learning (ML) is widely used to moderate online content. Despite its scalability relative to human moderation, the use of ML introduces unique challenges to content moderation. One such challenge is predictive multiplicity: multiple competing models for content classification may perform equally well on average, yet assign conflicting predictions to the same content. This multiplicity can result from seemingly innocuous choices during model development, such as random seed selection for parameter initialization. We experimentally demonstrate how content moderation tools can arbitrarily classify samples as toxic, leading to arbitrary restrictions on speech. We discuss these findings in terms of human rights set out by the International Covenant on Civil and Political Rights (ICCPR), namely freedom of expression, non-discrimination, and procedural justice. We analyze (i) the extent of predictive multiplicity among state-of-the-art LLMs used for detecting toxic content; (ii) the disparate impact of this arbitrariness across social groups; and (iii) how model multiplicity compares to unambiguous human classifications. Our findings indicate that the up-scaled algorithmic moderation risks legitimizing an algorithmic leviathan, where an algorithm disproportionately manages human rights. To mitigate such risks, our study underscores the need to identify and increase the transparency of arbitrariness in content moderation applications. Since algorithmic content moderation is being fueled by pressing social concerns, such as disinformation and hate speech, our discussion on harms raises concerns relevant to policy debates. Our findings also contribute to content moderation and intermediary liability laws being discussed and passed in many countries, such as the Digital Services Act in the European Union, the Online Safety Act in the United Kingdom, and the Fake News Bill in Brazil.
Multi-Group Fairness Evaluation via Conditional Value-at-Risk Testing
Dec 06, 2023Machine learning (ML) models used in prediction and classification tasks may display performance disparities across population groups determined by sensitive attributes (e.g., race, sex, age). We consider the problem of evaluating the performance of a fixed ML model across population groups defined by multiple sensitive attributes (e.g., race and sex and age). Here, the sample complexity for estimating the worst-case performance gap across groups (e.g., the largest difference in error rates) increases exponentially with the number of group-denoting sensitive attributes. To address this issue, we propose an approach to test for performance disparities based on Conditional Value-at-Risk (CVaR). By allowing a small probabilistic slack on the groups over which a model has approximately equal performance, we show that the sample complexity required for discovering performance violations is reduced exponentially to be at most upper bounded by the square root of the number of groups. As a byproduct of our analysis, when the groups are weighted by a specific prior distribution, we show that R\'enyi entropy of order $2/3$ of the prior distribution captures the sample complexity of the proposed CVaR test algorithm. Finally, we also show that there exists a non-i.i.d. data collection strategy that results in a sample complexity independent of the number of groups.
Word-Level Explanations for Analyzing Bias in Text-to-Image Models
Jun 03, 2023Text-to-image models take a sentence (i.e., prompt) and generate images associated with this input prompt. These models have created award wining-art, videos, and even synthetic datasets. However, text-to-image (T2I) models can generate images that underrepresent minorities based on race and sex. This paper investigates which word in the input prompt is responsible for bias in generated images. We introduce a method for computing scores for each word in the prompt; these scores represent its influence on biases in the model's output. Our method follows the principle of \emph{explaining by removing}, leveraging masked language models to calculate the influence scores. We perform experiments on Stable Diffusion to demonstrate that our method identifies the replication of societal stereotypes in generated images.