 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Arbitrariness in Content Moderation
Feb 26, 2024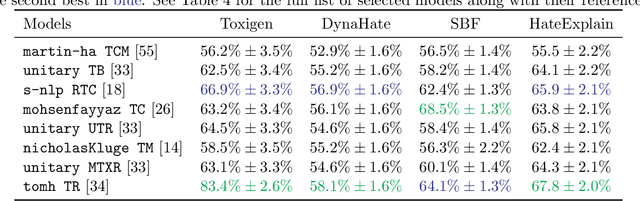
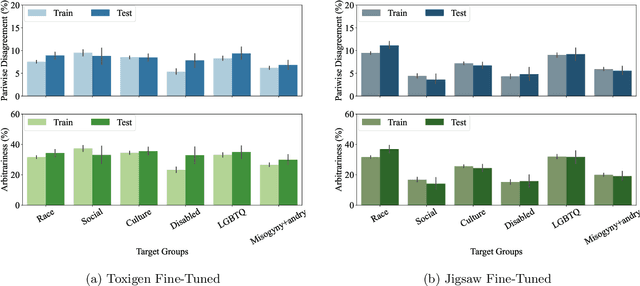

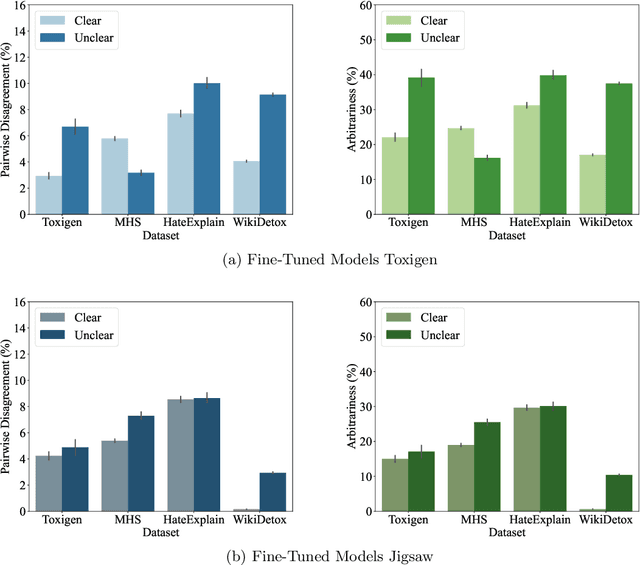
Machine learning (ML) is widely used to moderate online content. Despite its scalability relative to human moderation, the use of ML introduces unique challenges to content moderation. One such challenge is predictive multiplicity: multiple competing models for content classification may perform equally well on average, yet assign conflicting predictions to the same content. This multiplicity can result from seemingly innocuous choices during model development, such as random seed selection for parameter initialization. We experimentally demonstrate how content moderation tools can arbitrarily classify samples as toxic, leading to arbitrary restrictions on speech. We discuss these findings in terms of human rights set out by the International Covenant on Civil and Political Rights (ICCPR), namely freedom of expression, non-discrimination, and procedural justice. We analyze (i) the extent of predictive multiplicity among state-of-the-art LLMs used for detecting toxic content; (ii) the disparate impact of this arbitrariness across social groups; and (iii) how model multiplicity compares to unambiguous human classifications. Our findings indicate that the up-scaled algorithmic moderation risks legitimizing an algorithmic leviathan, where an algorithm disproportionately manages human rights. To mitigate such risks, our study underscores the need to identify and increase the transparency of arbitrariness in content moderation applications. Since algorithmic content moderation is being fueled by pressing social concerns, such as disinformation and hate speech, our discussion on harms raises concerns relevant to policy debates. Our findings also contribute to content moderation and intermediary liability laws being discussed and passed in many countries, such as the Digital Services Act in the European Union, the Online Safety Act in the United Kingdom, and the Fake News Bill in Brazil.