 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcMark: Multi-bit LLM Watermark via Optimal Transport
Feb 06, 2026Watermarking is an important tool for promoting the responsible use of language models (LMs). Existing watermarks insert a signal into generated tokens that either flags LM-generated text (zero-bit watermarking) or encodes more complex messages (multi-bit watermarking). Though a number of recent multi-bit watermarks insert several bits into text without perturbing average next-token predictions, they largely extend design principles from the zero-bit setting, such as encoding a single bit per token. Notably, the information-theoretic capacity of multi-bit watermarking -- the maximum number of bits per token that can be inserted and detected without changing average next-token predictions -- has remained unknown. We address this gap by deriving the first capacity characterization of multi-bit watermarks. Our results inform the design of ArcMark: a new watermark construction based on coding-theoretic principles that, under certain assumptions, achieves the capacity of the multi-bit watermark channel. In practice, ArcMark outperforms competing multi-bit watermarks in terms of bit rate per token and detection accuracy. Our work demonstrates that LM watermarking is fundamentally a channel coding problem, paving the way for principled coding-theoretic approaches to watermark design.
HeavyWater and SimplexWater: Watermarking Low-Entropy Text Distributions
Jun 06, 2025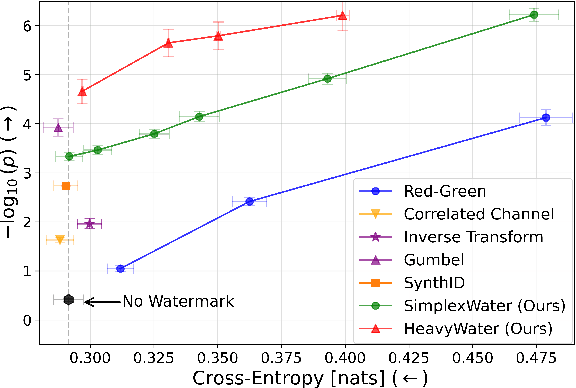
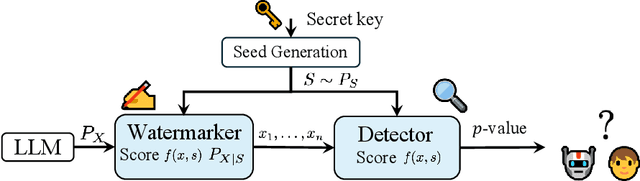
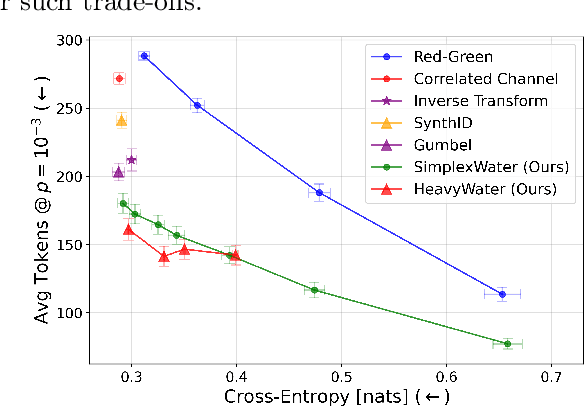
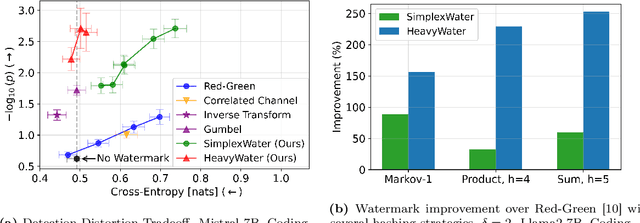
Large language model (LLM) watermarks enable authentication of text provenance, curb misuse of machine-generated text, and promote trust in AI systems. Current watermarks operate by changing the next-token predictions output by an LLM. The updated (i.e., watermarked) predictions depend on random side information produced, for example, by hashing previously generated tokens. LLM watermarking is particularly challenging in low-entropy generation tasks - such as coding - where next-token predictions are near-deterministic. In this paper, we propose an optimization framework for watermark design. Our goal is to understand how to most effectively use random side information in order to maximize the likelihood of watermark detection and minimize the distortion of generated text. Our analysis informs the design of two new watermarks: HeavyWater and SimplexWater. Both watermarks are tunable, gracefully trading-off between detection accuracy and text distortion. They can also be applied to any LLM and are agnostic to side information generation. We examine the performance of HeavyWater and SimplexWater through several benchmarks, demonstrating that they can achieve high watermark detection accuracy with minimal compromise of text generation quality, particularly in the low-entropy regime. Our theoretical analysis also reveals surprising new connections between LLM watermarking and coding theory. The code implementation can be found in https://github.com/DorTsur/HeavyWater_SimplexWater
Multi-Group Proportional Representation for Text-to-Image Models
May 29, 2025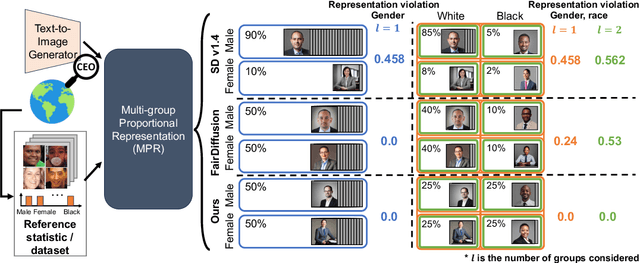
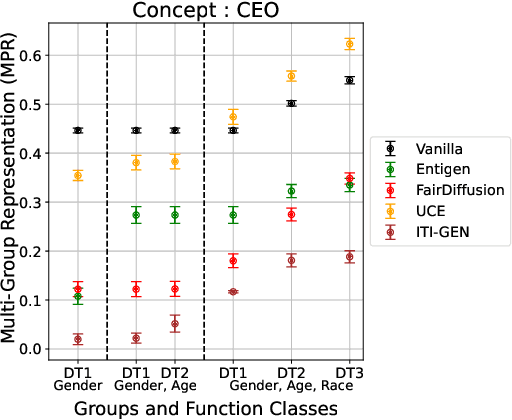
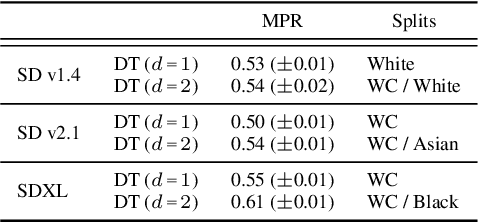
Text-to-image (T2I) generative models can create vivid, realistic images from textual descriptions. As these models proliferate, they expose new concerns about their ability to represent diverse demographic groups, propagate stereotypes, and efface minority populations. Despite growing attention to the "safe" and "responsible" design of artificial intelligence (AI), there is no established methodology to systematically measure and control representational harms in image generation. This paper introduces a novel framework to measure the representation of intersectional groups in images generated by T2I models by applying the Multi-Group Proportional Representation (MPR) metric. MPR evaluates the worst-case deviation of representation statistics across given population groups in images produced by a generative model, allowing for flexible and context-specific measurements based on user requirements. We also develop an algorithm to optimize T2I models for this metric. Through experiments, we demonstrate that MPR can effectively measure representation statistics across multiple intersectional groups and, when used as a training objective, can guide models toward a more balanced generation across demographic groups while maintaining generation quality.
Optimized Couplings for Watermarking Large Language Models
May 13, 2025Large-language models (LLMs) are now able to produce text that is, in many cases, seemingly indistinguishable from human-generated content. This has fueled the development of watermarks that imprint a ``signal'' in LLM-generated text with minimal perturbation of an LLM's output. This paper provides an analysis of text watermarking in a one-shot setting. Through the lens of hypothesis testing with side information, we formulate and analyze the fundamental trade-off between watermark detection power and distortion in generated textual quality. We argue that a key component in watermark design is generating a coupling between the side information shared with the watermark detector and a random partition of the LLM vocabulary. Our analysis identifies the optimal coupling and randomization strategy under the worst-case LLM next-token distribution that satisfies a min-entropy constraint. We provide a closed-form expression of the resulting detection rate under the proposed scheme and quantify the cost in a max-min sense. Finally, we provide an array of numerical results, comparing the proposed scheme with the theoretical optimum and existing schemes, in both synthetic data and LLM watermarking. Our code is available at https://github.com/Carol-Long/CC_Watermark
Soft Best-of-n Sampling for Model Alignment
May 06, 2025
Best-of-$n$ (BoN) sampling is a practical approach for aligning language model outputs with human preferences without expensive fine-tuning. BoN sampling is performed by generating $n$ responses to a prompt and then selecting the sample that maximizes a reward function. BoN yields high reward values in practice at a distortion cost, as measured by the KL-divergence between the sampled and original distribution. This distortion is coarsely controlled by varying the number of samples: larger $n$ yields a higher reward at a higher distortion cost. We introduce Soft Best-of-$n$ sampling, a generalization of BoN that allows for smooth interpolation between the original distribution and reward-maximizing distribution through a temperature parameter $\lambda$. We establish theoretical guarantees showing that Soft Best-of-$n$ sampling converges sharply to the optimal tilted distribution at a rate of $O(1/n)$ in KL and the expected (relative) reward. For sequences of discrete outputs, we analyze an additive reward model that reveals the fundamental limitations of blockwise sampling.
Regretful Decisions under Label Noise
Apr 12, 2025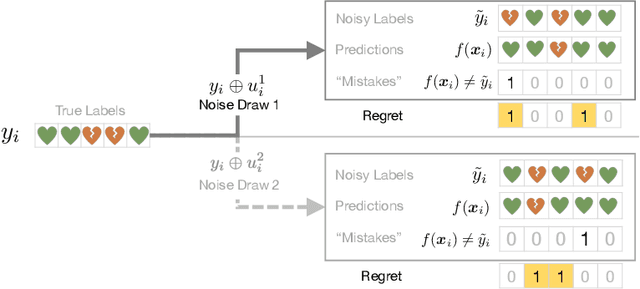


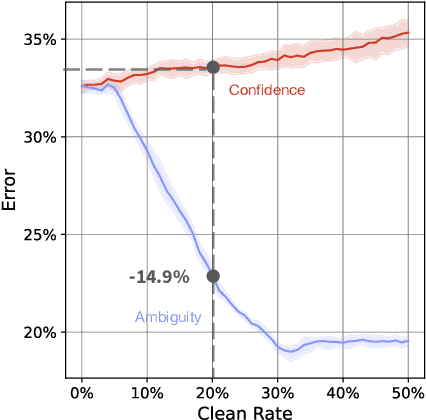
Machine learning models are routinely used to support decisions that affect individuals -- be it to screen a patient for a serious illness or to gauge their response to treatment. In these tasks, we are limited to learning models from datasets with noisy labels. In this paper, we study the instance-level impact of learning under label noise. We introduce a notion of regret for this regime which measures the number of unforeseen mistakes due to noisy labels. We show that standard approaches to learning under label noise can return models that perform well at a population level while subjecting individuals to a lottery of mistakes. We present a versatile approach to estimate the likelihood of mistakes at the individual level from a noisy dataset by training models over plausible realizations of datasets without label noise. This is supported by a comprehensive empirical study of label noise in clinical prediction tasks. Our results reveal how failure to anticipate mistakes can compromise model reliability and adoption, and demonstrate how we can address these challenges by anticipating and avoiding regretful decisions.
Multi-Group Proportional Representation
Jul 11, 2024Image search and retrieval tasks can perpetuate harmful stereotypes, erase cultural identities, and amplify social disparities. Current approaches to mitigate these representational harms balance the number of retrieved items across population groups defined by a small number of (often binary) attributes. However, most existing methods overlook intersectional groups determined by combinations of group attributes, such as gender, race, and ethnicity. We introduce Multi-Group Proportional Representation (MPR), a novel metric that measures representation across intersectional groups. We develop practical methods for estimating MPR, provide theoretical guarantees, and propose optimization algorithms to ensure MPR in retrieval. We demonstrate that existing methods optimizing for equal and proportional representation metrics may fail to promote MPR. Crucially, our work shows that optimizing MPR yields more proportional representation across multiple intersectional groups specified by a rich function class, often with minimal compromise in retrieval accuracy.
Correlated Privacy Mechanisms for Differentially Private Distributed Mean Estimation
Jul 03, 2024Differentially private distributed mean estimation (DP-DME) is a fundamental building block in privacy-preserving federated learning, where a central server estimates the mean of $d$-dimensional vectors held by $n$ users while ensuring $(\epsilon,\delta)$-DP. Local differential privacy (LDP) and distributed DP with secure aggregation (SecAgg) are the most common notions of DP used in DP-DME settings with an untrusted server. LDP provides strong resilience to dropouts, colluding users, and malicious server attacks, but suffers from poor utility. In contrast, SecAgg-based DP-DME achieves an $O(n)$ utility gain over LDP in DME, but requires increased communication and computation overheads and complex multi-round protocols to handle dropouts and malicious attacks. In this work, we propose CorDP-DME, a novel DP-DME mechanism that spans the gap between DME with LDP and distributed DP, offering a favorable balance between utility and resilience to dropout and collusion. CorDP-DME is based on correlated Gaussian noise, ensuring DP without the perfect conditional privacy guarantees of SecAgg-based approaches. We provide an information-theoretic analysis of CorDP-DME, and derive theoretical guarantees for utility under any given privacy parameters and dropout/colluding user thresholds. Our results demonstrate that (anti) correlated Gaussian DP mechanisms can significantly improve utility in mean estimation tasks compared to LDP -- even in adversarial settings -- while maintaining better resilience to dropouts and attacks compared to distributed DP.
Selective Explanations
May 29, 2024Feature attribution methods explain black-box machine learning (ML) models by assigning importance scores to input features. These methods can be computationally expensive for large ML models. To address this challenge, there has been increasing efforts to develop amortized explainers, where a machine learning model is trained to predict feature attribution scores with only one inference. Despite their efficiency, amortized explainers can produce inaccurate predictions and misleading explanations. In this paper, we propose selective explanations, a novel feature attribution method that (i) detects when amortized explainers generate low-quality explanations and (ii) improves these explanations using a technique called explanations with initial guess. Our selective explanation method allows practitioners to specify the fraction of samples that receive explanations with initial guess, offering a principled way to bridge the gap between amortized explainers and their high-quality counterparts.
Algorithmic Arbitrariness in Content Moderation
Feb 26, 2024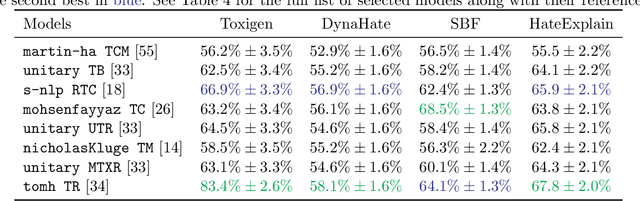
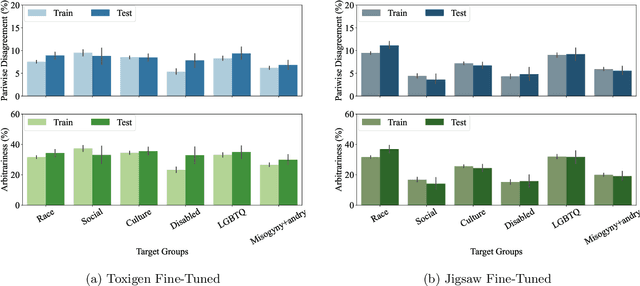

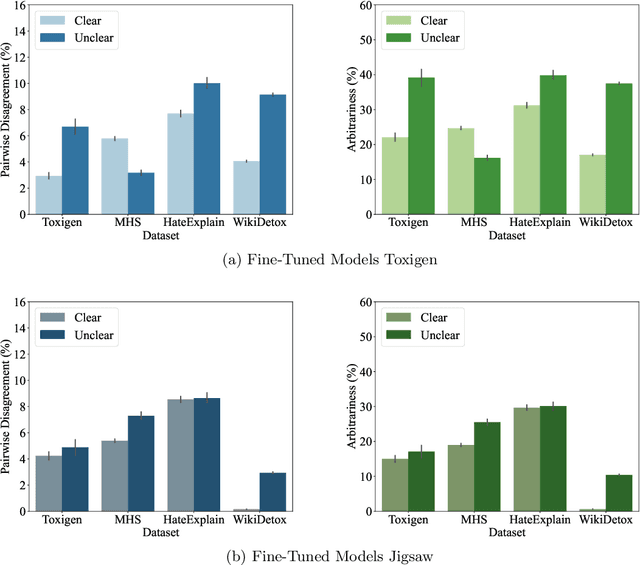
Machine learning (ML) is widely used to moderate online content. Despite its scalability relative to human moderation, the use of ML introduces unique challenges to content moderation. One such challenge is predictive multiplicity: multiple competing models for content classification may perform equally well on average, yet assign conflicting predictions to the same content. This multiplicity can result from seemingly innocuous choices during model development, such as random seed selection for parameter initialization. We experimentally demonstrate how content moderation tools can arbitrarily classify samples as toxic, leading to arbitrary restrictions on speech. We discuss these findings in terms of human rights set out by the International Covenant on Civil and Political Rights (ICCPR), namely freedom of expression, non-discrimination, and procedural justice. We analyze (i) the extent of predictive multiplicity among state-of-the-art LLMs used for detecting toxic content; (ii) the disparate impact of this arbitrariness across social groups; and (iii) how model multiplicity compares to unambiguous human classifications. Our findings indicate that the up-scaled algorithmic moderation risks legitimizing an algorithmic leviathan, where an algorithm disproportionately manages human rights. To mitigate such risks, our study underscores the need to identify and increase the transparency of arbitrariness in content moderation applications. Since algorithmic content moderation is being fueled by pressing social concerns, such as disinformation and hate speech, our discussion on harms raises concerns relevant to policy debates. Our findings also contribute to content moderation and intermediary liability laws being discussed and passed in many countries, such as the Digital Services Act in the European Union, the Online Safety Act in the United Kingdom, and the Fake News Bill in Brazil.